AF-GCL:不需要增强的图对比学习

来源:Paperweekly 本文共3500字,建议阅读5分钟 本文介绍了在图对比学习中更为方便的AF-GCL模型。

论文标题:
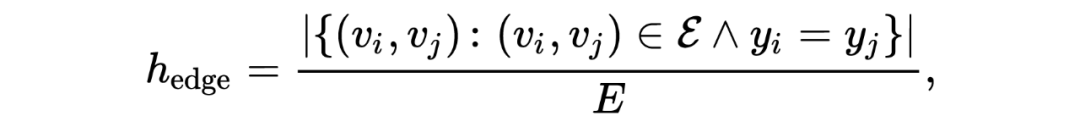
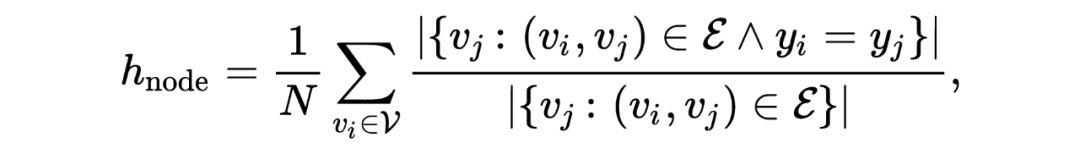

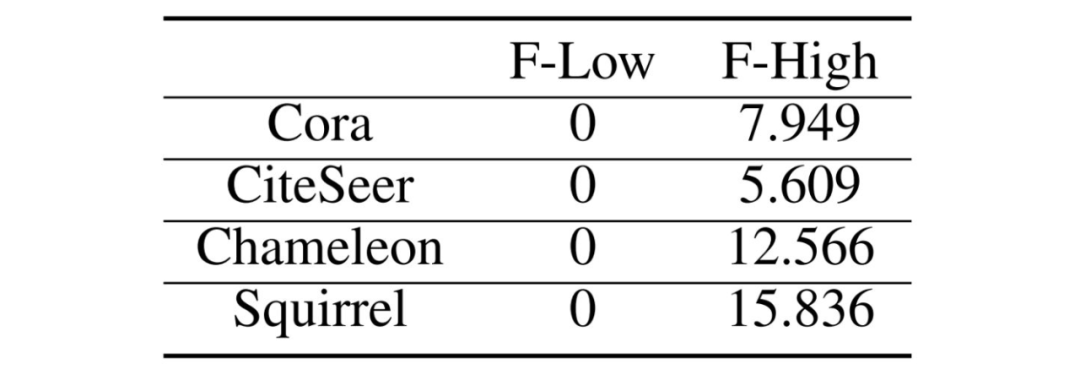
属性遮挡(Attibute Masking):随机遮挡节点特征的一部分。 加/删边(Edge Adding/Dropping):随机增/删原始图的一部分边。 图扩散(Graph Diffusion):基于个性化 PageRank(PPR)的图扩散定义为 ,其中 是扩散系数。
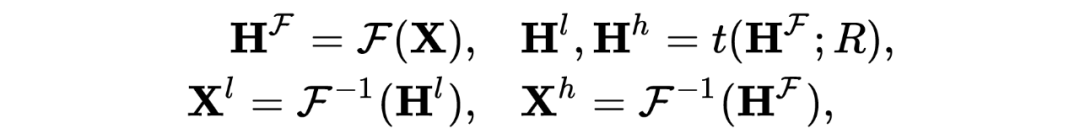
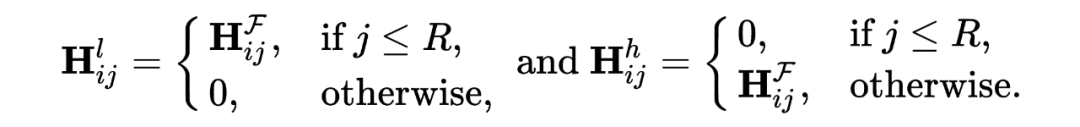




评论
 下载APP
下载APP来源:Paperweekly 本文共3500字,建议阅读5分钟 本文介绍了在图对比学习中更为方便的AF-GCL模型。
论文标题: