
一文读懂CNN分类模型的奋斗史
「@Author:Runsen」
在过去的几年里,许多深度学习模型涌现出来,例如层的类型、超参数等。在本系列中,我将回顾几个最著名的 deeplearning 图像分类的模型。
AlexNet (2012 )
VGG (2014)
GoogleNet (2014)
ResNet (2015)
Inception v3 (2015)
SqueezeNet (2016)
DenseNet (2016)
Xception (2016)
ShuffleNet v2 (2018)
MnasNet (2018)
ResNeXt(2019)
MobileNetv3 (2019)
EfficientNet 2019 and EfficientNet v2 2021
AlexNet (2012 )
2012 年,AlexNet 由 Alex Krizhevsky 为 ImageNet 大规模视觉识别挑战赛 ( ILSVRV ) 提出的,ILSVRV 评估用于对象检测和图像分类的算法。
AlexNet 总共由八层组成,其中前5层是卷积层,后3层是全连接层。前两个卷积层连接到重叠的最大池化层以提取最大数量的特征。第三、四、五卷积层直接与全连接层相连。卷积层和全连接层的所有输出都连接到 ReLu 非线性激活函数。最后的输出层连接到一个 softmax 激活层,它产生 1000 个类标签的分布。
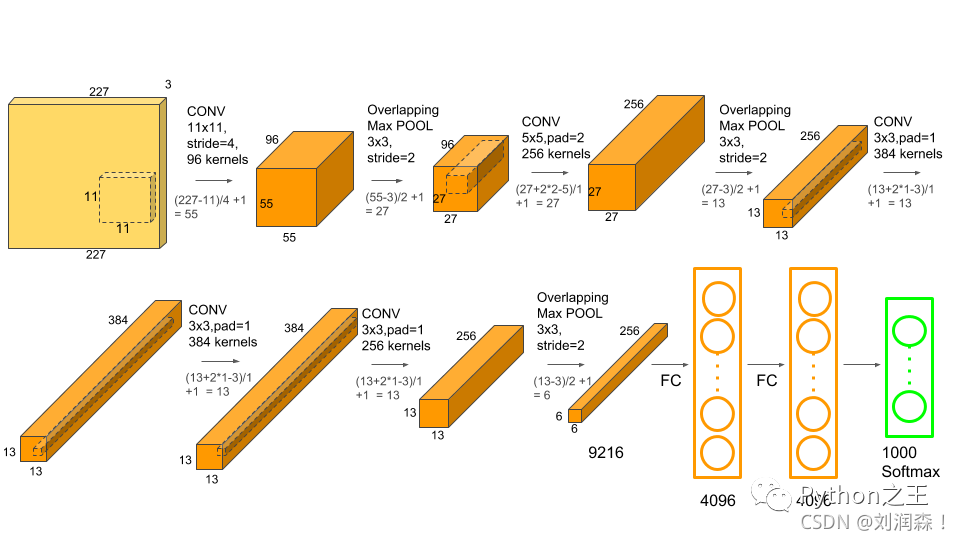
VGG (2014)
VGG 是一种流行的神经网络架构,由2014年,牛津大学的 Karen Simonyan 和 Andrew Zisserman 提出。
与 AlexNet 相比,VGG 的主要改进包括使用大内核大小的过滤器(第一和第二卷积层中的大小分别为 11 和 5)和多个(3×3)内核大小的过滤器。
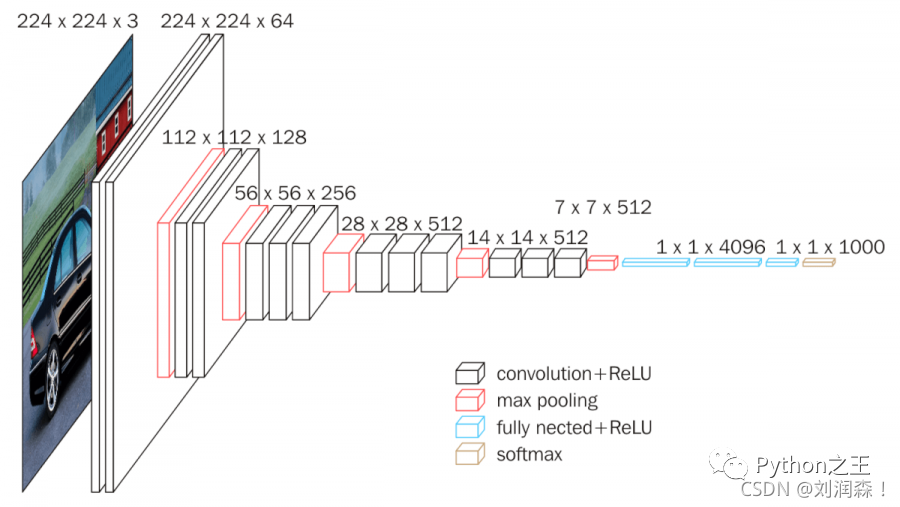
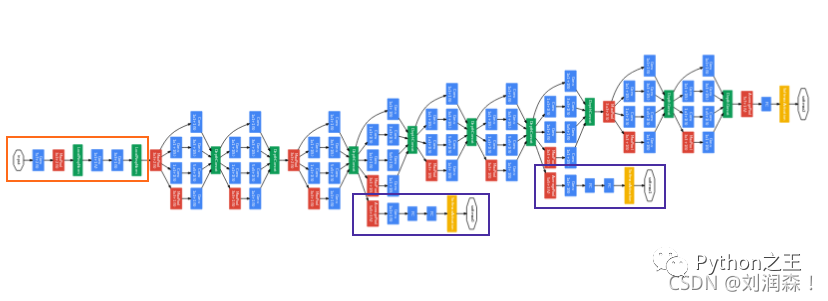
GoogleNet (2014)
2014年,GoogleNet 诞生,该架构有 22 层深,包括 27 个池化层。总共有 9 个初始模块线性堆叠。Inception 模块的末端连接到全局平均池化层。下面是完整 GoogleNet 架构的缩小图像。
ResNet (2015)
由于深度神经网络训练既费时又容易过拟合,微软引入了一个残差学习框架来改进比以前使用的更深的网络的训练。
ResNet在PyTorch的官方代码中共有5种不同深度的结构,深度分别为18、34、50、101、152(各种网络的深度指的是“需要通过训练更新参数”的层数,如卷积层,全连接层等)。
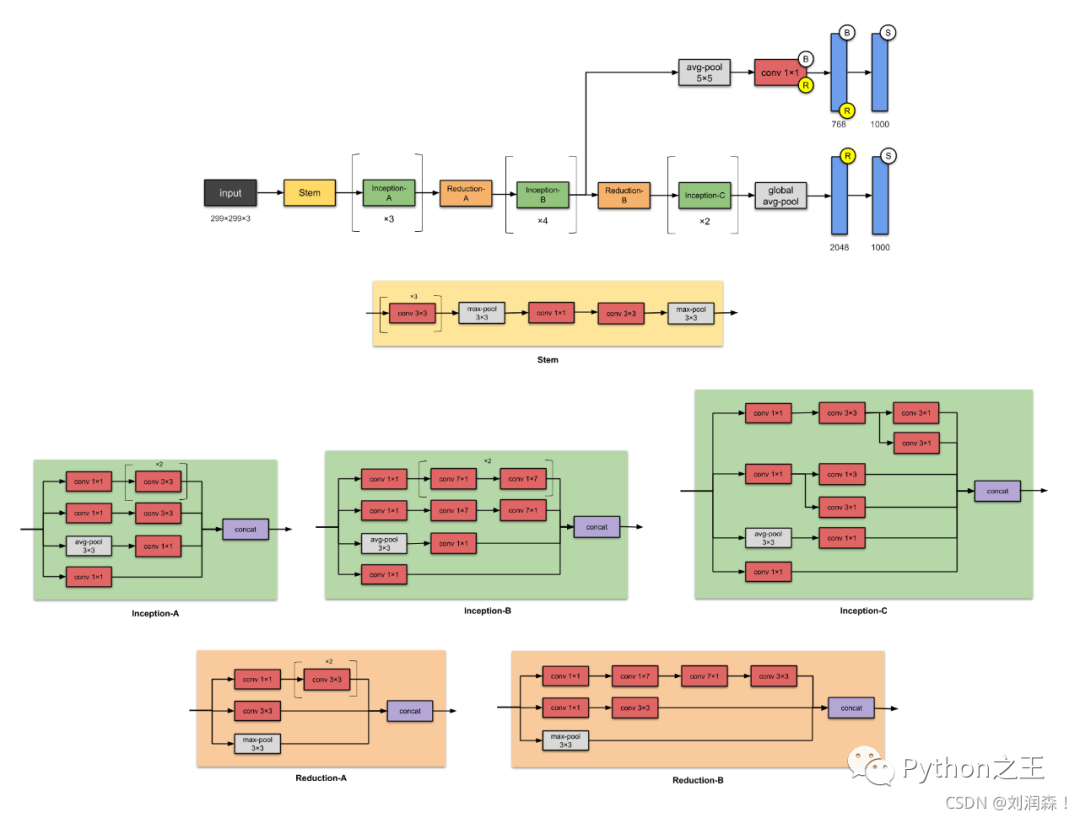
Inception v3 (2015)
与 VGGNet 相比,Inception Networks 已被证明在计算效率更高
Inception v3 网络的架构是逐步构建的,结构图可点击查看大图
SqueezeNet (2016)
SqueezeNet 是一个较小的网络,它的参数比 AlexNet 少近 50 倍,但执行速度快 3 倍。
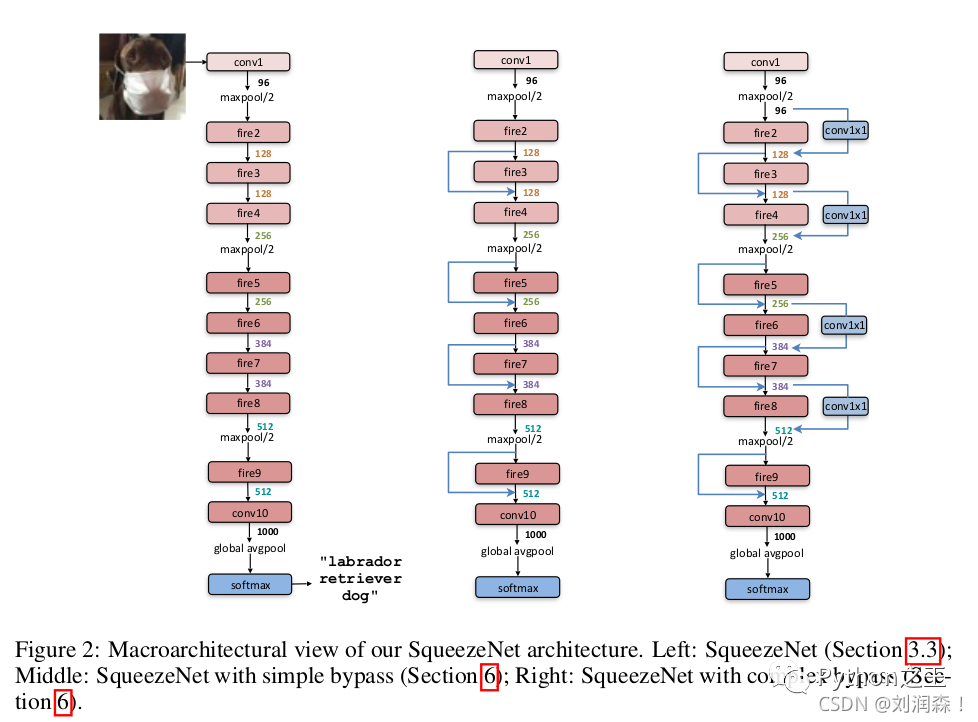 如上图中最左边所示,SqueezeNet 以一个标准的卷积层开始,然后是 8 个 Fire 模块,最后再以一个卷积层结束。步长为 2 的池化分别跟在第一个卷积层、 第 4 个 Fire 模块、第 8 个 Fire 模块和最后一个卷积层后面。
如上图中最左边所示,SqueezeNet 以一个标准的卷积层开始,然后是 8 个 Fire 模块,最后再以一个卷积层结束。步长为 2 的池化分别跟在第一个卷积层、 第 4 个 Fire 模块、第 8 个 Fire 模块和最后一个卷积层后面。
中间的网络结构在特征图通道数相同的 Fire 模块之间引入了残差网络中的跳跃连接,而最右边的网络结构在中间结构的基础上,针对特征图通道数不一样的情况,通过一个 1×1 的卷积来调整通道数一致后再相加。
DenseNet (2016)
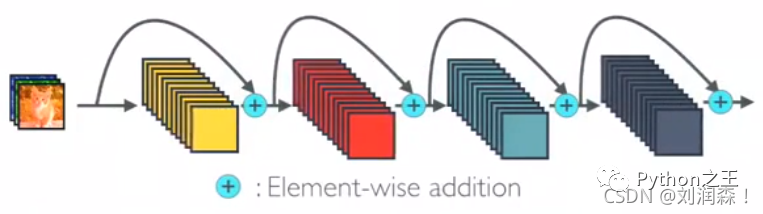
DenseNet 拥有与传统深度 CNN 相比的一大优势:通过多层的信息在到达网络末端时不会被冲刷或消失。这是通过简单的连接模式实现的。要理解这一点,必须知道普通 CNN 中的层是如何连接的。

这是一个简单的 CNN,其中各层按顺序连接。然而,在DenseNet 中,每一层从所有前面的层获得额外的输入,并将其自己的特征映射传递给所有后续层。下面是描绘DenseNet 的图像。
Xception (2016)
Xception是Google公司继Inception后提出的对 Inception-v3 的另一种改进。
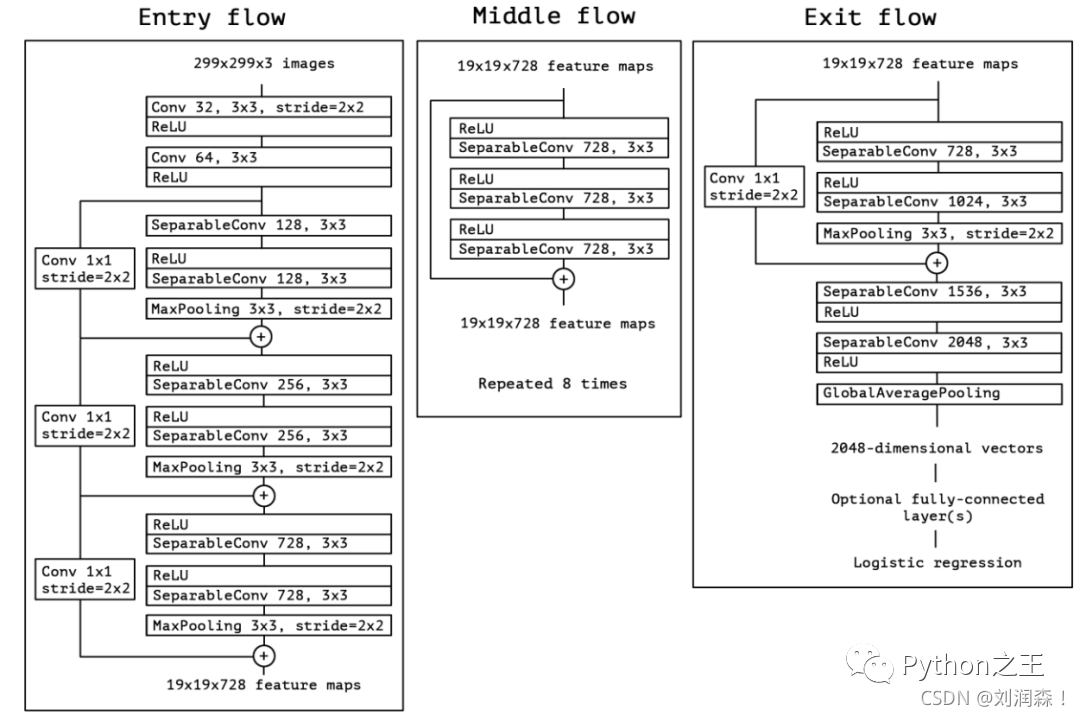
Xception 的结构基于 ResNet,但是将其中的卷积层换成了Separable Convolution(极致的 Inception模块)。如下图所示。整个网络被分为了三个部分:Entry,Middle和Exit。
ShuffleNet v2 (2018)
2018年,开始了轻度网络的研究,MnasNet ,MobileNet,ShuffleNet,,Xception采用了分组卷积,深度可分离卷积等操作,这些操作在一定程度上大大减少了FLOP。
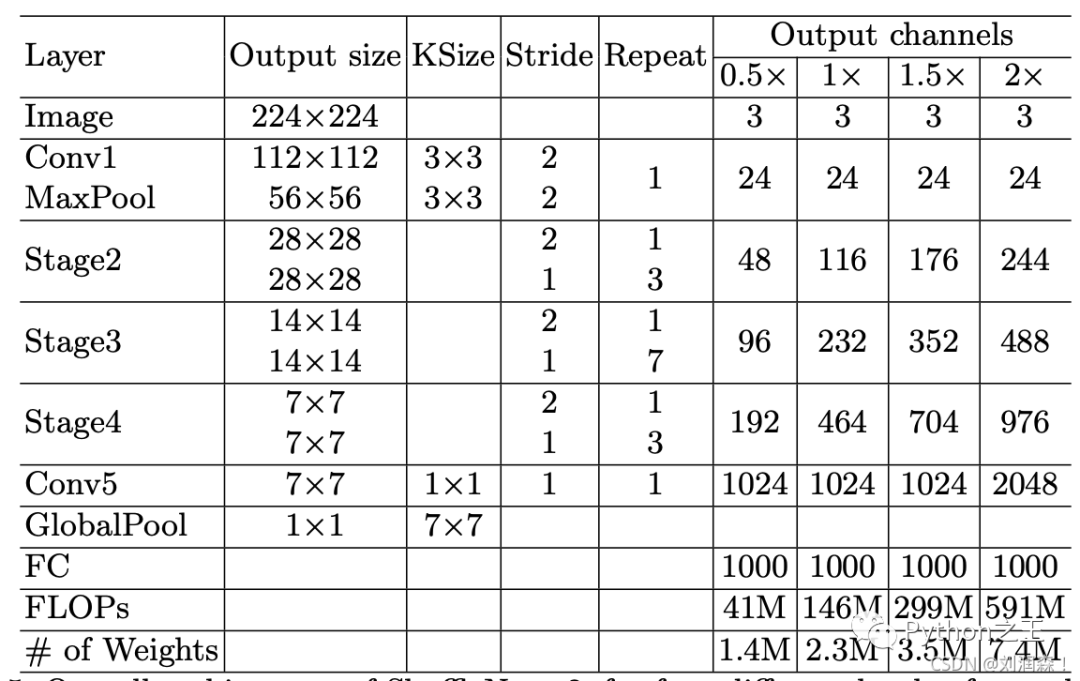
整体 ShuffleNet v2 架构列表如下:
MnasNet (2018)
Google 团队最新提出 MnasNet,使用强化学习的思路,提出一种资源约束的终端 CNN 模型的自动神经结构搜索方法。
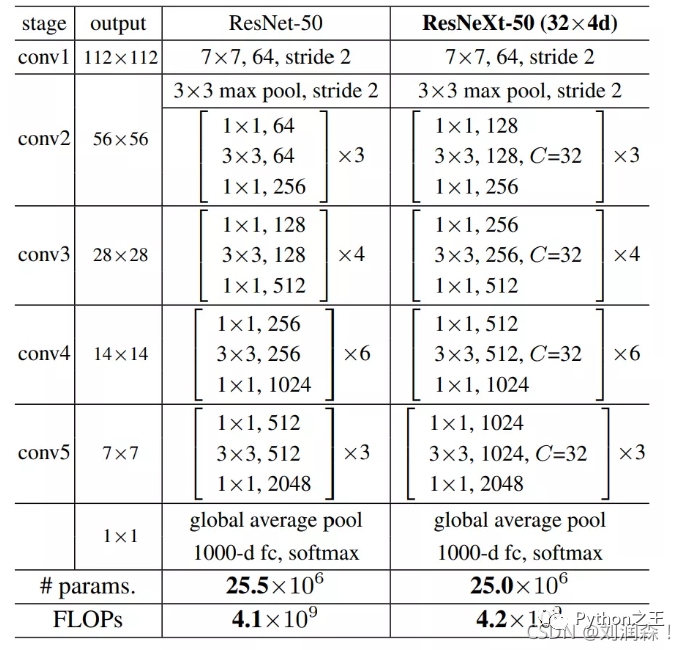
ResNeXt(2019)
ResNeXt是ResNet 的变体,
ResNet有许多版本,对应的ResNeXt也有许多不同版本。
对比下,ResNet50和ResNeXt-50的网络结构图如下:
MobileNetv3 (2019)
在ImageNet分类任务上,相对于MobileNetV2, MobileNetV3-small精度提高了大约3.2%,时间减少了15%,MobileNetV3-large精度提高了大约34.6%,时间减少了5%。
MobileNetV3的large和small结构如下图所示。

EfficientNet 2019 and EfficientNet v2 2021
谷歌研究人员在一篇 ICML 2019 论文《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》中,提出了一种新型模型缩放方法,该方法使用一种简单但高效的复合系数(compound coefficient)以更加结构化的方式扩展 CNN,这成为后ResNet时代的顶流EfficientNet,
万水千山总是情,点个在看行不行?😋