论文原文:Spatial Transformer Networks
这是一篇过时的文章,读者不必了解太多,但它的主要思想却值得写一下。

如上图所示,图像中的一些目标可能存在各种各样的角度,姿态,为了提高模型的泛化能力和鲁棒性,我们希望模型能对各种姿态,扭曲变形的目标,都能有较好的识别检测能力。因此,论文提出了对输入图像进行空间变换(spatial transformer),通过spatial transformer将其在空间上“摆正位置”。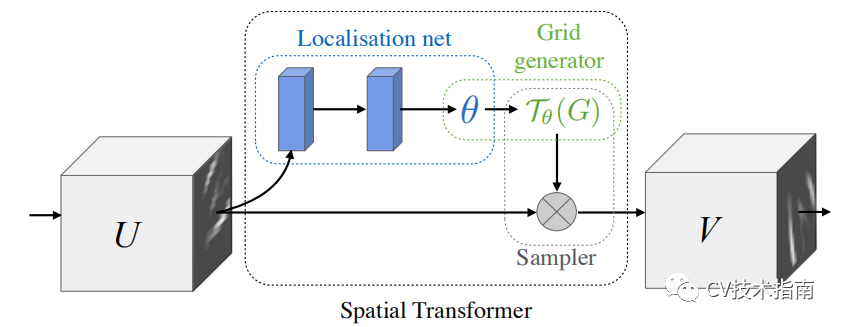
具体做法如上图所示,类似于SE和CBAM,在网络中间加一个分支,作为空间转换器。关于这个转换器这里不多介绍,了解本文的主要思想即可。
OPAM(2017)
论文:Object-Part Attention Model for Fine-grained Image Classifification
这篇论文同样值得一写的是它的主要思想,其主要内容并没有值得去看的地方。主要思想:对于细粒度图像分类来说,一个大类别下存在几百个小类别,而区分这些小类别的关键,在于目标身上的特征,例如识别数百种鸟类,此时背景信息对于区分不同类型的鸟类基本没有帮助。为了让模型更加关注到目标所在的区域,对于图像中背景的地方,通过一个图像分类模型,生成saliency map。通过saliency map定位到目标所在的区域,裁剪,重新进入一个新的part-level Attention Model进行识别分类。
Residual Attention(2017)
论文:Residual Attention Network for Image Classifification
论文提出了残差注意力网络,这是一种在“非常深”的结构中采用混合注意力机制的卷积网络。残差注意力网络由多个注意力模块组成,这些模块会产生注意力感知功能。如下图所示,随着模块的深入,来自不同模块的注意力感知功能会自适应地变化。
注意力模块如下图所示:

注意力模块由两条分支组成,一个是Soft Mask Branch,一个是Trunk Branch。Trunk Branch是正常卷积结构,Soft Mask Branch是先经过两次max pooling,以便迅速获得更大的感受野,再通过双线性插值,回到input feature map的大小,再经过两次1x1卷积,以及sigmoid归一化。再与Trunk Branch进行融合。融合的方式若是直接相乘,由于Soft Mask Branch的范围是(0,1],在经过多个堆叠的注意力模块后,feature maps由于多次乘以Soft Mask的值会变得极小,模型的性能会明显下降。因此提出Attention Residual learning来进行融合。具体的融合方式如下图所示,即增加了残差连接。记住红色框的内容,后面会经常出现。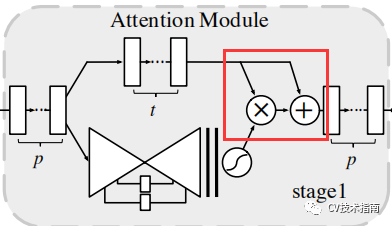
BAM(2018)
论文:BAM: Bottleneck Attention Module
具体结构如下图所示。细节内容就不多赘述了,读者看图更能理解,只介绍一个大概:利用了空洞卷积来获取更大的感受野,增加了通道注意力,方式是在feature map上全局平均池化,再降维升维,如右下角所示使用了上面那篇论文中的Attention Residual learning方式来融合。

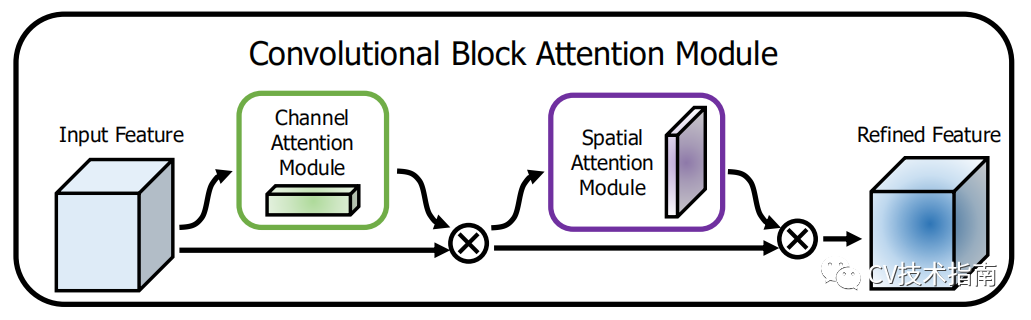
CBAM(2018)
论文:CBAM: Convolutional Block Attention Module
CBAM同样是使用空间注意力和通道注意力,不过与BAM不同的是,通道注意力并不是像BAM那样融合在空间注意力内再做归一化,而是先后分开进行。
通道注意力的生成方式:先在feature maps上进行全局最大池化和全局平均池化得到两个1维向量,再经过共享的MLP层,再进行相加,sigmoid归一化。
空间注意力的生成方式:在通道上进行最大池化和平均池化,得到两个feature map,经过7x7卷积,得到一个feature map,再BN,sigmoid归一化。
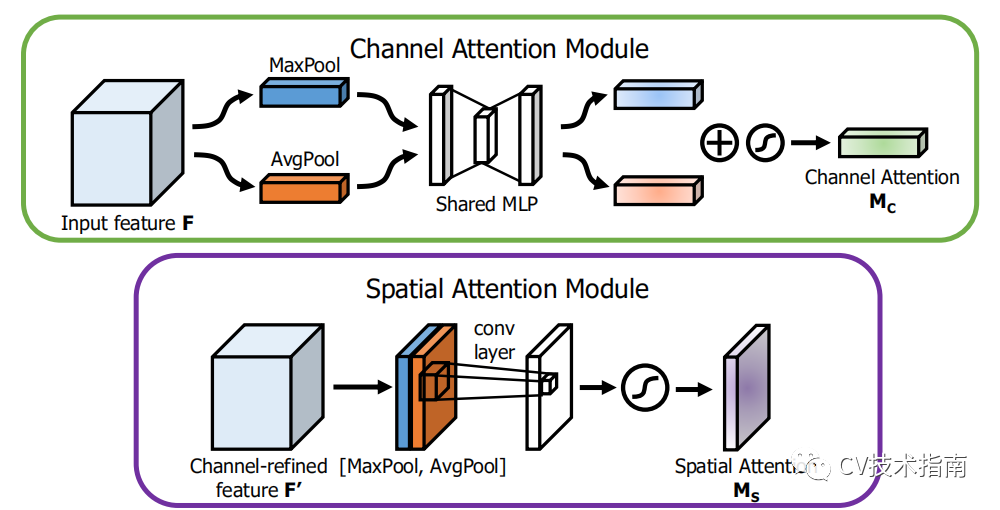
注:这种空间注意力只考虑了局部的信息,在后面CVPR2021的Coordinate Attention中有所改进。
Non-Local(2018)
论文:Non-local Neural Networks
卷积操作在每一层获得的感受野十分有限,对于一些长距离的依赖,需要堆叠很多层卷积才能获得,为此,作者提出了Non-Local Block,这种结构使得网络可以直接获得两个位置之间的依赖关系,而不用考虑距离。具体结构图如下所示:(由于这个模型本是用于时空模型中,因此下方的结构图中包含了时间维度,去掉T便可用于图像)
这种方式来源于transformer,先通过3个不同的1维卷积降维,再各自reshape为HW x512,前两者通过点积进行相似性计算,再归一化作为第三者的加权系数。最后使用1x1卷积升维和残差连接。这种方式的最大缺点在于进行HW与HW做相似性计算,计算量是H的四次方,因此论文中提出当H=14或7时才使用。后面在GCNet和CCnet中会有所简化并改进。
PAN(2018)
论文:Pyramid Attention Network for Semantic Segmentation
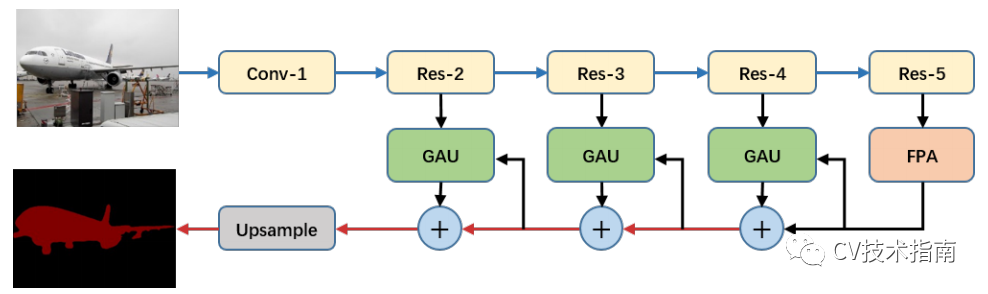
该论文针对语义分割引入像素级注意力。主要由两个部分组成:Feature Pyramid Attention (FPA) 和Global Attention Upsample module (GAU)。FPA在空间金字塔池化的基础上调整而来,与空间金字塔池化不同的是,FPA通过不同大小的卷积来构建金字塔,并在此基础上引入了通道注意力。 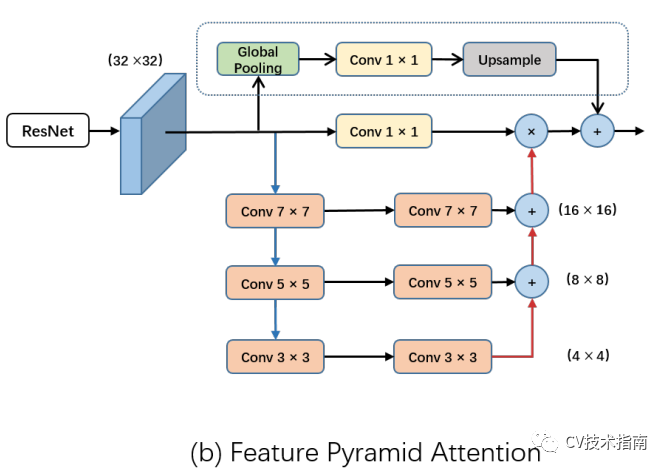
GAU通过全局池化提供的全局信息作为指引选择low-level特征,这是因为high-level中有着丰富的语义信息,这可以帮助引导low-level的选择,从而达到选择更为精准的分辨率信息。
Squeeze-and-Excitation(2018)
论文:Squeeze-and-Excitation Networks
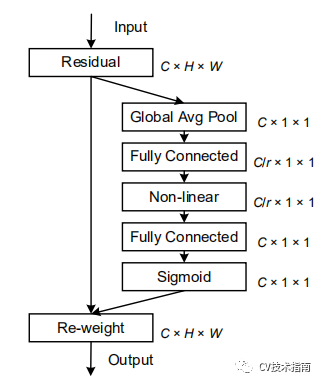
这个不仅使用简单,对笔者来写这个也简单,先贴出论文中的结构图,再用Coordinate Attention中的一个结构图作为对论文中结构图的解释。

其描述如下:
CCNet(2019)
论文:CCNet: Criss-Cross Attention for Semantic Segmentation
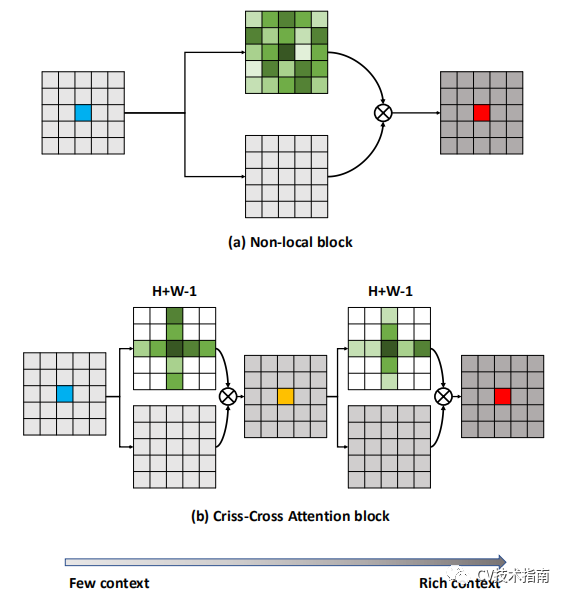
论文的主要思想在于从Non-Local的每个都与其它所有位置进行相似性计算变为只计算同一行和同一列的相似性。这样极大地节省了计算量。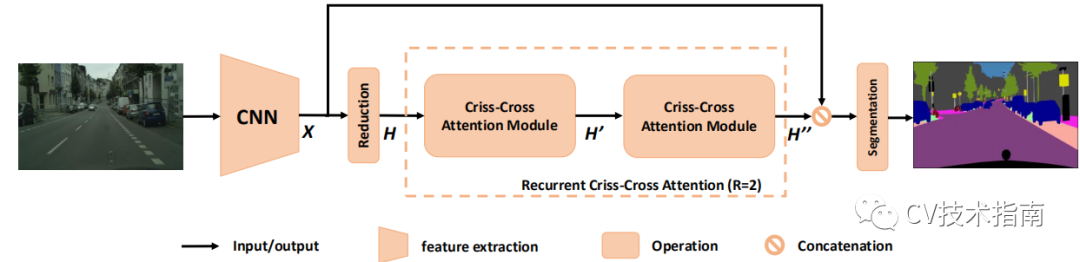
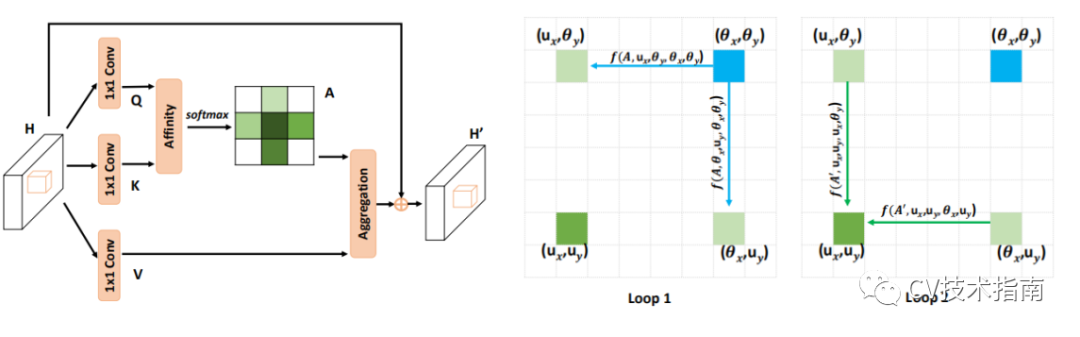
其中Criss-Cross Attention Module如下左图所示,对于两次loop的示意图如下右图所示,经过两次loop,可获取到任意两个位置的依赖关系
GCNet(2019)
论文:GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
如题所示,GCNet是在将Non-Local简化后与Squeeze-Excitation结合。
如下图所示:作者发现在query的不同点(图中的红点),计算出来的attention map是一样的。

这就说明只需要计算一个点就可以了,其它位置的计算都是多余的,这样做的好处就是计算量极大减少。
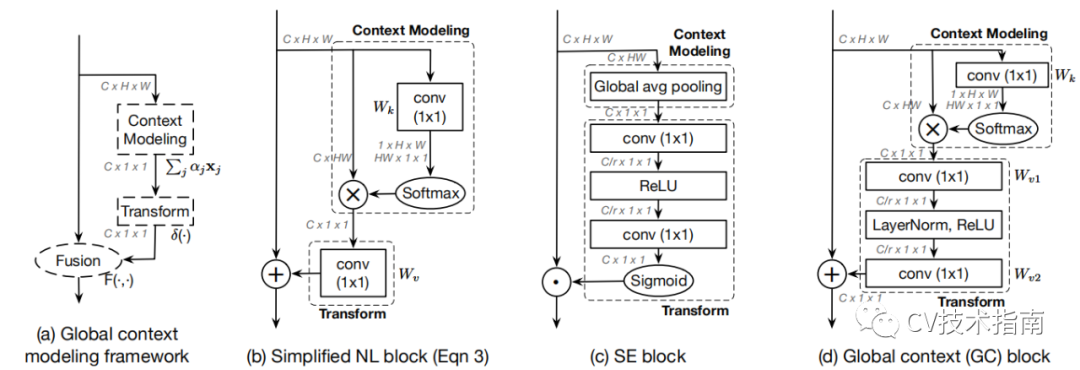
GCNet的整体框架如图a所示,简化版的Non-Local如图b所示,GCNet具体结构如图d所示。GCNet将SE中的全局平均池化用简化版的Non-Local来代替,而SE下方的结构用了Bottleneck来进行transform。这里使用Bottleneck是为了减少参数量,其中r取16。
DANet(2019)
论文:Dual Attention Network for Scene Segmentation
论文提出了双注意力网络,由位置注意力模块(Position Attention Module)和通道注意力模块(Channel Attention Module)组成。

Position Attention Module和Channel Attention Module的结构图如下所示:这两个模块没什么细节的地方值得讲的,看个图就足以理解。

Coordinate Attention(2021)
论文:Coordinate Attention for Effificient Mobile Network Design
这篇论文基于SE和CBAM改进而来,作者认为SE没有考虑空间信息,CBAM通过对每个位置的通道上进行池化,由于经过几层卷积和降采样后的feature maps的每个位置只包含原图的一个局部区域,因此这种做法只考虑了局部区域信息。为此,作者提出了一种新的attention机制--Coordinate Attention。
Coordinate Attention利用两个1D全局池化操作将沿垂直和水平方向的input features分别聚合为两个单独的direction-aware feature maps。 然后将具有嵌入的特定方向信息的这两个特征图分别编码为两个attention map,每个attention map都沿一个空间方向捕获输入特征图的远距离依存关系。 位置信息因此可以被保存在所生成的attention map中。 然后通过乘法将两个attention map都应用于input feature maps,以强调注意区域的表示。
具体结构如图c所示,简单说来,Coordinate Attention是通过在水平方向和垂直方向上进行平均池化,再进行transform对空间信息编码,最后把空间信息通过在通道上加权的方式融合。
总结:本文介绍了一些注意力模块,虽然文字描述的比较少,但给出的结构图足以理解其主要操作。除了以上的内容,此外还包括强注意力,但不是特别常见,本文未对其进行总结。
参考论文
1. Spatial Transformer Networks
2. Object-Part Attention Model for Fine-grained Image Classifification
3. Residual Attention Network for Image Classifification
4. BAM: Bottleneck Attention Module
5. CBAM: Convolutional Block Attention Module
6. Non-local Neural Networks
7. Pyramid Attention Network for Semantic Segmentation
8. Squeeze-and-Excitation Networks
9. CCNet: Criss-Cross Attention for Semantic Segmentation
10. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
11. Dual Attention Network for Scene Segmentation
12. Coordinate Attention for Effificient Mobile Network Design
✄------------------------------------------------
双一流高校研究生团队创建,专注于计算机视觉原创并分享相关知识☞
闻道有先后,术业有专攻,如是而已╮(╯_╰)╭
