
基于深度学习的医学图像配准综述
点击左上方蓝字关注我们

链接 | https://blog.csdn.net/weixin_41699811/article/details/84314070
作者简介:本文的作者为上海交通大学的研究生,目前研三,正在整理自己三年的研究内容和总结,希望分享出来,让更多对这个领域感兴趣的小伙伴一起加入进来。
作者深知自己刚入门时,无从下手,因此他也希望通过自己的一些努力,帮助到一部分同学,目前作者已经分享很多自己的总结。
B站:https://space.bilibili.com/374628187
分享自己的答辩视频!有兴趣可以去看一下
https://github.com/Timmy-Fang/Deformable-Image-Registration-Projects
GitHub项目也在更新自己的工作成果。
这里仅分享了作者的一篇综述,在CSDN还有其他的优质文章,比如:
1、关于图像配准中的常用损失函数PyTorch实现
2、图像配准中变形操作(warp)的pytorch
作者写的都非常的用心,大家感兴趣的可以去围观
写在前面的话
本人硕士研究生在读,主攻基于深度学习的医学图像处理方向,现在在做基于CNN的二维图像非刚性配准的研究。配准是医学图像处理中常用的基本技术,大量使用在医疗影像领域的各个方面,比如病灶检测,疾病诊断,手术规划,手术导航,疗效评估等。相较于检测、分类与分割任务,医学图像配准任务更加复杂,由于其任务本身的特性,将深度学习技术在自然图像上取得的进展迁移到配准任务上也更难一些,但随着深度学习的学习与研究热潮的高涨,配准领域的研究也因此受益,目前也有一定量的工作发表。前不久我做了相关的文献调研,写了该篇文献综述给导师看,简要总结了近两三年该领域的研究进展与方向,现粘贴如下。因水平有限,还在学习与研究中,难免有不恰当、不准确的地方,欢迎大家批评指正,一起交流学习!
目录
引言
一、配准分类
1、监督学习
2、非监督学习
二、相关问题
三.结论与讨论
参考文献
医学图像配准是医学图像分析中常用的技术,它是将一幅图像(移动图像,Moving)的坐标转换到另一幅图像(固定图像,Fixed)中,使得两幅图像相应位置匹配,得到配准图像(Moved)。传统的配准方法是一个迭代优化的过程,首先定义一个相似性指标(例如,L2范数),通过对参数化转换或非参数化转换进行不断迭代优化,使得配准后的移动图像与固定图像相似性最高。
如今,深度学习在医学图像分析的研究中是比较火热的技术,在器官分割、病灶检测与分类任务中取得了相当好的效果。基于深度学习的医学图像配准方法相较于传统的配准方法,具有很大的优势与潜力,因此有越来越多的研究人员在研究该方法,近几年来有不少相关的工作发表。
本文调查了近两年来的基于深度学习的医学图像配准的文章,首先根据其中使用的深度学习方法进行分类,分别阐述;然后针对不同问题、从不同角度进行分析,比如分块、输入输出、刚体配准、评价指标、与传统方法比较、时间成本比较等;最后是结论与讨论部分。
大体上,近几年的文章可以分为两大类[1] :(1)利用深度学习网络估计两幅图像的相似性度量,驱动迭代优化;(2)直接利用深度回归网络预测转换参数。前者只利用了深度学习进行相似性度量,仍然需要传统配准方法进行迭代优化,没有充分发挥深度学习的优势,花费时间长,难以实现实时配准。因此,本文只针对后者进行研究与讨论,所得结论只限于此类的非刚性配准方法。
根据使用的深度学习的种类划分,可以划分为基于监督学习的配准与基于非监督学习的配准两大类。
1、监督学习
基于监督学习的配准,也就是在训练学习网络时,需要提供与配准对相对应的真实变形场(即Ground Truth)。以二维图像配准为例,监督学习架构如图1所示。通常,先以两幅图像对应坐标为中心点进行切块,将图像块输入深度学习网络(通常为卷积神经网络),网络输出为图像块中心点对应的变形向量(Deformation Vector)。在训练监督学习网络时,需要提供训练样本相应的标签,也即是真实的变形场。获取标签有两种方式,(1)是利用传统的经典配准方法进行配准,得到的变形场作为标签[4] [6] ;(2)是对原始图像进行模拟变形,将原始图像作为固定图像,变形图像作为移动图像,模拟变形场作为标签[2] [10] 。
在测试阶段,对待配准图像对进行采样,输入网络,把预测的变形向量综合成变形场,再利用预测的变形场对移动图像进行插值,即得配准图像。三维图像与之类似。
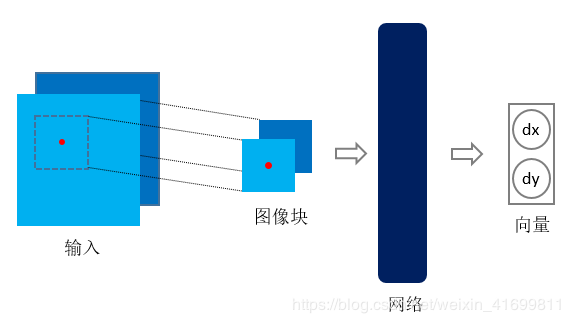
图1、基于监督学习的配准框架
2、非监督学习
相较于监督学习,基于非监督学习的配准方法就是在训练学习网络时,只需要提供配准对,不需要标签(即真实的变形场)。因此,该方法在训练与测试阶段,均不依靠传统的配准方法。以二维图像配准为例,非监督学习框架如图2所示。
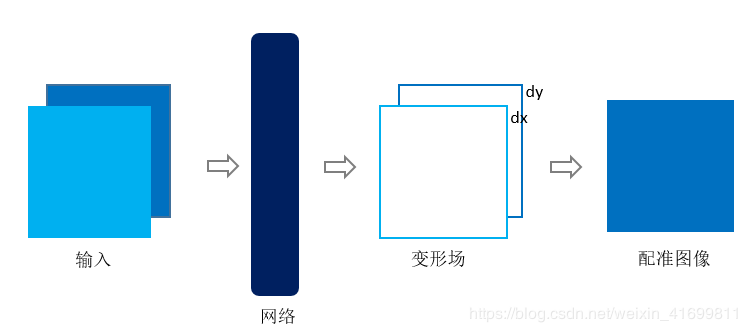
图2、基于非监督学习的配准框架
通常,基于非监督学习的配准[3] [7] [8] [9] ,将配准对输入网络,获得变形场,对移动图像进行变形插值,即得配准图像。三维图像与之类似,将三维图像输入网络,获得变形场(dx,dy,dz),再插值得到配准图像。由于空间转换层[11] (Spatial Transformation Networks,STN)的提出,[7] 首次成功地将其应用到医学图像领域,使得在训练阶段能够实现非监督学习的配准。空间转换层直接连在深度学习网络之后,利用获得的变形场对移动图像进行变形,得到变形后的图像。训练时,利用变形后的图像与固定图像求损失函数值(Loss function),对其进行反向传播,不断优化,使得损失函数值最小。
二、相关问题
为了从不同角度、不同部分对基于深度学习的配准方法进行简要分析与比较,我对参考文献从以下六个方面进行了总结,得到如下结论。
1、分块
分块是指对移动图像与固定图像进行采样,以采样点为块中心点,从图像中截取出来,输入到深度学习网络中。通常基于监督学习的配准方法需要对图像进行分块(如[2] [4] [6] [7] [10]),输入网络,获得块中心点对应的变形向量,而基于非监督学习的方法往往不需要分块(如[3] [8] [9]),[7] 例外。
2、输入输出
大部分的配准网络均将移动图像与固定图像作为两通道图像作为输入(如[2] [3][5] [7] [10]),而基于监督学习的配准网络将其进行分块后输入。[6] 做了进一步的工作,除了输入移动图像块与固定图像块之外,还输入了两图像块卷积得到的相似性图像。[8] 在输入层输入固定图像,而在网络的中间层输入移动图像,这与其设计的独特配准网络有关。[9] 输入网络的是待学习的向量(Latent vector),预测变形场,对移动图像进行变形插值,而只在训练阶段利用固定图像求损失函数值。[4] 将固定图像,移动图像与固定图像的差分图像(Difference map)以及固定图像的梯度图像(Gradient map)作为三通道输入网络。
关于输出,基于监督学习的配准方法往往输出的是变形向量,而基于非监督学习的方法输出的为变形图像。
3、刚体配准
[10] 利用卷积神经网络来学习2D-3D刚体配准的参数。该文章使用人工合成图像作为训练样本,截取图像块,分别输入分支网络,然后整合到主干网络,以监督学习的方式学习转换参数(Transformation parameters)。得到的转换参数为tx、ty、tz、tθ、tα、tβ,分别为x方向平移量、y方向平移量、z方向平移量以及三个旋转量。
4、评价指标
配准效果的评价指标(Evaluation metrics)与使用的数据集有关。大多数文章中使用的数据集,如心脏与脑部图像数据集,均有对应图像的分割标签,因此,大多数使用Dice(如[3][4] [6] [7] [8] [9])作为评价指标。而[2] [5] 使用的是胸部CT数据集,用TRE(Target Registration Error)来评价配准效果。
5、与传统方法比较
多数文章(如[3] [4] [6] [8])使用的作为对比的传统配准方法为SyN、Demons或其变体,如ANTs,LCC-Demons。[2] 使用的是Elastix(一种基于ITK的开源配准工具包),[7] 使用的是SimpleElastix。
6、 时间成本比较
[3] [4] 中对比了传统配准方法与基于深度学习的配准方法的时间成本,以[4] 数据为例,如图3所示,其中D.Demons(Diffeomorphic Demons),SyN与FNIRT为传统方法,BIRNet为文中提出的基于深度学习的方法。从图中可以看出,基于深度学习的配准方法BIRNet处理速度最快,在GPU上运行D.Demons次之,耗时1.1分钟,SyN最慢,耗时9.7分钟。值得注意的是,BIRNet为监督学习方法,输入网络的是采样得到的图像块,而非完整图像。
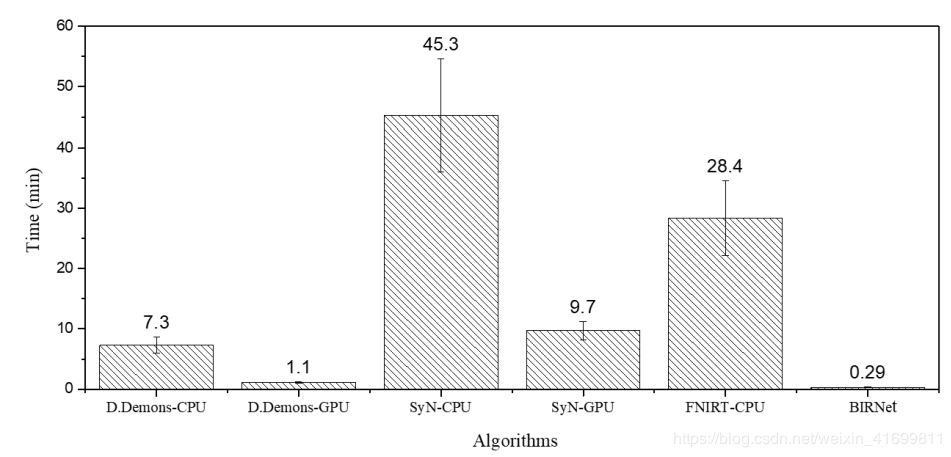
图3、不同配准方法配准一幅220 × 220 × 184脑图像平均计算时长(单位:分钟)。
本文对比了近几年基于深度学习的医学图像配准文章,根据深度学习种类对其分类并简要描述,然后从不同角度对相关问题进行了总结。总体上,对比近期发表的相关文章,可以发现一个趋势,即研究在逐渐从部分依靠深度学习(如利用深度学习网络结果,初始化传统方法优化策略)到完全依靠深度学习(即基于非监督学习的配准方法,学习网络直接获得配准图像)实现配准任务的方向转变,深度学习在配准任务上发挥越来越大的作用与潜能,配准效果与传统经典方法相近,甚至更好。我相信如果妥善解决训练数据集匮乏问题,能更好地发挥基于深度学习的配准方法的优势,实现配准效果更好,速度更快。
END
整理不易,点赞三连↓