
深度强化学习入门介绍
深度强化学习是一种机器学习,其中智能体(Agent,也翻译作代理)通过执行操作(Action)和查看结果(Reward)来学习如何在环境中采取最佳的动作或策略。
自 2013 年Deep Q-Learning 论文[1]以来,强化学习已经有了很多突破。从击败世界上最好 Dota2 玩家的[2]OpenAI到Dexterity [3],我们正处于深度强化学习研究的激动人心的时刻。
此外,由于很多开源库(TF-智能体s, Stable-Baseline 2.0…)和仿真环境的公开:Mine强化学习 (Minecraft), Unity ML-智能体s, OpenAI retro (NES, SNES, Genesis games…)。大家现在可以随时使用仿真游戏环境来测试自己的强化学习程序。
在本课程中,您将通过使用 Tensorflow 和 PyTorch 来训练能玩太空入侵者、Minecraft、星际争霸、刺猬索尼克等游戏的聪明的智能体。
在第一章中,您将学习到深度强化学习的基础知识。在训练深度强化学习智能体之前,掌握这些深度学习的基础知识非常重要。让我们开始吧!
一.什么是强化学习?
为了理解什么是强化学习,让我们从强化学习的核心思想开始。
强化学习的核心思想是,智能体(AI)将通过与环境交互(通过反复试验)并接收奖励(负面或正面)作为执行动作的反馈来从环境中学习。
例如,想象一下你把你的弟弟放在一个他从未玩过的电子游戏面前,手里拿着一个控制器,让他一个人呆着。

游戏场景
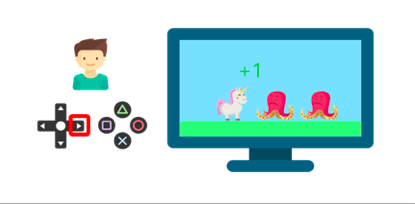
他通过按右键(动作)与环境(视频游戏)互动。得到了一枚硬币,这是+1的奖励。也许在这场比赛中,他只是知道必须得到金币。
当他碰到敌人时,获得-1的惩罚。
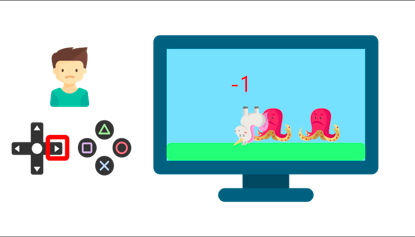
通过反复试验与他的环境互动,你的弟弟才明白,在这个环境中,他需要获得金币,但要避开敌人。
在没有任何监督的情况下,孩子会越来越擅长玩游戏。
这就是人类和动物通过互动学习的方式。强化学习就是一种从行动中学习的最优解的方法。
1、正式定义
我们现在给出强化学习的一个正式的定义:
强化学习是一种通过构建智能体来解决控制任务(也称为决策问题)的框架。智能体通过与环境互动、反复试验和领取奖励来制定自己的策略。
但是强化学习是如何工作的呢?
二.强化学习框架
强化学习过程
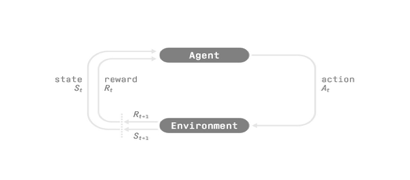
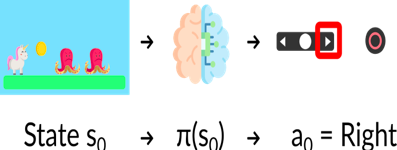
为了理解 强化学习 过程,让我们想象一个智能体学习玩平台游戏:
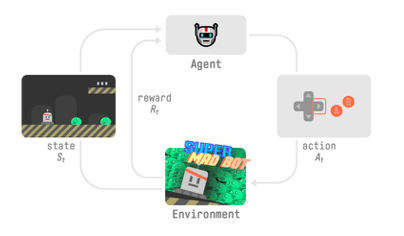
我们的智能体从环境接收状态 S0——我们接收游戏的第一帧(环境)。 基于状态 S0,智能体采取行动 A0——我们的智能体将向右移动。 环境转换到新状态 S1 — 新框架。 环境给了智能体一些奖励 R1——我们没有死*(Positive Reward +1)*。
这个强化学习循环输出状态、动作和奖励以及下一个状态的序列。
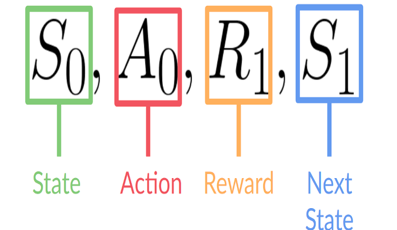
状态、动作、奖励、下一个状态
2、预期回报
智能体的目标是最大化累积奖励,称为预期回报,为什么智能体的目标是最大化预期回报?
因为强化学习是基于奖励假设,即所有目标都可以描述为预期回报(预期累积奖励)的最大化。这就是为什么在强化学习中,为了获得最佳行为,我们需要最大化预期累积奖励。
3、观察/状态空间
观察/状态是我们的智能体从环境中获得的信息。在视频游戏的情况下,它可以是一张截图,在交易智能体的情况下,它可以是某只股票的价值等。
观察和状态之间有一个区别:
State s:是对环境状态的完整描述(没有隐藏信息)。在完全观察的环境中。

对于国际象棋游戏,我们处于完全观察的环境中,因为我们可以访问整个棋盘信息。
观察 o:是状态的部分描述。在部分观察的环境中。

在《超级马里奥兄弟》中,我们只能看到靠近玩家的关卡的一部分,因此我们收到了观察结果。
在《超级马里奥兄弟》中,我们只是处于一个部分观察的环境中,我们收到了一个观察结果,因为我们只看到了关卡的一部分。
4、行动空间
动作空间是环境中所有可能动作的集合。动作可以来自离散或连续空间:
离散空间:可能动作的数量是有限的。

在《超级马里奥兄弟》中,我们有一组有限的动作,因为我们只有 4 个方向和跳跃。
连续空间:可能的动作数量是无限的。
自动驾驶汽车智能体有无数种可能的动作,因为他可以左转 20°、21°、22°、鸣喇叭、右转 20°、20,1°……

考虑这些信息是至关重要的,因为它在我们将来选择强化学习 算法时很重要。
5、奖励和折扣因子
奖励是强化学习的基础,因为它是智能体和环境交互后的唯一反馈。有了它,我们的智能体才知道所采取的行动是否足够好。
每个时间步长 t 的累积奖励可以写成:
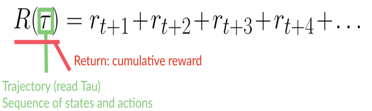
等式还可以写成:
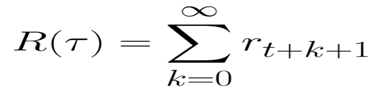
但实际上,我们不能就这样简单累加奖励。在游戏开始时出现的奖励更有可能发生,因为它们比未来的奖励更可预测。
假设您的智能体是这只小老鼠,它可以在每个时间步移动一步,而您的对手是猫(它也可以移动)。你的目标是在被猫吃掉之前吃掉最大量的奶酪。
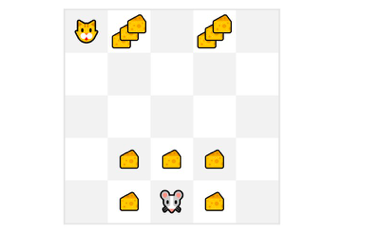
因此,靠近猫的奖励,即使它更大(更多的奶酪),该奖励的风险也会更大,因为我们不确定我们能否吃到它。为了计算这部分奖励,我们定义了折扣奖励。
为了计算折扣奖励,我们是这样进行的:
1、定义一个称为 的γ 的折扣银子。它必须介于 0 和 1 之间。
γ越大,折扣越小。这意味着我们的智能体更关心长期奖励。另一方面,γ越小,折扣越大。这意味着我们的智能体更关心短期奖励(最近的奶酪)。
2、每个奖励将通过 γ 折现为时间步长的指数
随着时间步长的增加,猫离我们越来越近,所以未来的奖励发生的可能性越来越小。
我们的折扣累积预期奖励是:
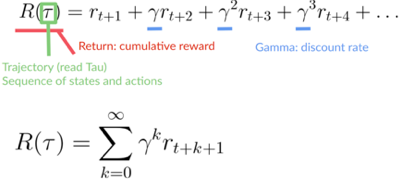
折扣累积预期奖励
6、任务类型
任务是强化学习问题的一个实例。我们可以有两种类型的任务:离散的和连续的。
离散任务,在这种情况下,我们有一个起点和一个终点(终止状态)。这将创建一个序列:状态、操作、奖励和新状态。
例如,在《超级马里奥兄弟》游戏中,这个序列从新马里奥关卡开始,并马里奥被杀或到达关卡终点时结束。

连续任务,这些是永远持续的任务(没有终止状态)。在这种情况下,智能体必须学习如何选择最佳动作并随时与环境交互。
例如,进行自动股票交易的智能体。对于这个任务,没有起点和终点。智能体一直运行,直到我们决定关闭它。
7、探索/利用权衡
最后,在研究强化学习解决问题的不同方法之前,我们必须讨论一个非常重要的点:探索/利用。
探索是通过尝试随机动作来探索环境,以找到有关环境的更多信息。利用是根据已知的信息来最大化奖励。
我们强化学习智能体的目标是最大化预期累积奖励。然而,我们可能会陷入一个陷阱。

在这个游戏中,我们的老鼠可以拥有无限量的小奶酪(每个+1)。但是在迷宫的顶部,有一堆大奶酪(+1000)。
如果我们只专注于利用,我们的智能体永远到不了大奶酪那里(探索)。它只会获取最近的奖励,即使这个奖励很小(利用)。
但是如果我们的智能体做一点探索,它可以发现更大的奖励(一堆大奶酪)。
这就是我们所说的探索/利用的权衡。我们需要平衡对环境的探索程度和对环境的了解程度。
因此,我们必须定义一个规则来处理这种情况。我们将在以后的章节中看到不同的处理方式。如果这个问题令人困惑,请考虑一个真正的问题:餐厅的选择。
利用:每天都去同一家您认为不错的餐厅,并冒着错过另一家更好餐厅的风险。
探索:尝试以前从未去过的餐厅,冒着体验不好的风险,但可能有机会获得美妙的体验。
三、解决强化学习问题的两种主要方法
既然我们学习了强化学习框架,那么我们如何解决强化学习问题呢?换句话说,如何构建一个可以选择最大化其预期累积奖励的动作的强化学习智能体?
1、策略π:智能体的大脑
策略π是我们智能体的大脑,它是告诉我们在给定状态下要采取什么行动的函数。所以它定义了在给定一段时间内的智能体行为。
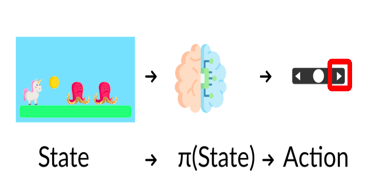
状态、策略、动作
将策略视为我们智能体的大脑,该功能将告诉我们在给定状态下采取的行动,这个策略π就是我们要学习的函数,我们的目标是找到最优策略π*,当智能体按照它行动时,是期望收益最大化的策略。我们通过训练找到了这个π*。
有两种方法可以训练我们的智能体来找到这个最优策略π*:
直接地,基于策略的方法:通过教智能体学习在给定状态下要采取的行动。 间接地,基于价值的方法:教智能体了解哪个状态更有价值,然后采取会出现更有价值状态的行动。
2、基于策略的方法
在基于策略的方法中,我们直接学习策略函数。该函数将从每个状态映射到该状态的最佳对应动作,或者该状态下一组可能动作的概率分布。
正如我们在这里看到的,策略(确定性的)直接指示每一步要采取的行动。
我们有两种类型的策略:
确定地:在给定状态下该策略将始终返回相同的操作。
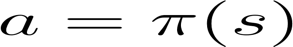
给定状态下输出动作
随机地:在给定状态下该该策略输出动作的概率分布。

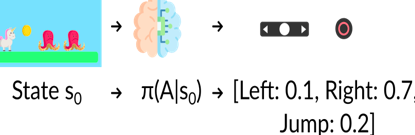
给定一个初始状态,随机策略将输出该状态下可能动作的概率分布
3、基于价值的方法
在基于价值的方法中,我们不是训练策略函数,而是训练一个将状态映射到处于该状态的预期值的值函数。
一个状态的价值是如果智能体从该状态开始,根据我们的策略采取行动,它可以获得的最大的折扣累积预期奖励。
“按照我们的策略行事”意味着我们的策略是“走向价值最高的”。
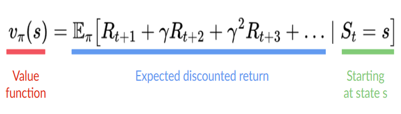
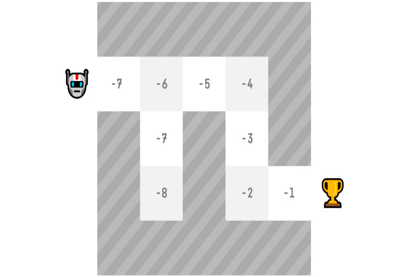
有了我们的价值函数,在每一步,我们的策略都会选择价值函数定义的具有最大价值的状态:-7,然后是-6,然后是-5(等等)来实现目标。
四、强化学习的“深度”
谈到了强化学习,但我们为什么要谈论深度强化学习?深度强化学习引入了深度神经网络来解决强化学习问题——因此得名“深度”。
例如,在下一篇文章中,我们将研究 Q-Learning(经典强化学习)和 Deep Q-Learning,两者都是基于价值的强化学习算法。
您会看到不同之处在于,在第一种方法中,我们使用传统算法来创建 Q 表,以帮助我们找到对每个状态要采取的操作。
在第二种方法中,我们将使用神经网络(来近似 q 值)。
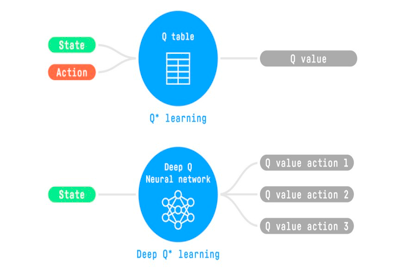
Q-Learning和 Deep Q-Learning
五、总结
我们总结一下今天学到的知识:
强化学习是一种从行动中学习的计算方法。我们构建了一个智能体,它通过反复试验与环境交互并接收奖励(负面或正面)作为反馈,从环境中学习到动作的好坏。
任何强化学习智能体的目标都是最大化其预期累积奖励(也称为预期回报),因为强化学习基于奖励假设,所有目标都可以描述为预期累积奖励的最大化。
强化学习过程是一个循环,可以定义为:状态、动作、奖励和下一个状态的序列。
为了计算预期累积奖励(预期回报),我们对奖励打折:较早(在游戏开始时)出现的奖励更有可能发生,因为它们比长期未来奖励更可预测。
要解决强化学习问题,需要找到最佳策略,策略是智能体的“大脑”,它会告诉我们在给定状态下要采取什么行动。最佳的一种策略能提供最大化预期回报的行动。
有两种方法可以找到最佳策略:
通过直接训练的策略:基于策略的方法。
通过训练一个价值函数,告诉我们智能体在每个状态下将获得的预期回报,并使用这个函数来定义我们的策略:基于价值的方法。
最后,我们谈论深度强化学习,因为我们引入了深度神经网络来估计要采取的动作(基于策略)或估计状态的值(基于值),因此称为“深度”。
参考资料
[1]Deep Q-Learning 论文:
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
[2]击败世界上最好 Dota2 玩家的:
https://www.twitch.tv/videos/293517383
[3]Dexterity :
https://openai.com/blog/learning-dexterity/
[4]打败了世界上最好的 Dota2 玩家:
https://www.twitch.tv/videos/293517383
原文链接:
https://thomassimonini.medium.com/an-introduction-to-deep-reinforcement-learning-17a565999c0c
- EOF -
往期精彩回顾 本站qq群851320808,加入微信群请扫码: