
模型试验 | Python 实现注意力机制

作者 | 李秋键
来源 | AI科技大本营
编辑 | 极市平台
极市导读
是否能够从新的方向去获取特征图更丰富的注意力信息,或者以新的方式或手段去获取更精准的注意力信息也是未来需要关注的一个重点。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
随着信息技术的发展,海量繁杂的信息向人们不断袭来,信息无时无刻充斥在四周。然而人类所能接收的信息则是有限的,科研人员发现人类视觉系统在有限的视野之下却有着庞大的视觉信息处理能力。
在处理视觉数据的初期,人类视觉系统会迅速将注意力集中在场景中的重要区域上,这一选择性感知机制极大地减少了人类视觉系统处理数据的数量,从而使人类在处理复杂的视觉信息时能够抑制不重要的刺激,并将有限的神经计算资源分配给场景中的关键部分,为更高层次的感知推理和更复杂的视觉处理任务(如物体识别、场景分类、视频理解等)提供更易于处理且更相关的信息。
借鉴人类视觉系统的这一特点,科研人员提出了注意力机制的思想。对于事物来说特征的重要性是不同的,反映在卷积网络中即每张特征图的重要性是具有差异性的。
注意力机制的核心思想是通过一定手段获取到每张特征图重要性的差异,将神经网络的计算资源更多地投入更重要的任务当中,并利用任务结果反向指导特征图的权重更新,从而高效快速地完成相应任务。
近两年,注意力模型被广泛使用在自然语言处理、图像识别、语音识别等各种不同类型的深度学习任务当中。
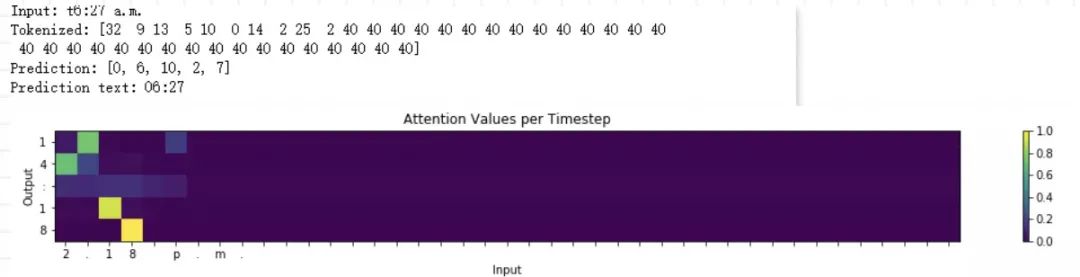
如下图所示,颜色越深的地方表示关注度越大,即注意力的权重越大。

故本项目将通过搭建 BiLSTM 的注意力机制模型来实现对时间数据的格式转换,实现的最终结果如下:
注意力机制介绍
注意力机制最初在2014年作为RNN中编码器-解码器框架的一部分来编码长的输入语句,后续被广泛运用在RNN中。例如在机器翻译中通常是用一个 RNN编码器读入上下文,得到一个上下文向量,一个RNN解码器以这个隐状态为起始状态,依次生成目标的每一个单词。但这种做法的缺点是:无论之前的上下文有多长,包含多少信息量,最终都要被压缩成一个几百维的向量。
这意味着上下文越大,最终的状态向量会丢失越多的信息。输入语句长度增加后,最终解码器翻译的结果会显著变差。
事实上,因为上下文在输入时已知,一个模型完全可以在解码的过程中利用上下文的全部信息,而不仅仅是最后一个状态的信息,这就是注意力机制的基础思想。
1.1基本方法介绍
当前注意力机制的主流方法是将特征图中的潜在注意力信息进行深度挖掘,最常见的是通过各种手段获取各个特征图通道间的通道注意力信息与特征图内部像素点之间的空间注意力信息,获取的方法也包括但不仅限于卷积操作,矩阵操作构建相关性矩阵等,其共同的目的是更深层次,更全面的获取特征图中完善的注意力信息,于是如何更深的挖掘,从哪里去挖掘特征图的注意力信息,将极有可能会成为未来注意力方法发展的方向之一。
目前,获取注意力的方法基本基于通道间的注意力信息、空间像素点之间的注意力信息和卷积核选择的注意力信息,是否能够从新的方向去获取特征图更丰富的注意力信息,或者以新的方式或手段去获取更精准的注意力信息也是未来需要关注的一个重点。
模型实验
2.1 数据处理
读取数据集json文件,并将每一个索引转换为对应的one-hot编码形式,并设置输入数据最大长度为41。代码如下:
with open('data/Time Dataset.json','r') as f: dataset = json.loads(f.read())with open('data/Time Vocabs.json','r') as f: human_vocab, machine_vocab = json.loads(f.read())human_vocab_size = len(human_vocab)machine_vocab_size = len(machine_vocab)m = len(dataset)def preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty): m = len(dataset) X = np.zeros([m, Tx], dtype='int32') Y = np.zeros([m, Ty], dtype='int32') for i in range(m): data = dataset[i] X[i] = np.array(tokenize(data[0], human_vocab, Tx)) Y[i] = np.array(tokenize(data[1], machine_vocab, Ty)) Xoh = oh_2d(X, len(human_vocab)) Yoh = oh_2d(Y, len(machine_vocab)) return (X, Y, Xoh, Yoh)
2.2 网络模型设置
其中Tx=41为序列的最大长度,Ty=5为序列长度,layer1 size设置为32为网络层,1ayer2 size=64为注意力层,human vocab size=41表述human时间会用到41个不同的字符,machine vocab size=11表述machine时间会用到11个不同的字符。这里双向LSTM作为Encoder编码器,全连接层作为Decoder解码器。
代码如下:
layer3 = Dense(machine_vocab_size, activation=softmax)def get_model(Tx, Ty, layer1_size, layer2_size, x_vocab_size, y_vocab_size): X = Input(shape=(Tx, x_vocab_size)) a1 = Bidirectional(LSTM(layer1_size, return_sequences=True), merge_mode='concat')(X) a2 = attention_layer(a1, layer2_size, Ty) a3 = [layer3(timestep) for timestep in a2] model = Model(inputs=[X], outputs=a3) return model如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
