
注意力机制
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

注意力机制潜在的是一个很有用的方法,本期我们来了解一下注意力机制背后的原理的和方法吧。
原文是英文来自于 https://blog.heuritech.com/2016/01/20/attention-mechanism/
随着深度学习和人工智能的发展,许多研究人员对神经网络中的“注意力机制”感兴趣。本文旨在对深度学习注意力机制的内容进行高层次的解释,并且详细说明计算注意力的一些技术步骤。如果您需要更多的技术细节,请参考英文,特别是Cho等人最近的综述[3]。不幸的是,这些模型并不总是直接就能凭借自己实现,而且到目前为止只有一些开源代码发布了出来。
神经科学和计算神经科学[1,2]已经广泛研究了涉及注意力的神经过程[1,2]。特别是视觉注意力机制:许多动物关注其视觉输入的特定部分以计算适当的反应。这个原则对神经计算有很大的影响,因为我们需要选择最相关的信息,而不是使用所有可用的信息。在输入中,很大一部分与计算神经反应无关。
类似的想法 :“专注于输入的特定部分 ” 已经应用于深度学习中,用于语音识别,翻译,推理和对象的视觉识别。
让我们举一个例子来解释注意机制。我们想要实现的任务是图像标注:我们想要为给定图像生成字幕。
“经典”图像字幕系统将使用预先训练的卷积神经网络对图像进行编码,该网络将产生隐藏状态h。然后,它将通过使用递归神经网络(RNN)解码该隐藏状态,并递归地生成字幕的每个字。这种方法已经被几个小组应用,包括[11](见下图):

这种方法的问题在于,当模型试图生成标题的下一个单词时,该单词通常只描述图像的一部分。使用图像h的整个表示来调节每个单词的生成不能有效地为图像的不同部分产生不同的单词。这正是注意机制有用的地方。
利用注意力机制,图像首先被分成n个部分,并且我们使用每个部分h_1,...,h_n的卷积神经网络(CNN)表示来计算。当RNN生成新单词时,注意力机制关注于图像的相关部分,因此解码器仅使用图像的特定部分。
在下图(上排)中,我们可以看到标题的每个单词用于生成图像的哪个部分(白色)。


我们现在将在解释注意力模型的一般工作原理。对注意力模型应用的综述文章[3] 详述了基于注意力的编码器 - 解码器网络的实现,需要更多细节知识的可以参考。
注意力机制的细致解释:注意力模型是一种采用n个参数y_1,...,y_n(在前面的例子中,y_i将是h_i)和上下文c的方法。它返回一个矢量z,它应该是y_i的“摘要”,侧重于与上下文c相关的信息。更正式地,它返回y_i的加权算术平均值,并且根据给定上下文c的每个y_i的相关性来选择权重。

在前面给出的例子中,上下文是生成句子的开头,y_i是图像部分的表示(h_i),输出是过滤图像的表示,过滤器放置了焦点。当前生成的单词的有趣部分。
注意力模型的一个有趣特征是算术平均值的权重是可访问的并且可以绘制。这正是我们之前显示的数字,如果此图像的重量很高,则像素更白。
但这个黑匣子到底在做什么呢?整个注意力模型的数字将是这样的:

这个网络似乎很复杂,但我们将逐步解释它。
首先,我们认识到输入。c是上下文,y_i是我们正在查看的“数据的一部分”。
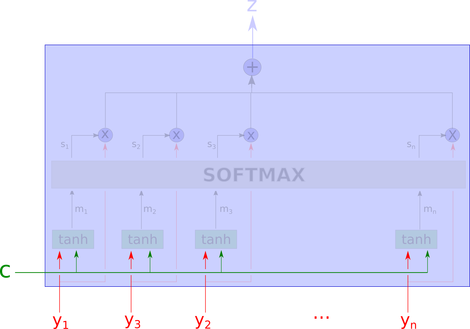
在下一步,网络使用tanh层计算m_1,... m_n。这意味着我们计算y_i和c的值的“聚合”。这里一个重要的注意事项是,每个m_i的计算都没有查看j 不等于 i的其他y_j。它们是独立计算的。
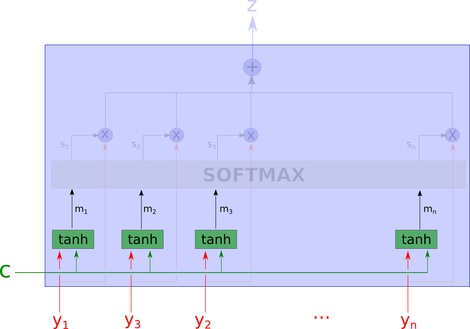

然后我们将m_1, m_2,..m_n 传递到后面一层,计算softmax, softmax通常用于分类器的最后一层设置。

这里,s_i是在学习方向上投影的m_i的softmax。因此,根据上下文,softmax可以被认为是变量的“相关性”的最大值。
输出z是所有y_i的加权算术平均值,其中权重表示根据上下文c的每个变量的相关性。
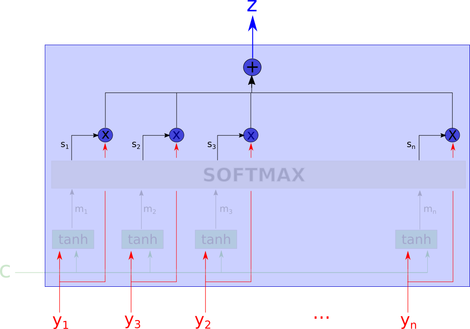

请注意以上我们实现的是“soft-attention”, 它是一种完全可区分的确定性机制,可插入现有系统,并且梯度通过注意机制传播,同时它们通过网络的其余部分传播。

回到图像标注:我们可以识别出用于图像字幕的“经典”模型的图形,但是有了一层新的注意力模型。当我们想要预测标题的新单词时会发生什么?如果我们预测了i个单词,LSTM的隐藏状态是h_i。我们使用h_i作为上下文选择图像的“相关”部分。然后,注意模型z_i的输出被用作LSTM的输入,该输出是被过滤的图像的表示,其仅保留图像的相关部分。然后,LSTM预测一个新单词,并返回一个新的隐藏状态h_ {i + 1}。

没有RNN的Attention:到目前为止,我们仅在编码器 - 解码器框架(即具有RNN)中描述了注意力模型。但是,当输入顺序无关紧要时,可以考虑独立的隐藏状态h_j。例如在Raffel等[10]中就是这种情况,其中注意力模型是完全前馈的。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~