
海华 AI 挑战赛·中文阅读理解 | 北大选手的 BERT 方案分享
本文是针对 海华AI挑战赛的基于 BERT 的 baseline 介绍。海华 AI 挑战赛由清华大学交叉信息研究院和中关村海华信息技术前沿研究院联合主办,总奖金30万元。
本次比赛的 baseline 代码模型可以访问:https://www.biendata.xyz/models/category/6353。
本次比赛仍在进行中,比赛页面可以访问“阅读原文”。
主讲人简介:朱政烨,北京大学本科学生,数据科学专业,对深度学习尤其是自然语言处理感兴趣。曾多次获得国内数据竞赛 TOP5 以及 Kaggle 奖牌。
1 赛题引入与分析
本次比赛的任务是机器阅读理解,作为自然语言处理领域的重要课题,近年来吸引了越来越多的研究者关注。概括来讲,它主要分为完形填空,答案抽取,多项选择和自由问答这几种类型。其中多项选择就是本次比赛的任务,它旨在使模型根据文本和问题在多个选项中选择正确的一个。

上图是一组数据的示例,它来自于中高考的语文阅读理解题库,包含一篇文章,至少一个问题和多个候选选项。我们要做的,就是搭建模型,从这些选项中选出正确的一个。
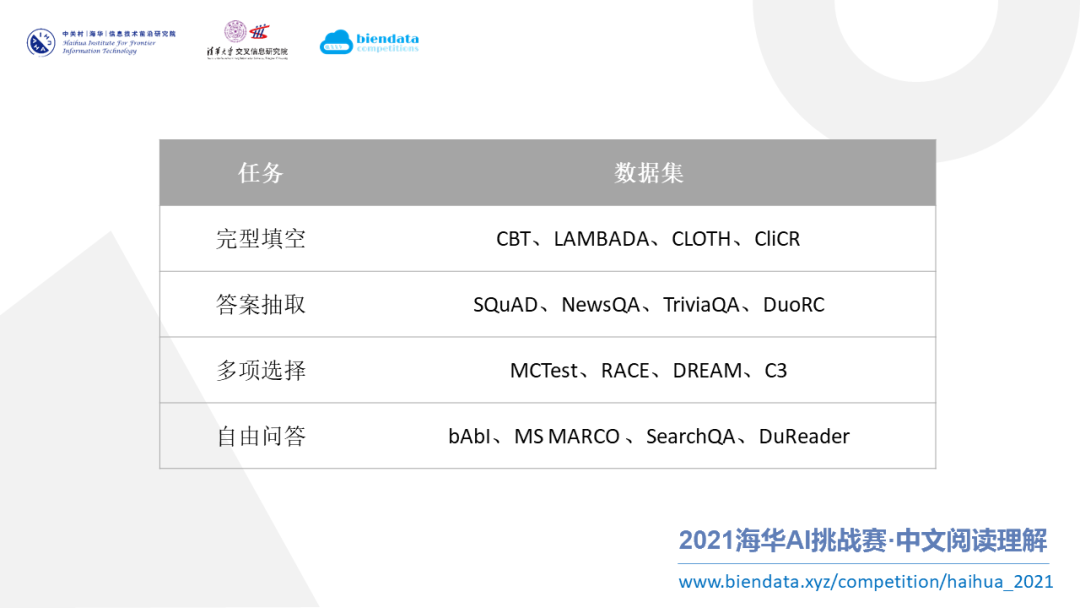
上图显示的是机器阅读理解领域的重要数据集和类型。本次比赛针对的是多项选择的阅读理解任务。多项选择的数据集,英文数据集有 MCTest、RACE、DREAM,中文的数据集有 C3。通过这些数据集,可以进而搜索相关的论文,找到一些方法,帮助我们提升模型的效果。

了解完任务之后,再回过头来看比赛。本次比赛其实有几个难点。
第一个难点是文体的多样性,这次比赛的文体有现代文、文言文,还有一些诗词,这些文体对于目前已有的一些预训练语言模型会形成一定的挑战。
第二个难点是问题不仅有字词解释和标点符号的作用,部分问题还涉及到态度情感以及外部知识。如上图所示,有些问题不需要先验知识(外部知识),因为它是能够在原文中匹配到的,这样的问题回答起来就很简单,目前的模型也都很容易做到。但有些问题它需要外部知识,比如说需要关于语言的知识(例如词汇或语法知识),或特定领域的知识。还有一些问题包含了一般世界的知识,也就是生活中的常识。对于这些外部知识,已有的预训练语言模型的语料可能不包含需要的外部知识。这种情况也是本次比赛的一个难点。
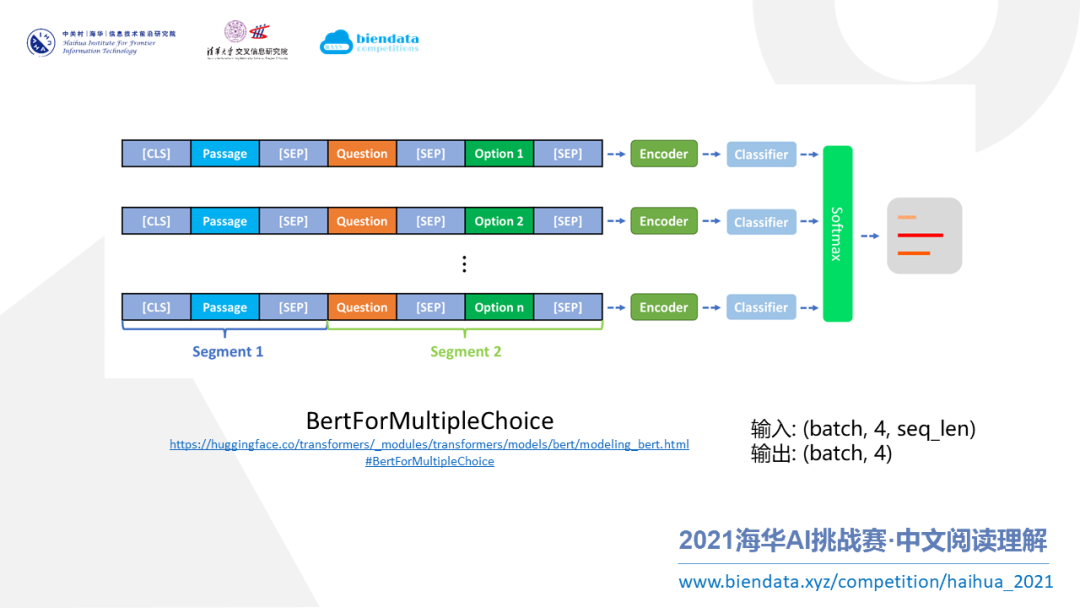
上图是针对本次比赛,我所使用模型(BertForMultipleChoice)的架构图。
概括来讲,这个模型首先把数据中的多个选项做拆分处理,把拆分出来的每个选项和文本以及问题(也就是图中的Passage,Question,Option)拼在一起,形成一条语句(也就是图中的一行)。这样,个选项就形成条语句,也就是行。然后把这个语句送入 Encoder 产出得分,并把个得分拼接起来经过Softmax来得到维概率,也就是一个分类的输出。
这种模型是多项选择阅读理解任务中一种很通用的模型,它已经在常用的 Transformer 库中内置了,叫 BertForMultipleChoice(访问上图下方的链接可以查看 BertForMultipleChoice 的源码)。
所以,总结一下就是,给模型输入1)batch size 、2)选项个数、3)每个选项的句子长度。输出就是 4 个选项的得分,也就是 batch size * 4 的概率。
2 数据处理与可视化
基本方案讲完了,我们来看一下数据处理与可视化。这个比赛的官方数据形式是 json 文件,为了处理方便,我把它转成了一个 pandas 表格,有表头,每一行代表一个数据。

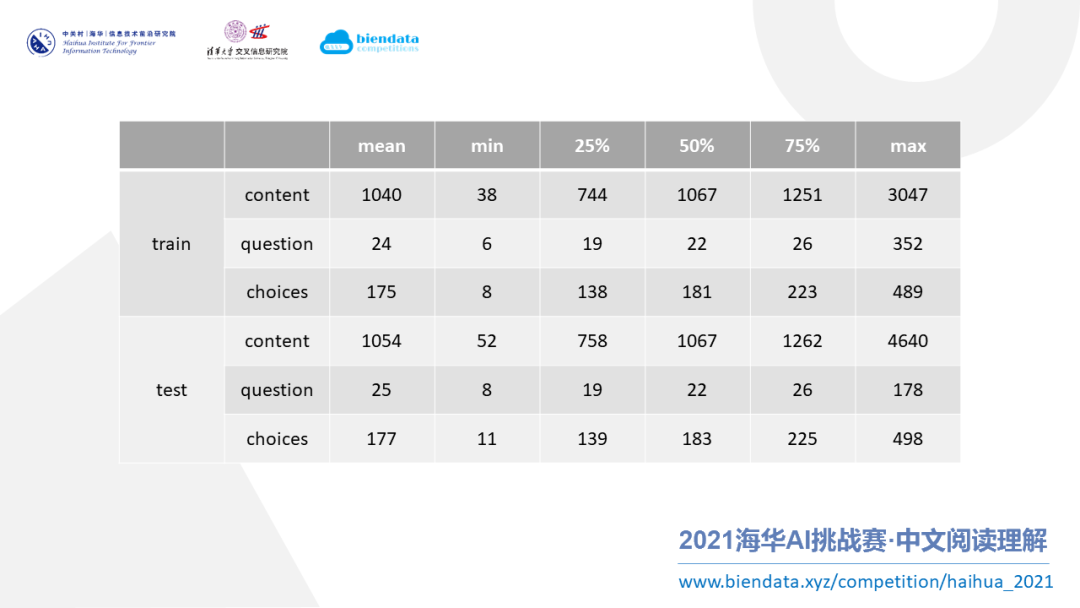
有了清晰明了的表格,就能比较方便的统计信息了。首先是最重要的文本长度,分别对训练集和测试集进行统计,包括 content(文章)、question(问题)和 choice(选项)这三类。通过统计,我们发现文章的长度很长,平均长度达到了 1040,question 相对较短的只有 20 左右,choice 也比较长,有 100 到 200 多的样子。
把上述 3 项拼接起来作为模型的输入,它的长度总是在 1000 以上。对于大部分最大长度限制在 512 的预训练模型来说,这会是一个比较大的挑战。
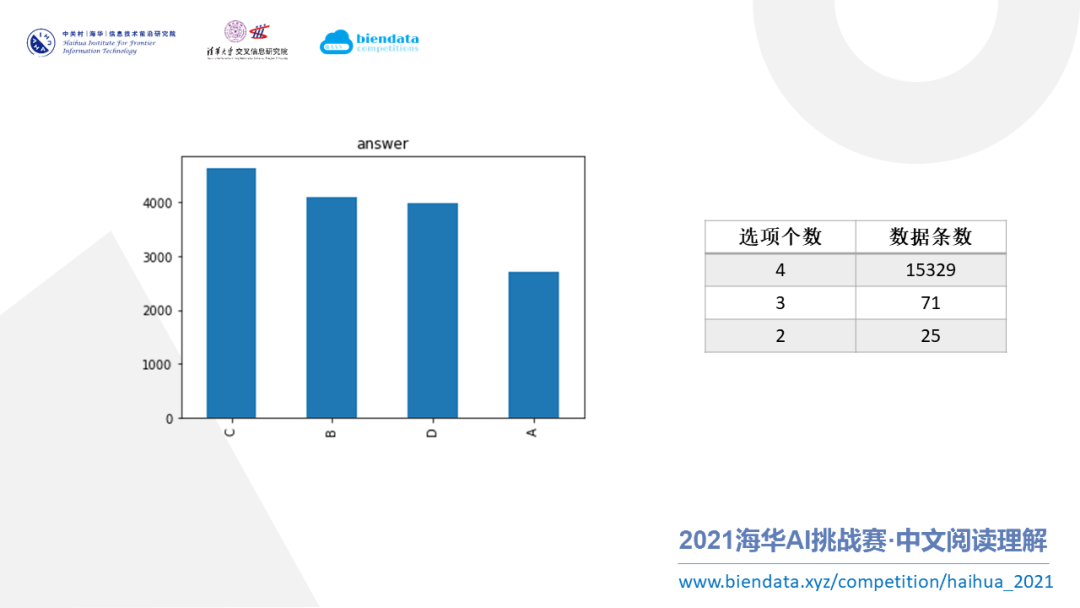
接下来对选项做一些统计。首先是答案的个数分布,从上图可以看到选 C 是最多的,全选 C 也能达到 30% 左右的准确率,这也跟我们的常识相符。
在选项的个数上,统计发现绝大部分是4选项,剩下很少的 3 选项或者 2 选项。对于少部分非 4 选项的数据,可以手动添加选项,给它们补齐到 4 个然后再输入模型。
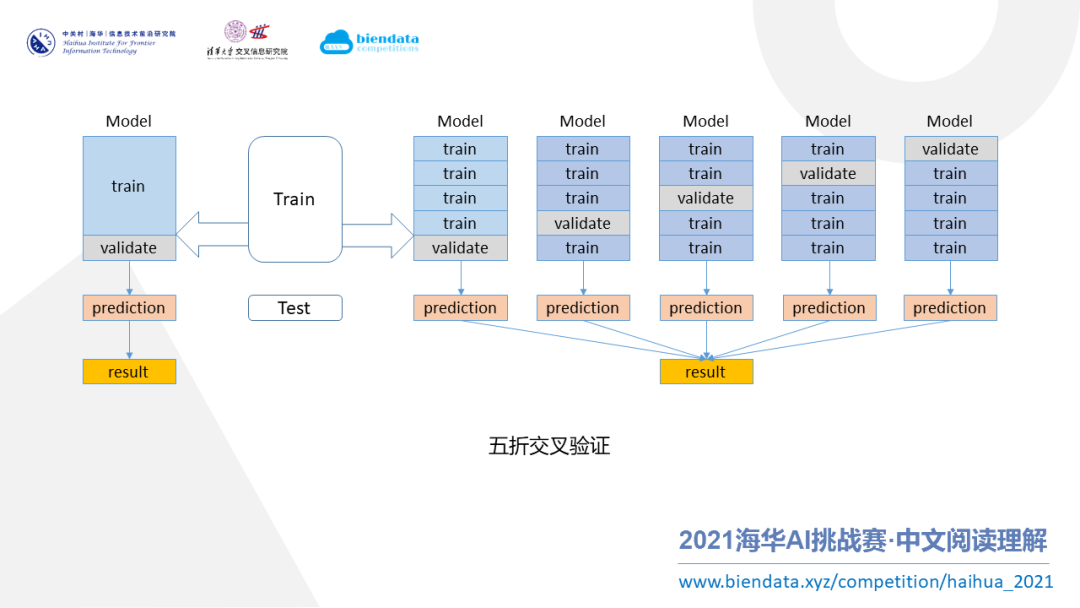
对数据的划分,我采用了“五折交叉验证”方法。如上图所示,把整个训练集重新划分成 5 份,依次把每份当成一份验证集,这样就可以训练出 5 个模型。
这种做法的好处是既能利用多折模型的融合来提高得分,又能使数据得到充分的利用。
3 Baseline 代码讲解
接下来是这次分享的重点,baseline 代码讲解。这份代码在大赛官网的 models 页面里,可以输入上图中的网址或者扫描上图中的二维码查看。
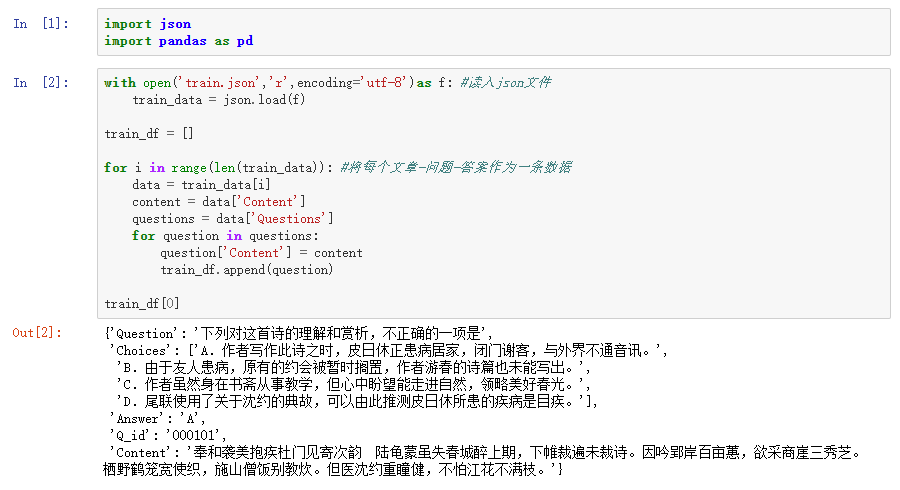
从数据预处理开始,首先把 json 文件 加载出来,然后解码。原本的文件是每个文章下有多个问题,我们把多个问题给它拆成单个问题。这样每个 文章 + 问题 + 答案 就可以作为一条数据保存起来。
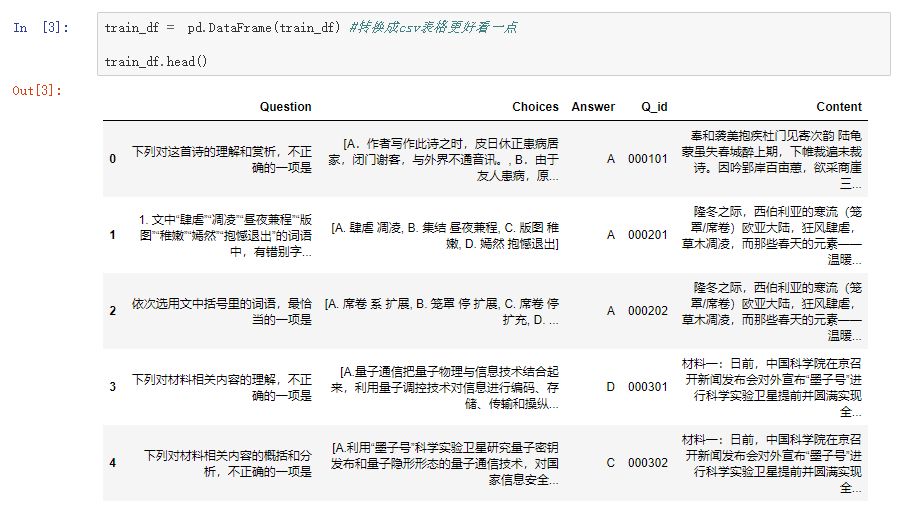
接下来把这样的数据转化成表格的形式,以便我们后续的分析和处理。

对验证集也做同样的操作,会发现多出两栏叫 Type 和 Diff,这两项分别代表了文章的种类和难度,是训练集没有的。

接下来是主要的代码部分,首先导入需要的一些常用库,然后定义一些训练所需要的参数配置。
一个一个看:
fold_num 是这个交叉验证所用的折数,这里我设置为常用的 5 seed 是随机种子,这个采用了随机种子固定的方法使结果可复现 model 是模型,在这里我采用了哈工大实验室所训练的一个 BERT 预训练模型 max_len 是文本阶段的最大长度,在这里我设置为 256,这是能够覆盖到大部分问题和答案,但是覆盖不了文章的长度 epochs 是训练的轮数,我设置为 8 train_bs 和 valid_bs 是 batch_size,可以根据自己机器来调整 lr 是学习率,我设置为 BERT 常用的 2e-5 num_workers 是多线程的个数,这个没有什么影响 accum_iter 是梯度累积的参数,在这里我采用梯度累加等于 2,也就相当于是每两步才更新一次参数 weight_decay 是权重筛减,是用来防止过拟合的
以上就是参数的设置。

接下来是一些初始化,首先固定一下随机种子,各个有出现随机性的地方,都把种子设置成统一的,并把 device 设置成 GPU。
接着读入训练集跟验证集的 CSV 表格。对于这些表格有一点要注意,它的标签是 ABCD,这样的字母标签是无法进行训练的,所以我们要把它转化成 0123 这样的数字标签。

接下来加载 BERT 的分词器,它能够把汉字转化成数字 ID 输入进模型。
下面是数据集的部分,数据集能够帮助我们把表格转化成我们要输入的数据。在这里我们注意到每个表格其实是文章 + 问题 + 4 个选项。所以再进行进一步的拆分,把 4 个选项拆分出来,也就是说转化成文章 + 问题 + 选项一,以及文章 + 问题 + 选项二,直到文章 + 问题 +选项四。

接下来这个函数叫 collate_fn,作用是把多条数据整理到一起。这里开始使用 BERT 的分词器把题和选项放在前面,把文章放在后面,这样的拼接方式能够尽量减少每一个信息的损失。
然后会返回分词,包括:
1)input_ids,作用是把汉字转成数字 ID 2)attention_mask,作用是把不足 256 长度的文本用 0 来补齐 3)token_type_ids,作用是把问题和选项标成第一段,把文本标成第二段,有助于模型的学习
把返回的 3 个输入和 label 全部转换成张量,这样 dataset 就能转化成 size 里的数据。

关于训练函数,首先定义一个类,它的作用是实时统计 loss 和 acc 的平均值并显示在进度条上。
接下来是训练的主体函数,它的作用是对模型训练一个 epoch。
首先初始化 loss 和 acc,然后把训练数据包装上一层进度条,方便查看进度。接下来对训练数据进行枚举,每一个 base 包含 input_ids,attention_mask 和 token_type_ids,它们全都是我们所需要的输入。y 是一个 label。
接下来采用半精度训练的方法,它的好处是能够有效减少显存占用,以及加快训练速度,而且不会影响训练进度。
把输入放进模型里得到输出,这个输出就类似于 4 分类的一个概率,把它和标签相结合得到我们的损失。
这里有一点要注意,如果我们使用梯度累加的话,我们这里的损失必须要除以一个梯度累加的数值。
然后每步更新一下准确率和损失函数。

接下来是进入训练,首先固定随机的种子,然后采取 5 折交叉验证。
保存下每折的最佳准确率,然后进入循环。对于每一折都划分成一个训练集跟验证集进行批量训练。
因为前面已经把数据处理好了,所以模型可以直接调用 BertForMultipleChoice。
然后设置几个常用的初始化,包括:
优化器,采用了 Adam 优化器 损失函数,采用了 CrossEntropyLoss 学习率的调整策略,采用了 get_cosine_schedule_with_warmup
然后就是主体 epoch 的循环,对每个 epoch 都得到一个训练的损失和准确率,以及一个验证的损失和准确率,如果遇到最佳准确率,就保存下来。

保存了每折的模型之后,就可以进行推理了。首先定义测试集,给它套上 Dataset 和 DataLoader,然后分别加载训练好的 5 个最佳模型,进行一遍推理,把输出保存到 predictions 里面。
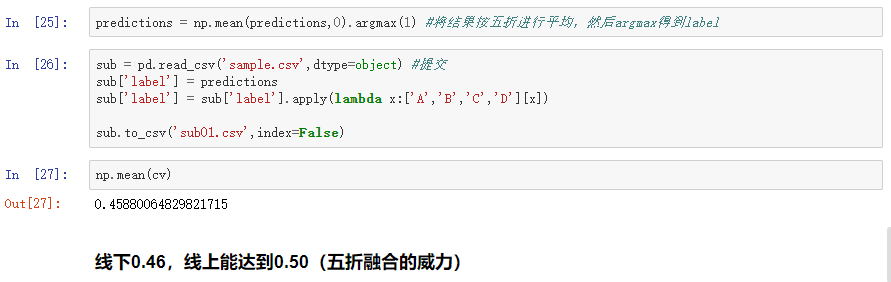
在保存了 5 个模型的输出之后,把它进行平均,这个操作能够降低每个模型的方差,以达到更好的效果。当我们想要得到标签时,要先进行一个 argmax 操作,得到数字标签后再把得到的结果映射到 A、B、C、D 上,然后存到提交文件里。
以上就是 baseline 的代码讲解。
4 进阶提升
上文讲到的 baseline 其实就是简单地调用了 BertForMultipleChoice,参数也是比较基础的参数,那么怎么在这个基础上进一步提升呢?

可以从以下这几个角度来尝试:
第一个,更长的文本。baseline 采用的截断长度是 256,那我们自然可以把它增大,增大到512,也就是模型最大长度。如果 512 还不行,可以采用滑动窗口的方式,把很长的文章从前往后截成很多段,对这些截出来的段进行之前那样的操作,然后把这些段汇总(比如说取个平均或者取一个最大)。这样就可以得到一个很长文本的结果,这个是对于长文本的一个常用操作,叫 sliding window。
另外有些模型是不限制长度的,但是你使用这类模型的时候,训练时间会长很多,比较耗运算资源。
还有一个比较有名的是 longformer,它支持最大为 4096 的长度,transformers 库里面也是有这个中文模型的,大家如果有余力的话可以看一下怎么使用这个模型。
第二个,更好的模型。我们可以在之前 BERT 的基础上,改用更好的 roberta 模型,或者把原来的 base 模型换成 large 模型,再或者我们可以改变模型的结构。
关于改变模型结构,可以看一下 RACE 数据集上面的一些方法,比如说 DCMN 还有 DUMA。DUMA 其实就是在普通的 BERT 上面进一步给一个交互 attention,具体对应到本次比赛就是把问题、选项和文章给单独切成两半,然后把这两半做一个处理(相当于在 BERT 上面叠一个 BERT) ,这样就能捕捉到更深层次的交互信息。
以上就是进一步提升的几个要点。
报名参加 2021 海华 AI 挑战赛请点击下方阅读原文↓