
用模型“想象”出来的target来训练,可以提高分类的效果!
前言:今天是2020年最后一天,这篇文章也是我的SimpleAI公众号2020年的最后一篇推文,感谢大家一直以来的陪伴和支持,希望SimpleAI曾带给各位可爱的读者们一点点的收获吧~这么特殊的一天,我也来介绍一篇特殊的论文,那就是今年我和组里几位老师合作的一篇AAAI论文:“Label Confusion Learning to Enhance Text Classification Models”。这篇文章的主要思想是通过构造一个“标签混淆模型”来实时地“想象”一个比one-hot更好的标签分布,从而使得各种深度学习模型(LSTM、CNN、BERT)在分类问题上都能得到更好的效果。个人感觉,还是有、意思的。

论文标题:Label Confusion Learning to Enhance Text Classification Models 会议/期刊:AAAI-21 团队:上海财经大学 信息管理与工程学院 AI Lab
一、主要贡献
本文的主要贡献有这么几点:
构造了一个插件——"Label Confusion Model(LCM)",可以在模型训练的时候实时计算样本和标签间的关系,从而生成一个标签分布,作为训练的target,实验证明,这个新的target比one-hot标签更好; 这个插件不需要任何外部的知识,也仅仅在训练的时候才需要,不会增加模型预测时的时间,不改变原模型的结构。所以LCM的应用范围很广; 实验发现LCM还具有出色的抗噪性和抗干扰能力,对于有错标的数据集,或者标签间相似度很高的数据集,有更好的表现。
二、问题背景、相关工作
1. 用one-hot来训练不够好
本文主要是从文本分类的角度出发的,但文本分类和图像分类实际上在训练模式上是类似的,基本都遵循这样的一个流程:
step 1. 一个深度网络(DNN,诸如LSTM、CNN、BERT等)来得到向量表示
step 2. 一个softmax分类器来输出预测的标签概率分布p
step 3. 使用Cross-entropy来计算真实标签(one-hot表示)与p之间的损失,从而优化
这里使用cross-entropy loss(简称CE-loss)基本上成了大家训练模型的默认方法,但它实际上存在一些问题。下面我举个例子:
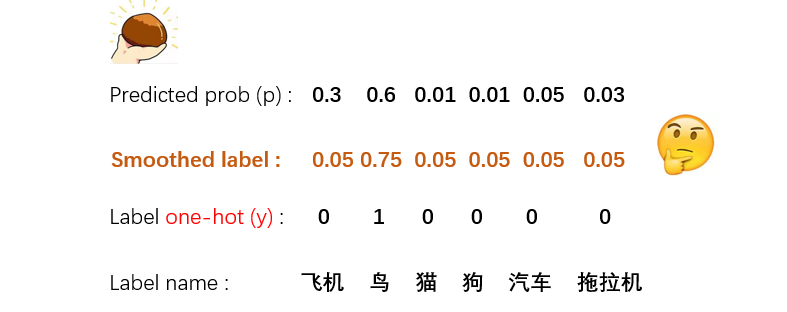
比如有一个六个类别的分类任务,CE-loss是如何计算当前某个预测概率p相对于y的损失呢:

可以看出,根据CE-loss的公式,只有y中为1的那一维度参与了loss的计算,其他的都忽略了。这样就会造成一些后果:
真实标签跟其他标签之间的关系被忽略了,很多有用的知识无法学到;比如:“鸟”和“飞机”本来也比较像,因此如果模型预测觉得二者更接近,那么应该给予更小的loss 倾向于让模型更加“武断”,成为一个“非黑即白”的模型,导致泛化性能差; 面对易混淆的分类任务、有噪音(误打标)的数据集时,更容易受影响
总之,这都是由one-hot的不合理表示造成的,因为one-hot只是对真实情况的一种简化。
2. 一些可能的解决办法
LDL:既然one-hot不合理,那我们就使用更合理的标签分布来训练嘛。比如下图所示:

如果我们能获取真实的标签分布来训练,那该多好啊。
这种使用标签的分布来学习模型的方法,称为LDL(Label Distribution Learning),东南大学耿新团队专门研究这个方面,大家可以去了解一下。
但是,真实的标签分布,往往很难获取,甚至不可获取,只能模拟。比如找很多人来投票,或者通过观察进行统计。比如在耿新他们最初的LDL论文中,提出了很多生物数据集,是通过实验观察来得到的标签分布。然而,大多数的现有的数据集,尤其是文本、图像分类,几乎都是one-hot的,所以LDL并无法直接使用。
Label Enhancement:Label Enhancement,标签增强技术,则是一类从通过样本特征空间来生成标签分布的方法,我在前面的论文解读中有介绍:“神奇的”标签增强技术(Label Enhancement),这些方法都很有趣。
然而,使用这些方法来训练模型,都比较麻烦,因为我们需要通过“两步走”来训练,第一步使用LE的方法来构造标签分布,第二步再使用标签分布来训练。
Loss Correction:面对one-hot可能带来的容易过拟合的问题,有研究提出了Label Smoothing方法:
label smoothing就是把原来的one-hot表示,在每一维上都添加了一个随机噪音。这是一种简单粗暴,但又十分有效的方法,目前已经使用在很多的图像分类模型中了。
这种方法,一定程度上,可以缓解模型过于武断的问题,也有一定的抗噪能力。但是单纯地添加随机噪音,也无法反映标签之间的关系,因此对模型的提升有限,甚至有欠拟合的风险。
当然还有一些其他的Loss Correction方法,可以参考我前面的一个介绍:样本混进了噪声怎么办?通过Loss分布把它们揪出来!。
三、我们的思想&模型设计
我们最终的目标,是能够使用更加合理的标签分布来代替one-hot分布训练模型,最好这个过程能够和模型的训练同步进行。
首先我们思考,一个合理的标签分布,应该有什么样的性质。
① 很自然地,标签分布应该可以反映标签之间的相似性。比方下面这个例子:
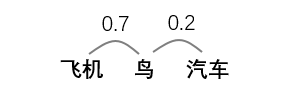
② 标签间的相似性是相对的,要根据具体的样本内容来看。比方下面这个例子,同样的标签,对于不同的句子,标签之间的相似度也是不一样的:
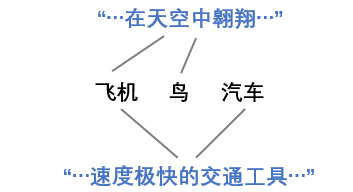
③ 构造得到的标签分布,在01化之后应该跟原one-hot表示相同。啥意思呢,就是我们不能构造出了一个标签分布,最大值对应的标签跟原本的one-hot标签还不一致,我们最终的标签分布,还是要以one-hot为标杆来构造。
根据上面的思考,我们这样来设计模型:
使用一个Label Encoder来学习各个label的表示,与input sample的向量表示计算相似度,从而得到一个反映标签之间的混淆/相似程度的分布。最后,使用该混淆分布来调整原来的one-hot分布,从而得到一个更好的标签分布。
设计出来的模型结构如图:
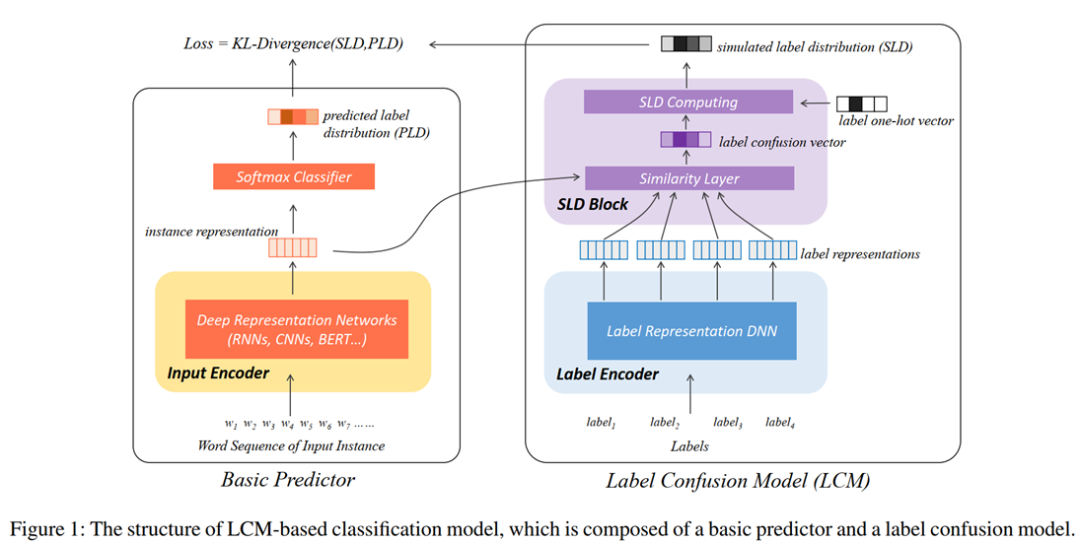
这个结构分两部分,左边是一个Basic Predictor,就是各种我们常用的分类模型。右边的则是LCM的模型。注意LCM是一个插件,所以左侧可以更换成任何深度学习模型。
Basic Predictor的过程可以用如下公式表达:
其中就是输入的文本的通过Input Decoder得到的表示。则是predicted label distribution(PLD)。
LCM的过程可以表达为:
其中代表label通过Label Encoder得到的标签表示矩阵,是标签和输入文本的相似度得到的标签混淆分布,是真实的one-hot表示,二者通过一个超参数结合再归一化,得到最终的,即模拟标签分布,simulated label distribution(SLD)。
最后,我们使用KL散度来计算loss:
总体来说还是比较简单的,很好复现,其实也存在更优的模型结构,我们还在探究。
四、实验&结果分析
1. Benchmark数据集上的测试
我们使用了2个中文数据集和3个英文数据集,在LSTM、CNN、BERT三种模型架构上进行测试,实验表明LCM可以在绝大多数情况下,提升主流模型的分类效果。
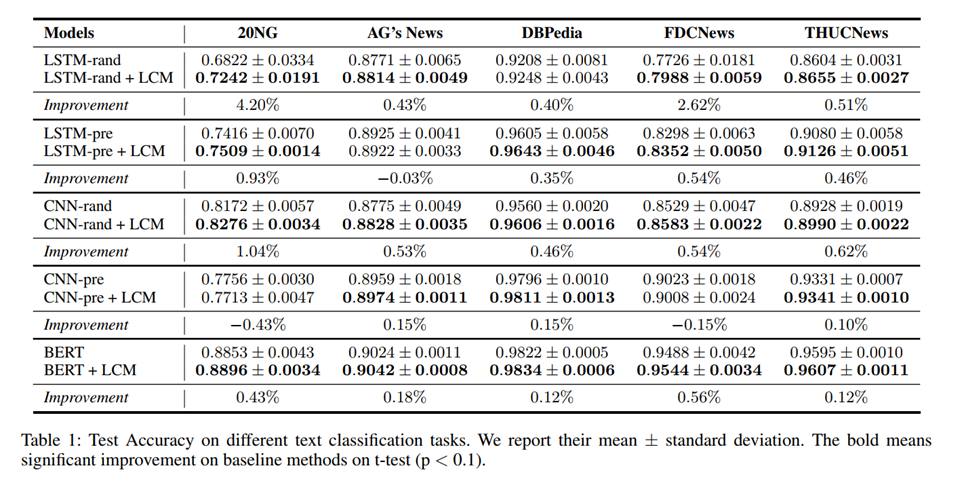
下面这个图展示了不同水平的α超参数对模型的影响:
从图中可以看出,不管α水平如何,LCM加成的模型,都可以显著提高收敛速度,最终的准确率也更高。针对不同的数据集特征,我们可以使用不同的α(比如数据集混淆程度大,可以使用较小的α),另外,论文中我们还介绍了在使用较小α的时候,可以使用early-stop策略来防止过拟合。
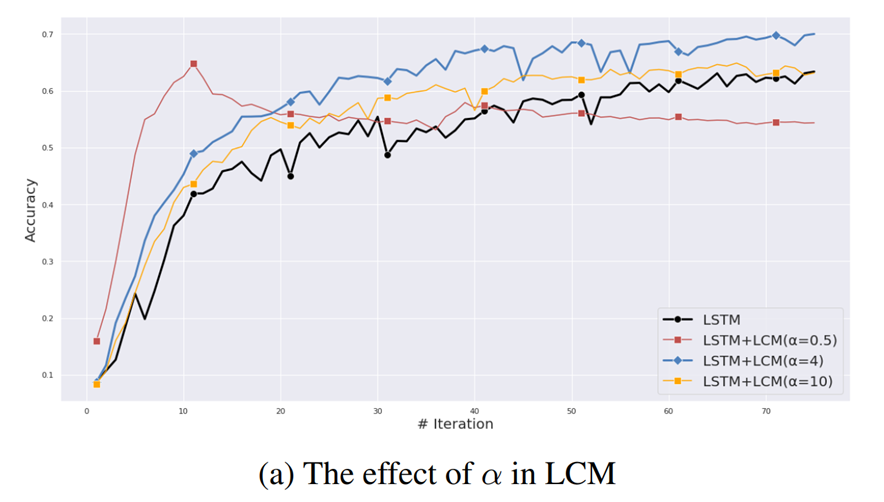
而下面这个图则展示了LCM确实可以学习到label之间的一些相似性关系,而且是从完全随机的初始状态开始学到的:
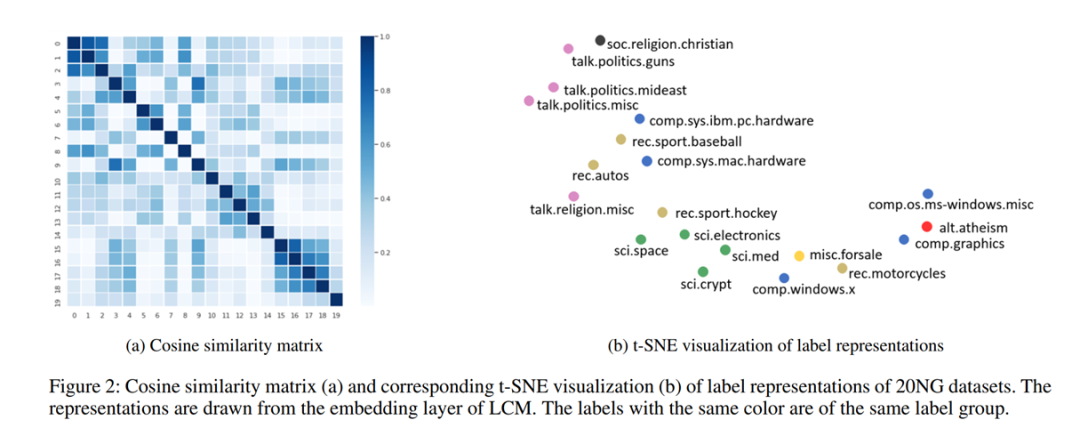
2. 难以区分的数据集(标签易混淆)
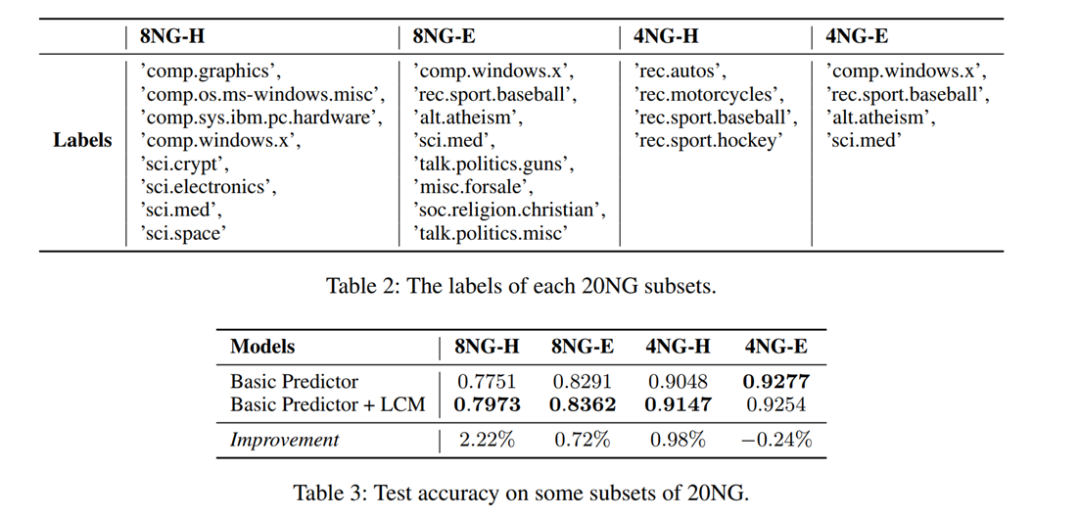
我们构造了几个“简单的”和“困难的”数据集,通过实验标签,LCM更适合那些容易混淆的数据集:
3. 有噪音的数据集
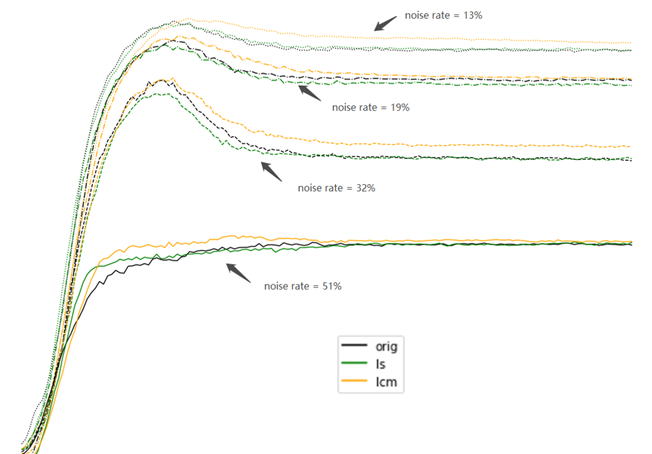
我们还测试了在不同噪音水平下的数据集上的效果,并跟Label Smoothing方法做了对比,发现是显著好于LS方法的。
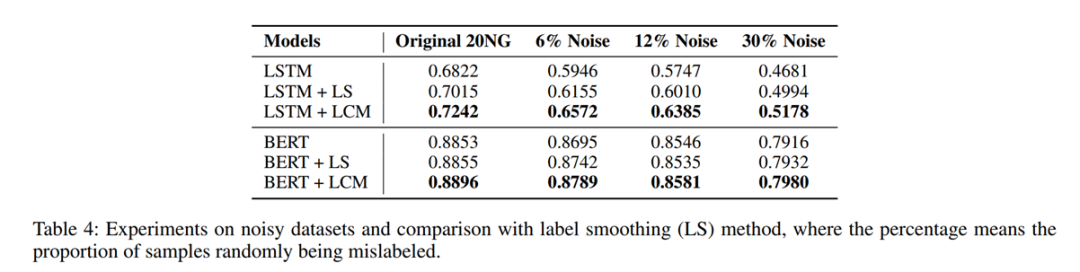
下面这个图展示了另外一组更细致的实验结果:
4. 在图像分类上也有效果
最后,我们在图像任务上也简单测试了一下,发现也有效果:

五、总结
这篇文章的总体思路是简单清晰的,即通过一个Label Encoder来在训练中学习出label embedding,然后使用这个embedding跟input embedding通过相似度来逐渐构造出标签分布,由于这样的标签分布可以反映出标签跟样本、标签跟标签之间的关系,蕴含了比one-hot更多的有用信息,因此可以为分类模型带来性能的提升。
后记:这篇推文的标题中我称之为“想象”,是因为LCM是不依靠任何外部知识的,完全使用自己在训练模型中所使用的信息。如果说one-hot就是我们面对的残酷的现实,那么LCM则是想象出一个更加美好的目标,让模型往更美好的目标进发。曾经不知道在哪里看到这样一句话:“瞄准月亮,即便你没到达,你将置身星星之中。”度过了艰难的2020年,希望在2021年,无论现实多么残酷,我们依然能够心存美好的向往,依然能够鼓起向上攀登的勇气,依然能够努力、乐观地生活!最后,再次感谢SimpleAI的读者们,我们2021再见!