
使用深度学习进行疟疾检测 | PyTorch版
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
蚊子看起来很小,很脆弱,但是是非常危险的。众所周知,疟疾对所有年龄段的人来说都是一种威胁生命的疾病,它通过蚊子传播。更重要的是,在最初的阶段,这些症状很容易被误认为是发烧、流感或普通感冒。但是,在晚期,它可以通过感染和破坏细胞结构造成严重破坏,这可能危及生命。如果不及时治疗,甚至可能导致死亡。
虽然大多数研究人员认为这种疾病起源于非洲大陆,但这种疾病的起源仍有争议。南美洲国家、非洲国家和印度次大陆由于疟疾而面临很高的感染风险,这主要是由于它们的热带气候是受感染雌蚊的催化剂和繁殖场所,而受感染的雌蚊携带造成这种疾病的疟原虫寄生虫。
我们这个项目的目标是开发一个系统,可以检测这种致命的疾病,而不必完全依靠医学测试。
所以,在进入主要部分之前,让我们先完成一些相关工作。
这个数据集最初来自于美国国立卫生研究院的网站并上传到 Kaggle。数据集包含27558张细胞图像。其中,我们有13779张被疟疾感染的细胞图像和另外13779张未感染的图像。我们正在试图解决一个分类问题。使用的框架是 Pytorch。数据集下载地址为:https://www.kaggle.com/iarunava/cell-images-for-detecting-malaria
现在,让我们开始创建我们的疟疾检测模型。
导入相关库
现在让我们来做一些数据探索:
首先,我们将输入数据并对其进行图像相关处理
import osimport torchimport pandas as pdimport numpy as npfrom torch.utils.data import Dataset, random_split, DataLoaderfrom PIL import Imageimport torchvision.models as modelsimport matplotlib.pyplot as pltimport torchvision.transforms as transformsfrom sklearn.metrics import f1_scoreimport torch.nn.functional as Fimport torch.nn as nnfrom torchvision.utils import make_grid%matplotlib inline
a) 数据集包含不规则形状的图像。这将阻碍模特训练。因此,我们将图像调整为128 x 128的形状。
b) 我们还将把数据转换为张量,因为它是使用深度学习训练模型的有用格式。
PyTorch 的美妙之处在于,它允许我们通过使用非常少的代码行来进行图像的各种操作。
from torchvision.datasets import ImageFolderfrom torchvision.transforms import ToTensorfrom torchvision.transforms import Composefrom torchvision.transforms import Resizefrom torchvision.transforms import ToPILImagedataset = ImageFolder(data_dir, transform=Compose([Resize((128, 128), interpolation=3),ToTensor()]))classes = dataset.classesprint(classes)len(dataset)
['Parasitized', 'Uninfected']
27558现在,我们将编写一个辅助函数来可视化一些图像。
import matplotlib.pyplot as pltdef show_example(img, label):print('Label: ', dataset.classes[label], "("+str(label)+")")plt.imshow(img.permute(1, 2, 0))
让我们看一组这两个类的图像。
show_example(*dataset[2222])
show_example(*dataset[22269])
为了获得可重复的结果,我们需要通过设置seed。
random_seed = 42torch.manual_seed(random_seed);
现在,让我们将整个图像集划分为训练集、验证集和测试集。显然,训练集是用于训练模型的,而验证集是用于确保训练朝着正确的方向进行。测试集是用来测试模型最后的性能。
val_size = 6000train_size = 16000test_size = len(dataset) - val_size - train_sizetrain_ds, val_ds, test_ds = random_split(dataset, [train_size, val_size, test_size])len(train_ds), len(val_ds), len(test_ds)
(16000, 6000, 5558)
我们将尝试通过使用批量图像来训练我们的模型。在这里,PyTorch 的 DataLoader 为我们提供了便利。它提供了对给定数据集的迭代。
from torch.utils.data.dataloader import DataLoaderbatch_size=128
我们将使用 DataLoader 创建用于训练和验证的批处理。我们需要确保在训练期间内部调整批次。这只是为了在模型中引入一些随机性。我们没有用于验证集的内部 shuffle,因为我们只是使用它来验证每个epoch的模型性能。
train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
现在让我们尝试可视化一批图像。
from torchvision.utils import make_griddef show_batch(dl):for images, labels in dl:fig, ax = plt.subplots(figsize=(12, 6))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images, nrow=16).permute(1, 2, 0))break

因为我们的数据是图像,所以我们要训练一个卷积神经网络。如果你害怕听这些,那么你并不孤单。当我第一次听到 CNN 时,我也非常害怕。但是,坦白地说,由于 Tensorflow 和 PyTorch 这样的深度学习框架,它们的理解非常简单,实现起来也非常简单。
细胞神经网络的使用卷积运算在初始层提取特征。最后的图层是普通的线性图层。
我们将为包含各种功能函数的模型定义一个 Base 类。如果我们将来试图解决类似的问题,这些方法可能会有所帮助。
def accuracy(outputs, labels):_, preds = torch.max(outputs, dim=1)return torch.tensor(torch.sum(preds == labels).item() / len(preds))class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))
现在让我们定义一个继承 ImageClassificationBase 类的 Malaria2CnnModel 类:
class Malaria2CnnModel(ImageClassificationBase):def __init__(self):super().__init__()self.network = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 64 x 64 x 64nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 128 x 32 x 32nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 256 x 16 x 16nn.Flatten(),nn.Linear(256*16*16, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 2))def forward(self, xb):return self.network(xb)
model = Malaria2CnnModel()model
Malaria2CnnModel(
(network): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU()
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU()
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU()
(14): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(15): Flatten()
(16): Linear(in_features=65536, out_features=1024, bias=True)
(17): ReLU()
(18): Linear(in_features=1024, out_features=512, bias=True)
(19): ReLU()
(20): Linear(in_features=512, out_features=2, bias=True)
)
)如果我们使用 CPU,训练一个深度学习模型是非常耗时耗力的。有很多像 Kaggle 和 google 的 Colab 这样的平台提供免费的 GPU 计算来训练模型。下面的帮助函数可以帮助我们找到是否有任何 GPU 可用于我们的系统。如果是的话,我们可以把我们的数据和模型转移到 GPU 中,以便更快的计算。
def get_default_device():"""Pick GPU if available, else CPU"""if torch.cuda.is_available():return torch.device('cuda')else:return torch.device('cpu')def to_device(data, device):"""Move tensor(s) to chosen device"""if isinstance(data, (list,tuple)):return [to_device(x, device) for x in data]return data.to(device, non_blocking=True)class DeviceDataLoader():"""Wrap a dataloader to move data to a device"""def __init__(self, dl, device):self.dl = dlself.device = devicedef __iter__(self):"""Yield a batch of data after moving it to device"""for b in self.dl:yield to_device(b, self.device)def __len__(self):"""Number of batches"""return len(self.dl)
device = get_default_device()device
device(type='cuda')我们已经定义了一个 DeviceDataLoader 类来传输我们的模型、训练和验证数据。
train_dl = DeviceDataLoader(train_dl, device)val_dl = DeviceDataLoader(val_dl, device)to_device(model, device);
现在,我们将定义我们的fit()函数和evaluate()函数。fit()用于训练模型,evaluate()用于查看每个epoch结束时的模型性能。一个epoch可以理解为整个训练过程中的一个步骤。
def evaluate(model, val_loader):model.eval()outputs = [model.validation_step(batch) for batch in val_loader]return model.validation_epoch_end(outputs)def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):history = []optimizer = opt_func(model.parameters(), lr)for epoch in range(epochs):# Training Phasemodel.train()train_losses = []for batch in train_loader:loss = model.training_step(batch)train_losses.append(loss)loss.backward()optimizer.step()optimizer.zero_grad()# Validation phaseresult = evaluate(model, val_loader)result['train_loss'] = torch.stack(train_losses).mean().item()model.epoch_end(epoch, result)history.append(result)return history
让我们把我们的模型转移到一个 GPU 设备上。
model = to_device(Malaria2CnnModel(), device)我们将对模型进行评估,以便在训练之前了解它在验证集上的执行情况。
evaluate(model, val_dl){'val_loss': 0.6931465864181519, 'val_acc': 0.5000697374343872}在训练之前,我们可以达到50% 的准确率。对于医疗保健领域的关键应用来说,这个数字非常低。我们将设置 epochs 的数目为10,设置优化器为torch.optim.Adam,以及学习率设定为0.001。
num_epochs = 10opt_func = torch.optim.Adamlr = 0.001
我们将要定义一些功能,在每个epoch结束时计算损失和准确度。
def plot_accuracies(history):accuracies = [x['val_acc'] for x in history]plt.plot(accuracies, '-x')plt.xlabel('epoch')plt.ylabel('accuracy')plt.title('Accuracy vs. No. of epochs');
def plot_losses(history):train_losses = [x.get('train_loss') for x in history]val_losses = [x['val_loss'] for x in history]plt.plot(train_losses, '-bx')plt.plot(val_losses, '-rx')plt.xlabel('epoch')plt.ylabel('loss')plt.legend(['Training', 'Validation'])plt.title('Loss vs. No. of epochs');
现在,让我们使用fit()函数来训练我们的模型。
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func)Epoch [0], train_loss: 0.6955, val_loss: 0.6876, val_acc: 0.5228
Epoch [1], train_loss: 0.5154, val_loss: 0.2328, val_acc: 0.9327
Epoch [2], train_loss: 0.1829, val_loss: 0.1574, val_acc: 0.9540
Epoch [3], train_loss: 0.1488, val_loss: 0.1530, val_acc: 0.9552
Epoch [4], train_loss: 0.1330, val_loss: 0.1388, val_acc: 0.9562
Epoch [5], train_loss: 0.1227, val_loss: 0.1372, val_acc: 0.9576
Epoch [6], train_loss: 0.1151, val_loss: 0.1425, val_acc: 0.9591
Epoch [7], train_loss: 0.1043, val_loss: 0.1355, val_acc: 0.9586
Epoch [8], train_loss: 0.0968, val_loss: 0.1488, val_acc: 0.9579
Epoch [9], train_loss: 0.0949, val_loss: 0.1570, val_acc: 0.9554
训练结束后,我们的模型从之前的50% 的准确率提高到了95.54%。
让我们绘制每个epoch后的精确度和损失图表以帮助我们理解我们的模型。
plot_accuracies(history)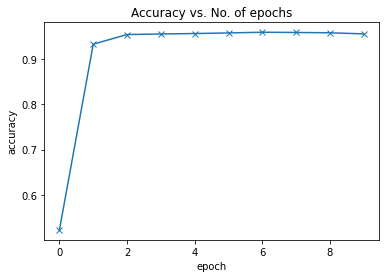
plot_losses(history)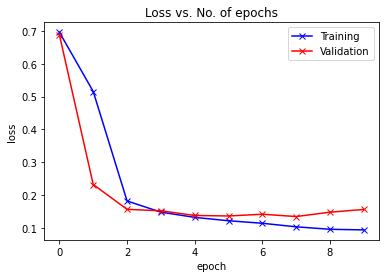
现在我们将编写一个函数来预测单个图像的类别。然后我们将对整个测试集进行预测,并检查整个测试集的准确性。
def predict_image(img, model):# Convert to a batch of 1xb = to_device(img.unsqueeze(0), device)# Get predictions from modelyb = model(xb)# Pick index with highest probabilitypreds = torch.max(yb, dim=1)# Retrieve the class labelreturn dataset.classes[preds[0].item()]
对一张图片进行预测:
img, label = test_ds[0]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))
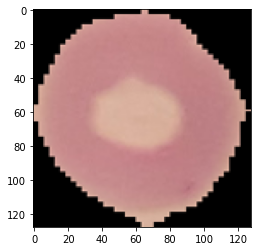
现在让我们来预测一下整个测试集:
test_loader = DeviceDataLoader(DataLoader(test_ds, batch_size*2), device)result = evaluate(model, test_loader)result
{'val_loss': 0.14322155714035034, 'val_acc': 0.9600048065185547}我们在这里得到了一些相当不错的结果。96% 是一个非常好的结果,但是我认为这仍然可以通过改变超参数来改进。我们也可以设置更多的epoch。
扩展想法:
我们将尝试应用迁移学习技巧,看看它是否能进一步提高准确性;
我们将尝试使用图像分割分析技术和图像定位技术将这些红色球状结构聚集在一起,并对其进行分析以寻找证据;
我们将尝试使用数据增强技术来限制我们的模型过拟合;
我们将学习如何在生产环境中部署模型,以便向不理解代码的人展示我们的工作。
· END ·