
智慧支付挑战赛一等奖方案分享

今天和大家分享的是前不久老肥我参加的银联商务和华东理工商学院一起举办的智慧支付挑战赛,本次比赛我也是单人参加,最终很高兴收获了一等奖的好成绩。
赛题分析
本次挑战赛的目标是设计一个基于商户静态属性和交易信息的商户流失预测模型,即通过模型预测测试集的商户在未来一个月内是否流失,评价的指标为F1。
这是一个主从表问题,主表包含商户静态属性信息,副表包含商户交易流水信息。
其中初赛给的训练集为4、5、6月的交易流水数据来预测7月份商户是否流失,决赛的训练集为5、6、7月的交易流水数据来预测8月份商户是否流失。为了同时利用到初赛和决赛的训练集,我们需要先对日期进行对准操作,初赛训练集4月对应预测月前第三月,5月训练集5月也对应预测月前第三月。
解决方案
首先是数据预处理部分,数据缺失值占比较小,对于类别变量我们做统一字符串填充,数值变量不做任何处理。对于不在统计周期内的数据予以删除。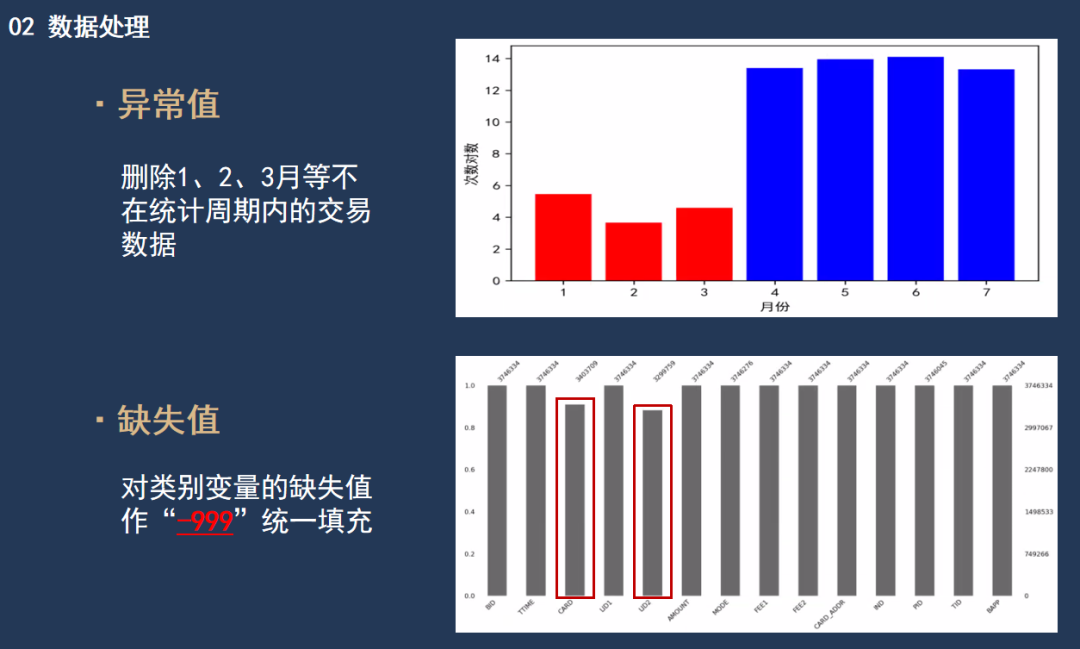
然后是最重要的部分-特征工程,我通过从季度到月到周到日再到小时,从粗粒度到细粒度对商户的交易流水进行特征提取。统计特征的提取包括两类,一类是类别变量,我们统计其nunique、count,即种类和数量,另一类是数值变量,我们统计其最大最小均值方差等等。
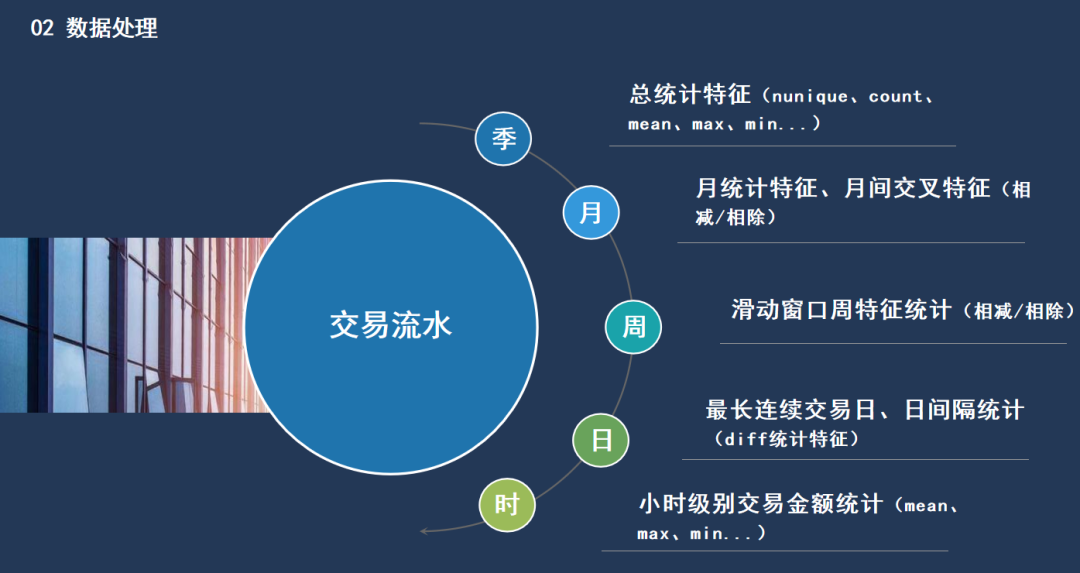
月份之间的特征进行交叉,通过相减相除刻画出商户交易金额随月份变化的表现,使用滑动窗口对预测月前一个月内的每一周的数据进行统计、交叉。对于日级别的特征提取,我们采用交易间隔日期的统计以及最长连续交易日来实现。
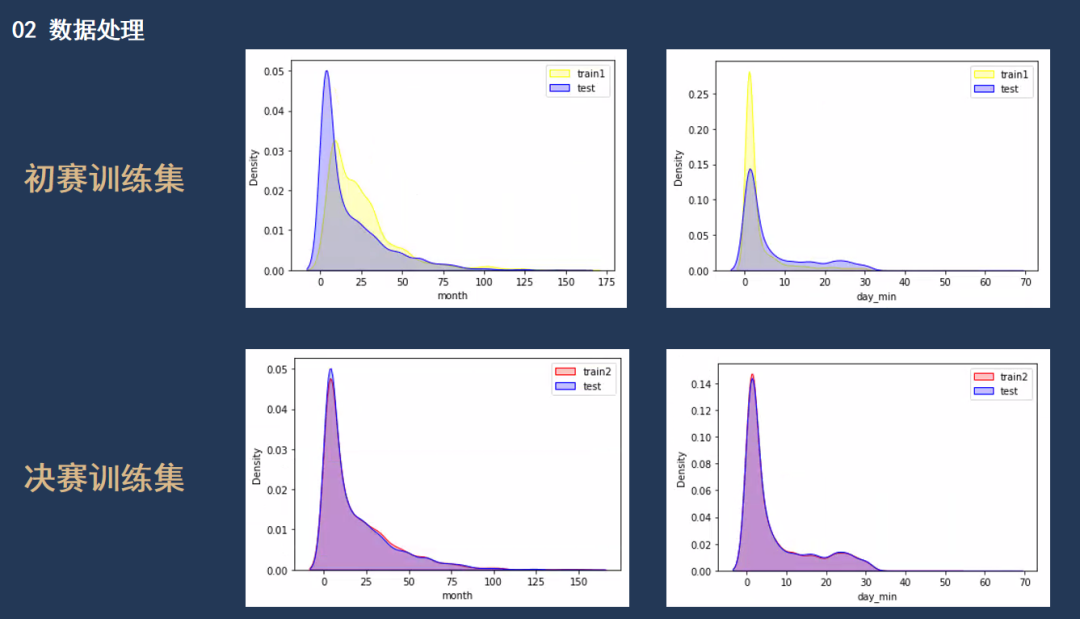
通过观察初赛训练集与决赛训练集我发现前者与测试集存在非常明显的分布不一致的问题,而后者与测试集的分布则非常相似。这里就面临两难的抉择,是把初赛训练集也用上一起训练模型还是单独使用决赛训练集来避免分布不一致造成的线上线下成绩不一致的问题。我认为数据的优先级更高,我2W数据大概率比只用1W数据的要强。为了能够更好的利用数据,我额外新增一列特征,用它来表明数据的来源,让模型自己学习不同的分布。
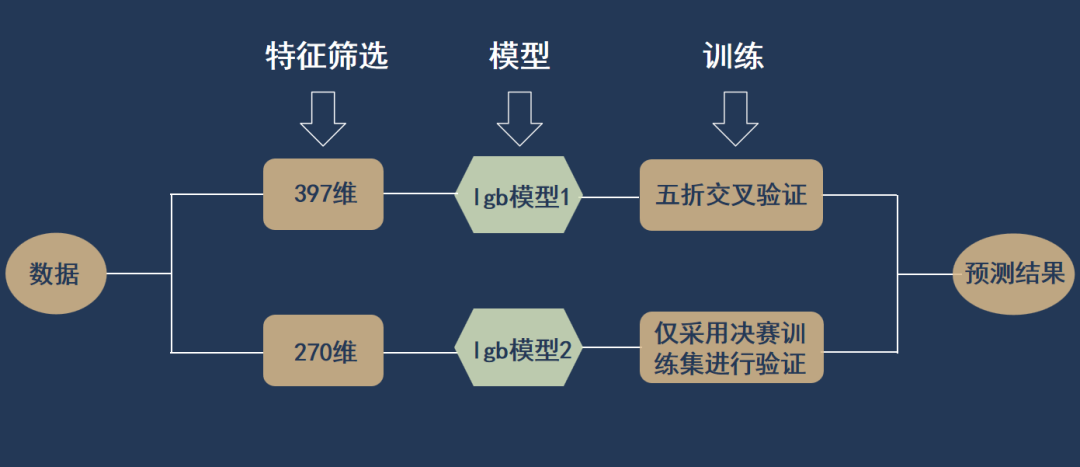
我选择了使用两个lgb模型进行概率平均融合。两个模型都采用了相同的总特征以及相同的参数,但是特征使用情况不同、训练方法不同。首先是特征的不同之处,第一个模型根据树模型的特征重要性对473维基础特征进行筛选,使用了重要性大于0.2的共计397维特征,而第二个模型根据null importance的特征选择方法,最后使用筛选出的共计270维特征;然后是训练方法的不同之处,第一个模型使用初赛训练集以及决赛训练集作为全部的训练集,进行五折交叉验证,而第二个模型在使用初赛训练集以及决赛训练集的同时,只采用决赛训练集作为验证集。
在经过现场答辩环节之后,我发现得分较高的选手采取的特征工程方法都较为相近,其中@挥霍同学提出使用额外数据(行业分类信息)做tfidf统计对模型性能有显著提升,看来对补充材料的特征挖掘会有意想不到的收获。
以上就是文章的全部内容了,本文的所有代码已经上传,在后台回复「银联」即可。
——END——
扫码二维码
获取更多精彩
老肥码码码
