来源:ECCV
编辑:雅新、依明
【新智元导读】两年一度的ECCV 2020大奖终于来了!今年的最佳论文奖由普林斯顿大学Zachary Teed和邓嘉摘得,还有最佳论文提名奖,Demo奖等五大奖项公布。
全球计算机视觉三大顶会之一,两年一度的ECCV 2020(欧洲计算机视觉国际会议)于8月23日-28日召开。受到疫情影响,今年的ECCV首次以线上的形式举行。刚刚,ECCV 2020一共公布了五项大奖项,分别是最佳论文奖、最佳论文提名奖、Koenderink奖、Mark Everingham 奖、Demo奖。今年的最佳论文奖由普林斯顿大学 Zachary Teed 及其导师邓嘉摘得,来自卡内基梅隆大学的一作华人学生 Mengtian Li 获得最佳论文提名奖。
五大奖项一览:最佳论文、最佳论文提名、Demo论文
最佳论文奖由来自普林斯顿大学 Zachary Teed 和邓嘉摘得,获奖论文是「RAFT:Recurrent All-Pairs Field Transforms for Optical Flow 」。值得一提的是,邓嘉正是 Zachary Teed 的导师,而邓嘉曾师从李飞飞教授。  论文链接:https://arxiv.org/pdf/2003.12039.pdf本篇论文主要介绍了一种新的光流深度网络架构——递归全对场变换(RAFT)。RAFT提取每个像素特征,为所有像素对构建多尺度4D相关体,并通过一个循环单元迭代更新流场,该单元执行相关体积的查找。在KITTI上,RAFT的F1-all误差为5.10%,比已知的最佳结果6.10%,减少了16%。在Sintel上,RAFT获得的end-point-error为2.855像素,比已知最佳结果4.098像素,减少了30%。此外,RAFT算法具有较强的跨数据集泛化能力,在推理时间、训练速度、参数计数等方面具有较高的效率。
论文链接:https://arxiv.org/pdf/2003.12039.pdf本篇论文主要介绍了一种新的光流深度网络架构——递归全对场变换(RAFT)。RAFT提取每个像素特征,为所有像素对构建多尺度4D相关体,并通过一个循环单元迭代更新流场,该单元执行相关体积的查找。在KITTI上,RAFT的F1-all误差为5.10%,比已知的最佳结果6.10%,减少了16%。在Sintel上,RAFT获得的end-point-error为2.855像素,比已知最佳结果4.098像素,减少了30%。此外,RAFT算法具有较强的跨数据集泛化能力,在推理时间、训练速度、参数计数等方面具有较高的效率。 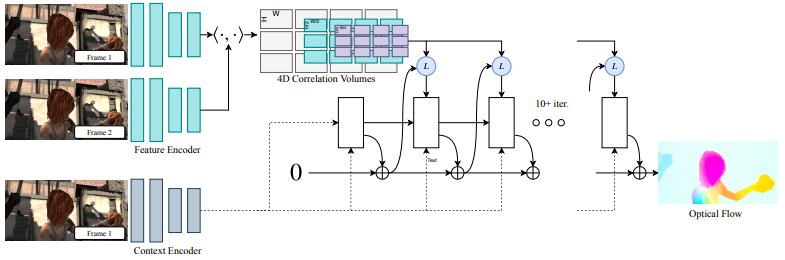 项目地址:https://github.com/princeton-vl/RAFT论文第一作者 Zachary Teed 是来自普林斯顿大学在读博士生,他的导师是邓嘉。同时, Zachary Teed是普林斯顿视觉与学习实验室(Princeton Vision & Learning Lab)的一名成员。他曾获得圣路易斯华盛顿大学的计算机科学学士学位。他的研究重点:从3D视频进行重建,包括运动,场景流和SLAM中的结构。个人主页:https://zachteed.github.io/我们熟知的邓嘉正是李凯和李飞飞教授的学生,ImageNet 首篇文章的第一作者。邓嘉现在在普林斯顿大学视觉与学习实验室任助理教授,主要研究方向为计算机视觉和机器学习,即通过感知、认知和学习相结合来实现人类层面的视觉理解。个人主页:https://www.cs.princeton.edu/~jiadeng/论文一:「Towards Streaming Image Understanding」
项目地址:https://github.com/princeton-vl/RAFT论文第一作者 Zachary Teed 是来自普林斯顿大学在读博士生,他的导师是邓嘉。同时, Zachary Teed是普林斯顿视觉与学习实验室(Princeton Vision & Learning Lab)的一名成员。他曾获得圣路易斯华盛顿大学的计算机科学学士学位。他的研究重点:从3D视频进行重建,包括运动,场景流和SLAM中的结构。个人主页:https://zachteed.github.io/我们熟知的邓嘉正是李凯和李飞飞教授的学生,ImageNet 首篇文章的第一作者。邓嘉现在在普林斯顿大学视觉与学习实验室任助理教授,主要研究方向为计算机视觉和机器学习,即通过感知、认知和学习相结合来实现人类层面的视觉理解。个人主页:https://www.cs.princeton.edu/~jiadeng/论文一:「Towards Streaming Image Understanding」  论文链接:https://arxiv.org/pdf/2005.10420.pdf这篇论文指出了标准离线评估和实时应用程序之间的一个差异,即当一个算法完成对特定图像帧的处理时,周围的世界已经发生了变化。研究者提出了一种方法,将延迟和准确度统一到一个用于实时在线感知的指标中,并将其称之为流式准确性(streaming accuracy)。此指标背后的关键洞察是在每个时刻联合评估整个感知堆栈的输出,迫使堆栈考虑在进行计算时应忽略的流数据。基于这个指标,研究者引入了一个元基准,它系统地将任何图像理解任务转换为流图像理解任务。针对城市视频流中的目标检测和实例分割,提出了一种具有高质量和时间密集标注的数据集。论文第一作者Mengtian Li是一位来自卡内基梅隆大学机器人研究所的博士生,曾获得南京大学学士学位。他的研究兴趣是计算机视觉和机器学习,特别对资源受限的深度学习和推理感兴趣。个人主页:http://www.cs.cmu.edu/~mengtial/论文二:「NeRF:Representing Scenes as Neural Randince Fields for View Synthesis」研究者们提出了一种通过使用稀疏输入视图集优化底层连续体积场景函数来获得合成复杂场景新视图的方法。研究者们描述了如何有效地优化神经辐射场,以渲染具有复杂几何和外观的真实感场景的新视图,并展示了优于先前神经渲染和视图合成的结果。Koenderink奖是来表彰十年对计算机视觉领域做出巨大贡献的经典论文。今年Koenderink奖授予以下两篇论文:论文一:「Improving the Fisher Kernel for Large-Scale Image Classification」
论文链接:https://arxiv.org/pdf/2005.10420.pdf这篇论文指出了标准离线评估和实时应用程序之间的一个差异,即当一个算法完成对特定图像帧的处理时,周围的世界已经发生了变化。研究者提出了一种方法,将延迟和准确度统一到一个用于实时在线感知的指标中,并将其称之为流式准确性(streaming accuracy)。此指标背后的关键洞察是在每个时刻联合评估整个感知堆栈的输出,迫使堆栈考虑在进行计算时应忽略的流数据。基于这个指标,研究者引入了一个元基准,它系统地将任何图像理解任务转换为流图像理解任务。针对城市视频流中的目标检测和实例分割,提出了一种具有高质量和时间密集标注的数据集。论文第一作者Mengtian Li是一位来自卡内基梅隆大学机器人研究所的博士生,曾获得南京大学学士学位。他的研究兴趣是计算机视觉和机器学习,特别对资源受限的深度学习和推理感兴趣。个人主页:http://www.cs.cmu.edu/~mengtial/论文二:「NeRF:Representing Scenes as Neural Randince Fields for View Synthesis」研究者们提出了一种通过使用稀疏输入视图集优化底层连续体积场景函数来获得合成复杂场景新视图的方法。研究者们描述了如何有效地优化神经辐射场,以渲染具有复杂几何和外观的真实感场景的新视图,并展示了优于先前神经渲染和视图合成的结果。Koenderink奖是来表彰十年对计算机视觉领域做出巨大贡献的经典论文。今年Koenderink奖授予以下两篇论文:论文一:「Improving the Fisher Kernel for Large-Scale Image Classification」  论文链接:https://lear.inrialpes.fr/pubs/2010/PSM10/PSM10_0766.pdfFisher内核(FK)是一个通用框架,它结合了生成和区分方法的优点。在图像分类的背景下,FK被证明超越了计数统计,扩展了流行的视觉单词包(BOV)。然而,在实践中,这种丰富的代表性还没有显示出它优于BOV。在第一部分中,研究者展示了在原始框架的基础上,通过一些动机良好的修改,可以提高FK的准确性。在第二部分中,作为应用,研究者比较了ImageNet和flickrgroups这两个丰富的标记图像资源来学习分类器。在一项涉及数十万个训练图像的评估,结果发现,Flickr组中学习的分类器表现出色,而且它们可以补充在更仔细注释的数据集上学习的分类器。论文二:「Brief:Binary robust independent elementary featueres」
论文链接:https://lear.inrialpes.fr/pubs/2010/PSM10/PSM10_0766.pdfFisher内核(FK)是一个通用框架,它结合了生成和区分方法的优点。在图像分类的背景下,FK被证明超越了计数统计,扩展了流行的视觉单词包(BOV)。然而,在实践中,这种丰富的代表性还没有显示出它优于BOV。在第一部分中,研究者展示了在原始框架的基础上,通过一些动机良好的修改,可以提高FK的准确性。在第二部分中,作为应用,研究者比较了ImageNet和flickrgroups这两个丰富的标记图像资源来学习分类器。在一项涉及数十万个训练图像的评估,结果发现,Flickr组中学习的分类器表现出色,而且它们可以补充在更仔细注释的数据集上学习的分类器。论文二:「Brief:Binary robust independent elementary featueres」  论文链接:https://www.cs.ubc.ca/~lowe/525/papers/calonder_eccv10.pdf研究者提出使用二进制字符串作为一个有效的特征点描述符,并将其称之为BRIEF。研究表明,即使使用相对较少的比特,它仍然具有很高的分辨力,并且可以通过简单的强度差分测试来计算。除此之外,可以使用汉明距离来评估描述符相似度,这是非常有效的计算,而不是像通常所用的L2范数。因此,BRIEF的构建和匹配都非常快。最后,研究人员将其与标准基准测试中的SURF和U-SURF进行了比较,结果表明它产生了相似或更好的识别性能,而运行时间只需其中一个的一小部分。Mark奖的设立是为了纪念在2012去世的Mark Everingham,他在The PASCAL Visual Object Classes (VOA)数据集做出主要贡献,也是该比赛项目的发起人。同时,Mark奖的设立也是为了激励后来者在计算机视觉领域做出更多贡献。今年第一位获得PAMI Mark Everingham 奖的是 Antonio Torralba 和多数据集的合作者,为了表彰他们持续了十多年定期发布新的数据集和创建这些数据集的新方法。这些数据集包含Tiny images,SUN/SUN-3D,MIT-Places,创建数据集新方法的工具包括LabelMe,它们已经在视觉领域影响深远。个人主页:https://groups.csail.mit.edu/vision/torralbalab/ 今年第二位获得PAMI Mark Everingham 奖的是 COLMAP SFM 和 MVS 软件库的提出人Johannes Schonberger,以表彰他为3D重建图像提出的一个开源的端到端pipeline,并为之提供的支持、开发与编写文档。「Inter-Homines: Distance-Based Risk Estimation for Human Safety」
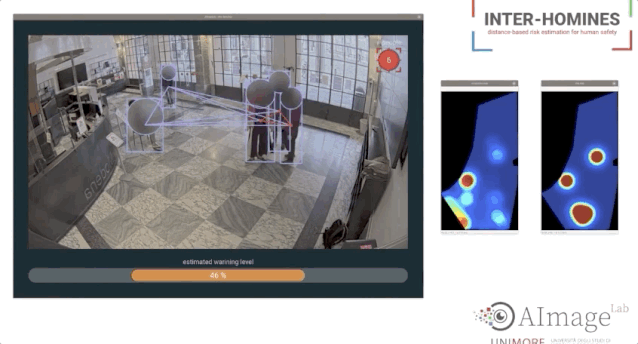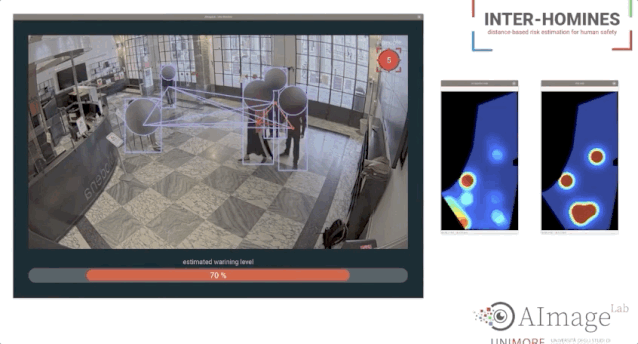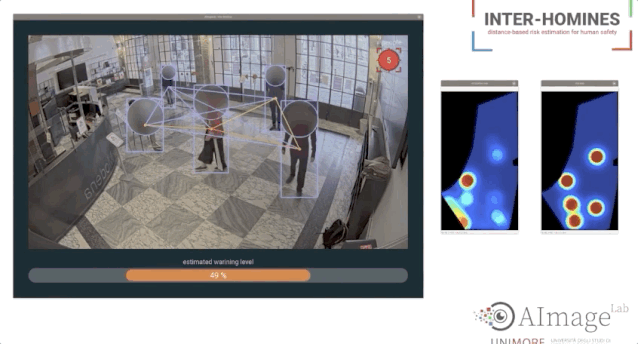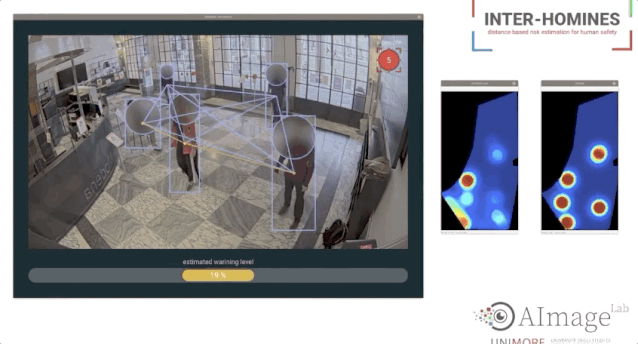
论文链接:https://www.cs.ubc.ca/~lowe/525/papers/calonder_eccv10.pdf研究者提出使用二进制字符串作为一个有效的特征点描述符,并将其称之为BRIEF。研究表明,即使使用相对较少的比特,它仍然具有很高的分辨力,并且可以通过简单的强度差分测试来计算。除此之外,可以使用汉明距离来评估描述符相似度,这是非常有效的计算,而不是像通常所用的L2范数。因此,BRIEF的构建和匹配都非常快。最后,研究人员将其与标准基准测试中的SURF和U-SURF进行了比较,结果表明它产生了相似或更好的识别性能,而运行时间只需其中一个的一小部分。Mark奖的设立是为了纪念在2012去世的Mark Everingham,他在The PASCAL Visual Object Classes (VOA)数据集做出主要贡献,也是该比赛项目的发起人。同时,Mark奖的设立也是为了激励后来者在计算机视觉领域做出更多贡献。今年第一位获得PAMI Mark Everingham 奖的是 Antonio Torralba 和多数据集的合作者,为了表彰他们持续了十多年定期发布新的数据集和创建这些数据集的新方法。这些数据集包含Tiny images,SUN/SUN-3D,MIT-Places,创建数据集新方法的工具包括LabelMe,它们已经在视觉领域影响深远。个人主页:https://groups.csail.mit.edu/vision/torralbalab/ 今年第二位获得PAMI Mark Everingham 奖的是 COLMAP SFM 和 MVS 软件库的提出人Johannes Schonberger,以表彰他为3D重建图像提出的一个开源的端到端pipeline,并为之提供的支持、开发与编写文档。「Inter-Homines: Distance-Based Risk Estimation for Human Safety」  论文链接:https://arxiv.org/pdf/2007.10243.pdf在新冠疫情肆意传播情况下,本篇论文的研究者们提出了一个Inter-Homines系统,该系统可以通过分析视频流来实时评估受监视区域中的传染风险。1 FingerTrack:Continous 3D Hand Pose Trackinghttps://dl.acm.org/doi/abs/10.1145/33973062 Object Detection Kit:Identifying Urban Issues in Real-time https://dl.acm.org/doi/abs/10.1145/3372278.3390708
论文链接:https://arxiv.org/pdf/2007.10243.pdf在新冠疫情肆意传播情况下,本篇论文的研究者们提出了一个Inter-Homines系统,该系统可以通过分析视频流来实时评估受监视区域中的传染风险。1 FingerTrack:Continous 3D Hand Pose Trackinghttps://dl.acm.org/doi/abs/10.1145/33973062 Object Detection Kit:Identifying Urban Issues in Real-time https://dl.acm.org/doi/abs/10.1145/3372278.3390708
ECCV 2020 华人学者入围情况,阿里张磊位列第一
据Aminer统计,来自阿里达摩院的张磊教授,共入选8篇论文,位列第一。排在第二位是澳大利亚阿德莱德大学教授沈春华,入选论文7篇。第三名是默罕默德·本·扎耶德人工智能大学副校长邵岭教授入选论文共6篇。第四名是来自香港中文大学林达华教授,共有5篇论文入选。并列第五的华人学者有:来自华为诺亚方舟实验室田奇和谢凌曦,微软亚洲研究院王井东和Zheng Zhang,香港大学罗平。
近年来,计算机视觉大热,直接导致三大顶会:ICCV、CVPR、ECCV的论文接收暴涨,可以用「爆仓」来形容。今年主办方共收到5150篇有效文章,数据为ECCV 2018的两倍还多,再创新高。最终有1360篇文章被接收发表,接收率仅26%,不到三成,较上届31.8%有所下降。在最终接收论文中,Oral论文104篇,占提交总量的2%;Spotlights论文160篇,占提交总量的5%;剩余1096篇为poster。从每个领域的论文接收数量可以看出深度学习和识别在ECCV中仍是主要研究对象,机器学习位居第三。再从各个机构录取论文作者数量来看,谷歌,香港中文大学、北大、清华、Facebook居前五。据不完全统计,谷歌在本届ECCV 2020会议上被接受的论文有50篇,Facebook约有41篇论文被接受。腾讯 AI Lab 共有 16 篇论文被 ECCV 2020 收录,其中包括 1 篇 Oral 展示论文和 2 篇 Spotlight 展示论文,涵盖腾讯AI Lab 近年来重点研究的多模态学习、视频内容理解、对抗攻击与对抗防御、基于生成模型的图像编辑等课题。旷视共有 15 篇成果入选,其中包含Oral 论文 2 篇、Spotlight 论文 1 篇,刷新了上届入选 10 篇的纪录。入选论文中涵盖:图像检测、图像对齐、姿态估计、激活函数、CNN架构设计、动态网络、NAS、知识蒸馏、点云配准、细粒度图像检索、迁移学习等众多学术热门领域,并取得突破性进展。百度AI 团队共入选10篇论文,其中1篇Oral和1篇Spotlight论文,涵盖了自动驾驶识别&定位、声源定位&场景识别、目标跟踪、多模态&度量学习等众多领域,彰显了AI领军者的风范和深厚的技术底蕴以及持续创新能力。腾讯优图实验室共入选8篇论文,涵盖目标跟踪、行人重识别、人脸识别、人体姿态估计、动作识别、物体检测等热门及前沿领域,再次展示了腾讯在计算机视觉领域的科研及创新实力。
参考链接:
https://eccv2020.eu/
https://www.aminer.cn/conf/eccv2020