
2019天池县域农业大脑AI挑战赛冠军方案分享
【GiantPandaCV导语】本科毕业暑假到研究生开学的空档期,心血来潮地想找个比赛试水。本文是笔者在比赛过程中关于赛题的一些记录和思考,赛后整理总结,希望对有也有兴趣参加数据竞赛的学弟学妹能有所帮助。由于笔者第一次接触图像分割任务,知识水平有限,如有理解错误的地方欢迎指正,感激不尽。
比赛主页:
2019 年县域农业大脑AI挑战赛-天池大赛-阿里云天池: https://tianchi.aliyun.com/competition/entrance/231717/introduction
相关代码:
github: https://github.com/lin-honghui/tianchi_CountyAgriculturalBrain_top1
线上demo:
天池7号馆: https://tianchi.aliyun.com/museum7/?spm=5176.14046517.J_9711814210.24.330d3178iIJT5o#/newprodetail?productId=4
0. 团队信息
团队名称:冲鸭!大黄 团队成员:施江玮、黄钦建、林宏辉(now_more: https://tianchi.aliyun.com/home/science/scienceDetail?userId=1095279428856)
1. 赛题分析
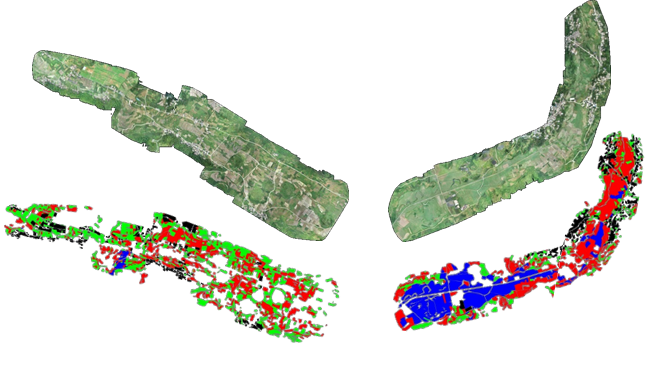
赛题任务: 通过无人机航拍的地面影像,探索农作物分割的算法,降低对人工实地勘察的依赖,提升农业资产盘点效率。具体分割类别为薏仁米、玉米、烤烟、人造建筑(复赛新增),其余所有目标归为背景类;
赛题数据: 初赛与复赛提供的是同一片区域不同时期的无人机航拍影像,初赛数据大多为农作物生长的早期,特征不明显,分割难度较大;复赛数据农作物长势良好,并在初赛赛题基础上增加了“建筑”类别;
评估指标: mIoU
难点分析: 类别不平衡、类间相似性、农作物新地形场景泛化、标注噪声
2. 整体方案
2.1 数据预处理
2.1.1 滑窗裁剪
比赛提供的原始数据为分辨率几万的PNG大图,需对原始数据预处理,本次比赛中我们采取的是滑窗切割的策略,主要从以下三个方面考量:
类别平衡: 过滤掉mask无效占比大于7/8的区域,在背景类别比例小于1/3时减小滑窗步长,增大采样率; patch: 实验中没有观察到patch对模型性能有显著影响,最后采取策略同时保留1024和512两种滑窗大小,分别用来训练不同的模型,提高模型的差异度,有利于后期模型集成; 速度: 决赛时算法复现时间也是一定的成绩考量,建议使用gdal库,很适合处理遥感大图的场景。本地比赛中我们直接多进程加速opencv,patch为1024时,单张图5~6min可以切完;
最终采取的切割策略如下:
策略一: 以1024x1024的窗口大小,步长900滑窗,当窗口中mask无效区域比例大于7/8则跳过,当滑动窗口中背景类比例小于1/3时,增加采样率,减小步长为512; 策略二: 以1024x1024的窗口大小,步长512滑窗,当滑动窗口中无效mask比例大于1/3则跳过。
2.2.2 数据增强
数据增强只做了常规的数据增强,如:RandomHorizontalFlip、RandomVerticalFlip、ColorJitter等。由于数据采集场景是无人机在固定高度采集,所以目标尺度较为统一,没有尝试scale的数据增强。
2.2 模型选择
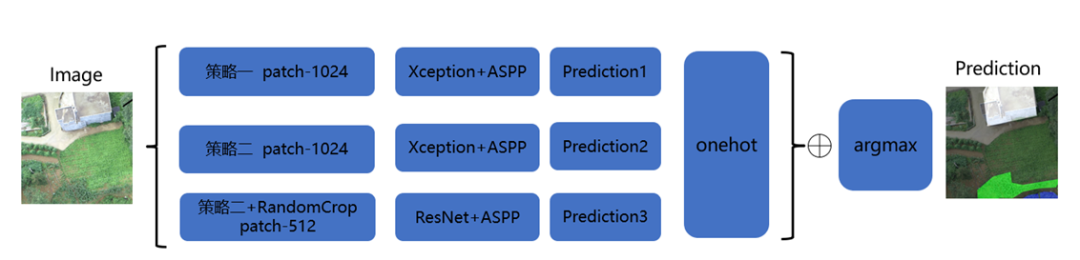
模型上我们队伍没有做很多的尝试,下表整理了天池、Kaggle一些分割任务中大家常用的方案。初赛尝试过PSPNet、U-Net等方案,但没有调出比较好的分数,复赛都是基于DeeplabV3+(决赛5个队伍里有4个用了DeeplabV3plus)backbone为Xception-65、ResNet-101、DenseNet-121。从复赛A榜分数提交情况,DenseNet-121 backbone 分数略高于另外两个,但显存占用太大以及训练时间太长,在后来的方案里就舍弃了。本次赛题数据场景为大面积农田预测,直接用deeplabV3plus高层特征上采样就有不错的效果,结合了底层特征预测反而变得零散。决赛算法复现时,使用了两个Xception-65和一个ResNet-101投票,投票的每个模型用不同的数据训练,增加模型差异。


3. 涨分点
3.1 膨胀预测
方格效应:比赛测试集提供图像分辨率较大,无法整图输入网络。如果直接无交叠滑窗预测拼接,得到的预测结果拼接痕迹明显。
原因分析:网络卷积计算时,为了维持分辨率进行了大量zero-padding,导致网络对图像边界预测不准。
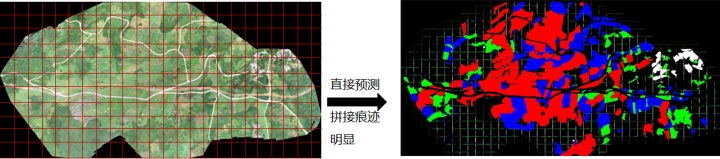
膨胀预测:采用交叠滑窗策略(滑窗步长<滑窗窗口大小),预测时,只保留预测结果的中心区域,舍弃预测不准的图像边缘。
具体实现:
填充1 (黄色部分) : 填充右下边界至滑窗预测窗口大小的整数倍,方便整除切割; 填充2(蓝色部分) : 填充1/2滑窗步长大小的外边框(考虑边缘数据的膨胀预测); 以1024x1024为滑窗,512为步长,每次预测只保留滑窗中心512x512的预测结果(可以调整更大的步长,或保留更大的中心区域,提高效率)。

3.2 测试增强
测试时,通过对图像水平翻转,垂直翻转,水平垂直翻转等多次预测,再对预测结果取平均可以提高精度,但相对的,推理时间也会大幅度升高。
with torch.no_grad():
for (image,pos_list) in tqdm(dataloader):
# forward --> predict
image = image.cuda(device) # 复制image到model所在device上
predict_1 = model(image)
# 水平翻转
predict_2 = model(torch.flip(image,[-1]))
predict_2 = torch.flip(predict_2,[-1])
# 垂直翻转
predict_3 = model(torch.flip(image,[-2]))
predict_3 = torch.flip(predict_3,[-2])
# 水平垂直翻转
predict_4 = model(torch.flip(image,[-1,-2]))
predict_4 = torch.flip(predict_4,[-1,-2])
predict_list = predict_1 + predict_2 + predict_3 + predict_4
predict_list = torch.argmax(predict_list.cpu(),1).byte().numpy() # n x h x w
3.3 snapshot ensemble
snapshot ensemble 是一个简单通用的提分trick,通过余弦周期退火的学习率调整策略,保存多个收敛到局部最小值的模型,通过模型自融合提升模型效果。详细的实验和实现可以看黄高老师ICLR 2017的这篇论文。

snapshot ensemble 另一个作用是作新方案的验证。深度学习训练的结果具有一定的随机性,但比赛中提交次数有限,无法通过多次提交来验证实验结果。在做新方案改进验证时,有时难以确定线上分数的小幅度提升是来自于随机性,还是改进方案really work。在比赛提交次数有限的情况下,snapshot ensemble不失为一个更加稳定新方案验证的方法
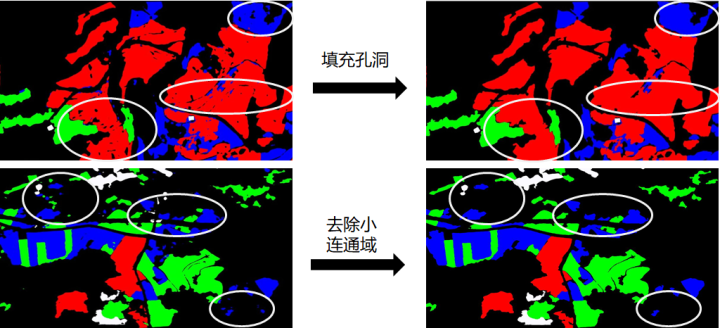
3.4 后处理
本次赛题数据场景为大面积农田,通过简单的填充孔洞和去除小连通域,去除一些不合理的预测结果。
3.5 边缘平滑
边缘平滑想法受Hinton大神关于的知识蒸馏和When does label smoothing help?的工作启发,从实验看标签平滑训练的模型更加稳定和泛化能力更强。
在知识蒸馏中,用teacher模型输出的soft target训练的student模型,比直接用硬标签(onehot)训练的模型具有更强的泛化能力。我对这部分提升理解是:软标签更加合理反映样本的真实分布情况,硬标签只有全概率和0概率,太过绝对。知识蒸馏时teacher模型实现了easy sample 和 hard sample 的“分拣”(soft-target),对hard sample输出较低的置信度,对easy sample 输出较高的置信度,使得student模型学到了更加丰富的信息。
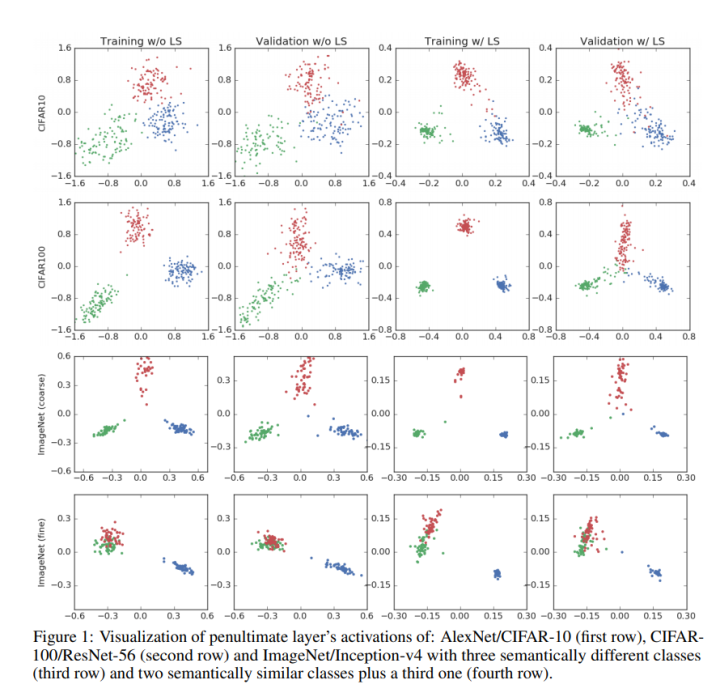
图3-5截取自When does label smoothing help?,第一行至第四行分别为CIFAR10、CIFAR100、ImageNet(Course)、ImageNet(fine) 的数据集上训练的网络倒数第二层输出可视化,其中第一列为硬标签训练的训练集可视化,第二列为硬标签训练的测试集可视化,第三列为软标签训练的训练集可视化,第四列为软标签训练的测试集可视化,可以看出软标签训练的模型类内更加凝聚,更加可分。
我们重新思考3.1中方格效应,在图像分割任务中,每个像素的分类结果很大程度依赖于周围像素,图像中不同像素预测的难易程度是不同的。分割区别于分类,即使不通过teacher模型,我们也可以发掘部分样本中的hard sample。本次比赛中我们主要考虑了以下两类数据:
图像边缘: 卷积时零填充太多,信息缺少,难以正确分类(参考3.1的方格效应) 不同类间交界处: 标注错误,类间交界难以界定,训练时可能梯度不稳定 类间交界的点,往往只相差几个像素偏移,对网络来说输入信息高度相似,但训练时label 却不同,也是训练过程的不稳定因素。
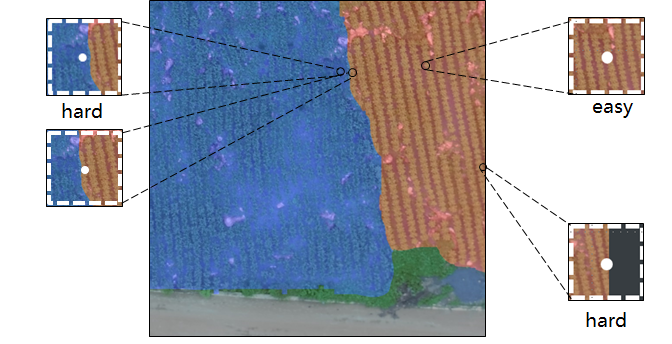
为验证这一想法,我们分别对模型预测结果及置信度进行可视化。图3-7中,从上到下分别为测试集原图、模型预测结果可视化、模型预测置信度可视化(为更好可视化边类间缘置信度低,这里用了膨胀预测,将置信度p<0.8可视化为黑色,p>=0.8可视化为白色)。可以明显看出,对于图像边缘数据,信息缺失网络难以作出正确分类。对于不同类别交界,由于训练过程梯度不稳定,网络对这部分数据的分类置信度较低。
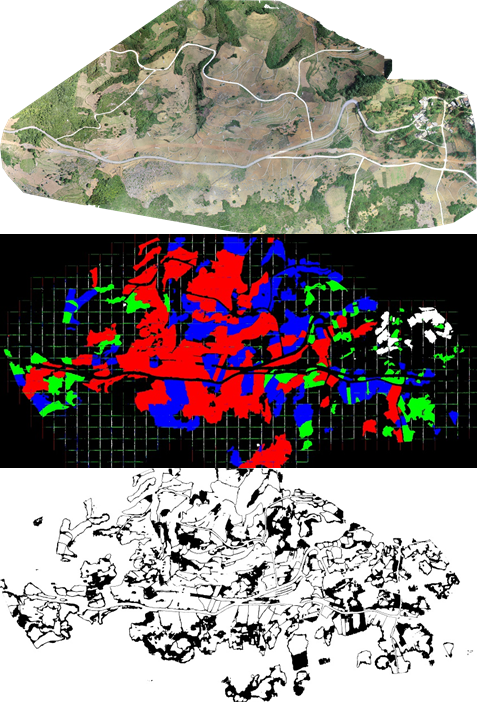
我们采取的方式是在图像边缘和类间交界设置过渡带,过渡带内的像素视为 hard sample作标签平滑处理,平滑的程度取决于训练时每个batch中 hard sample (下图黑色过渡带区域)像素占总输入像素的比例。而过渡带w的大小为一个超参数,在本次比赛中我们取w=11。

3.6 伪标签
地形泛化问题也是本次赛题数据一个难点,训练集中数据大多为平原,对测试集数据中山地、碎石带、森林等泛化效果较差。我们采用半监督的方式提高模型对新地形泛化能力。

在模型分数已经较高的情况下可以尝试伪标签进行半监督训练,我们在A榜mIoU-79.4时开始制作伪标签,具体实施是:
利用在测试集表现最好的融合模型结果作伪标签,用多组不同置信度阈值过滤数据,结合训练集训练模型; 选取多个snapshot的方法对模型进行自融合提高模型的泛化能力; 集成2中的预测结果,更新伪标签,重复步骤1~3。
伪标签方法提分显著,但对A榜数据过拟合的风险极大。即使不用伪标签,我们的方案在A榜也和第二名拉开了较大差距。在更换B榜前,我们同时准备了用伪标签和不用伪标签的两套模型。
4 总结
膨胀预测消除边缘预测不准问题; 使用测试增强、消除空洞和小连通域等后处理提高精度; 使用snapshot模型自融合、标签平滑、伪标签等方法提高模型稳定性和对新地形泛化能力;
比赛成绩:


颁奖仪式
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。