注意力模型(AM)最初被用于机器翻译,现在已成为神经网络领域的一个重要概念。在人工智能(Artificial Intelligence,AI)领域,注意力已成为神经网络结构的重要组成部分,并在自然语言处理、统计学习、语音和计算机等领域有着大量的应用。 01
注意力机制(Attention Mechanism)浅谈 早期在解决机器翻译这一类序列到序列(Sequence to Sequence)的问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题,拿机器翻译举例: 问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。 问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。 同样在计算机视觉领域,如果输入的图像尺寸很大,做图像分类或者识别时,模型的性能就会下降。 注意力机制早在上世纪九十年代就有研究,到2014年Volodymyr的《Recurrent Models of Visual Attention》一文中将其应用在视觉领域,后来伴随着2017年Ashish Vaswani的《Attention is all you need》中Transformer结构的提出,注意力机制在NLP,CV相关问题的网络设计上被广泛应用。 “注意力机制”实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。 打个比方:当我们观察下面这张图片时,大部分人第一眼应该注意到的是小猫的面部以及吐出的舌头,然后我们才会把我们的注意力转移到图片的其他部分。 所谓的"注意力机制"也就是当机器在做一些任务,比如要识别下面这张图片是一个什么动物时,我们让机器也存在这样的一个注意力侧重,最重要该关注的地方就是图片中动物的面部特征,包括耳朵,眼睛,鼻子,嘴巴,而不用太关注背景的一些信息,核心的目的就在于希望机器能在很多的信息中注意到对当前任务更关键的信息,而对于其他的非关键信息就不需要太多的注意力侧重。 同样的如果我们在机器翻译中,我们要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。
3. 注意力机制如何实现,以及注意力机制的分类 简单来说就是对于模型的每一个输入项,可能是图片中的不同部分,或者是语句中的某个单词分配一个权重,这个权重的大小就代表了我们希望模型对该部分一个关注程度。这样一来,通过权重大小来模拟人在处理信息的注意力的侧重,有效的提高了模型的性能,并且一定程度上降低了计算量。
深度学习中的注意力机制通常可分为三类:软注意(全局注意)、硬注意(局部注意)和自注意(内注意) 1. Soft/Global Attention(软注意机制): 对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。 2. Hard/Local Attention(硬注意机制): 对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。 3. Self/Intra Attention(自注意力机制): 对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
References:
https://arxiv.org/abs/2103.16775 https://arxiv.org/abs/1406.6247 https://arxiv.org/abs/1706.03762
02
1. 自注意力机制概述
自注意力机制实际上是注意力机制中的一种,也是一种网络的构型,它想要解决的问题是网络接收的输入是很多向量,并且向量的大小也是不确定的情况,比如机器翻译(序列到序列的问题,机器自己决定多少个标签),词性标注(Pos tagging一个向量对应一个标签),语义分析(多个向量对应一个标签)等文字处理问题。
2. 文字处理中单词向量编码的方式
在文字处理中,我们对单词进行向量编码通常有两种方式: 1. 独热编码(one-hot encoding): 用N位的寄存器对N个状态编码,通俗来讲就是开一个很长很长的向量,向量的长度和世界上存在的词语的数量是一样多的,每一项都表示一个词语,只要把其中的某一项置1,其他的项都置0,那么就可以表示一个词语,但这样的编码方式没有考虑词语之间的相关性,并且内存占用也很大 2. 词向量编码(Word Embedding): 将词语映射(嵌入)到另一个数值向量空间,可以通过距离来表征不同词语之间的相关性 拿词性标注举例,对一个句子来说每一个词向量对应一个标签,初始的想法是可以通过全连接神经网络,但全连接神经网络没有考虑在句子不同位置,单词可能表示不同含义的问题,并且当输入的句子很长,比如是一篇文章的时候,模型的性能下降严重。
3. 自注意力机制如何实现
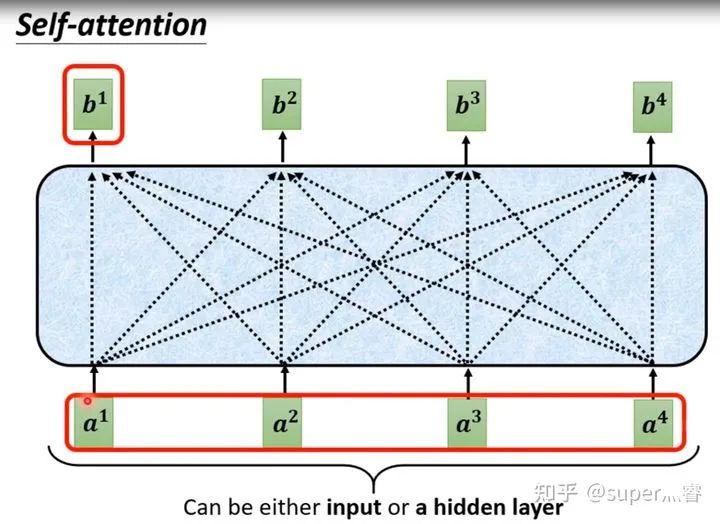
针对全连接神经网络存在的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性,它的实现方法如下: 对于每一个输入向量a,在本例中也就是每一个词向量,经过self-attention之后都输出一个向量b,这个向量b是考虑了所有的输入向量才得到的,这里有四个词向量a对应就会输出四个向量b
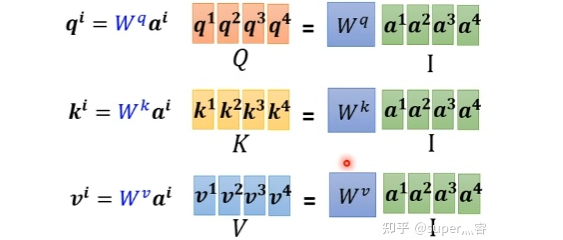
步骤1:对于每一个向量a,分别乘上三个系数 , , 得到q,k,v三个值: 写成向量形式: 写成向量形式: 写成向量形式: 得到的Q,K,V分别表示query,key和value
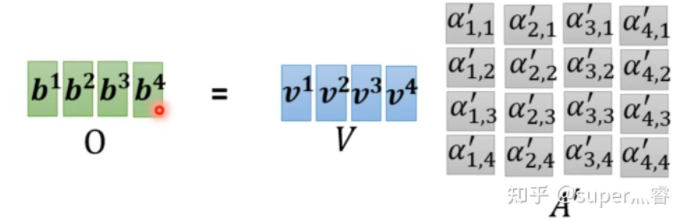
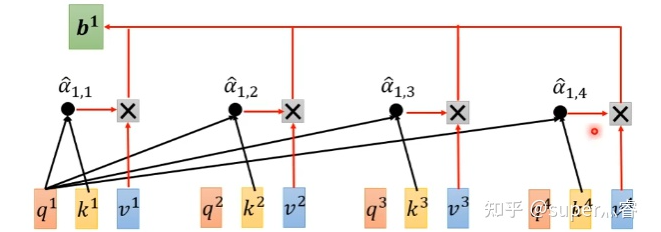
步骤2:利用得到的Q和K计算每两个输入向量之间的相关性,也就是计算attention的值α,α的计算方法有多种,通常采用点乘的方式 写成向量形式: 矩阵A中的每一个值记录了对应的两个输入向量的Attention的大小α 步骤3:对A矩阵进行softmax操作或者relu操作得到A' 步骤4:利用得到的A'和V计算每个输入向量a对应的self-attention层的输出向量b: ,写成向量形式 拿第一个向量a1对应的self-attention输出向量b1举例,它的产生过程如下:
先通过三个W矩阵生成q,k,v;然后利用q,k计算attention的值α,再把所有的α经过softmax得到α';最后对所有的v进行加权求和,权重是α',得到a1对应的self-attention输出的b1
4. 自注意力机制的问题
自注意力机制虽然考虑了所有的输入向量,但没有考虑到向量的位置信息。在实际的文字处理问题中,可能在不同位置词语具有不同的性质,比如动词往往较低频率出现在句首。 有学者提出可以通过位置编码(Positional Encoding)来解决这个问题:对每一个输入向量加上一个位置向量e,位置向量的生成方式有多种,通过e来表示位置信息带入self-attention层进行计算。 https://arxiv.org/abs/2003.09229
5. 自注意力机制&CNN、RNN
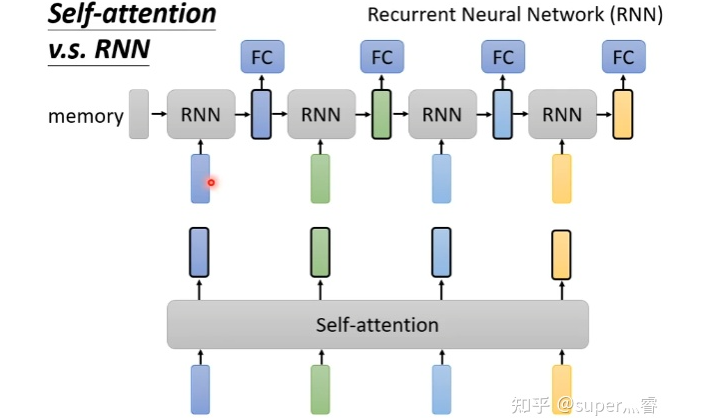
实际上,在处理图像问题时,每一个像素点都可以看成一个三维的向量,维度就是图像的通道数,所以图像也可以看成是很多向量输入到模型,自注意力机制和CNN的概念类似,都是希望网络不仅仅考虑某一个向量,也就是CNN中希望模型不仅仅考虑某一个像素点,而是让模型考虑一个正方形或者矩形的感受野(Receptive field),对于自注意力机制来说,相当于模型自己决定receptive field是怎样的形状和类型。所以其实CNN卷积神经网络是特殊情况下的一种self-attention,self-attention就是复杂版的CNN。 https://arxiv.org/abs/1911.03584 RNN和自注意力机制也类似,都是接受一批输入向量,然后输出一批向量,但RNN只能接受前面的输出作为输入,self-attention可以同时接受所有的向量作为输入,所以一定程度上说Self-attention比RNN更具效率 https://arxiv.org/abs/2006.16236
相关链接:
https://zhuanlan.zhihu.com/p/364819787
https://zhuanlan.zhihu.com/p/365550383
双一流大学研究生团队创建,专注于目标检测与深度学习,希望可以将分享变成一种习惯! 点赞 三连,支持一下吧↓



 ,
,  ,
, 得到q,k,v三个值:
得到q,k,v三个值: 写成向量形式:
写成向量形式: 
 写成向量形式:
写成向量形式: 
 写成向量形式:
写成向量形式: 
 写成向量形式:
写成向量形式: 

 ,写成向量形式
,写成向量形式