
噪声样本优秀论文综述(2017-2020)

极市导读
本文总结了噪声样本相关的20篇论文,并按照理论篇和方法篇进行了分类,帮助对噪声样本感兴趣的同学进行学习。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
最近 Noisy Label 的工作快要告一段落,发一下其中一些论文的总结吧...感兴趣的同学欢迎交流
更多论文
可以参考以下两个 repo
gorkemalgan/deep_learning_with_noisy_labels_literature
https://github.com/gorkemalgan/deep_learning_with_noisy_labels_literature
subeeshvasu/Awesome-Learning-with-Label-Noise
https://github.com/subeeshvasu/Awesome-Learning-with-Label-Noise
知乎相关问题
神经网络对噪声样本过拟合的现象是什么?
https://www.zhihu.com/question/388977428
Survey 篇
两篇,没有太细读
Image Classification with Deep Learning in the Presence of Noisy Labels: A Survey
https://arxiv.org/abs/1912.05170
Learning from Noisy Labels with Deep Neural Networks: A Survey
https://arxiv.org/abs/2007.08199
提供了一个方法分类树,值得一看
理论篇
Understanding deep learning requires rethinking generalization
https://arxiv.org/abs/1611.03530
笔记:JackonYang:[Paper Reading]Learning with Noisy Label-深度学习廉价落地
https://zhuanlan.zhihu.com/p/110959020
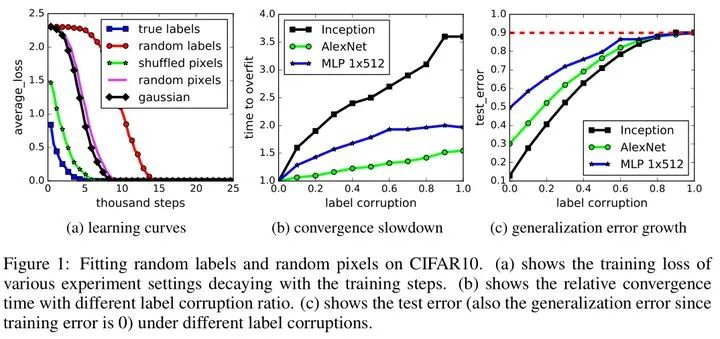
提出的观点并用实验证明:Deep neural networks easily fit random labels.
这个观点几乎是 2017 年之后 noisy label 相关文章必引观点。这篇文章之前,introduction 都在介绍众包 & 错误不可避免,SOTA 模型表现差。这篇文章之后,理论焦点突出为解决 noisy label 导致的 overfitting。
论文中用实验验证了,模型可以很容易的拟合噪音,无论是真实样本+噪音标签,还是完全噪音的图片。
Understanding Black-box Predictions via Influence Functions
https://arxiv.org/abs/1703.04730
演讲:https://www.youtube.com/watch?v=0w9fLX_T6tY
笔记:
1. NoahSYZhang:ICML 2017 Best Paper Award论文解读(1)(https://zhuanlan.zhihu.com/p/28470292)
2. 论文笔记understanding black-box predictions via influence functions(https://blog.csdn.net/panglinzhuo/article/details/77992306)
3. (2017ICML Bestpaper)Understanding Black-box Predictions via Influence Functions 笔记(https://blog.csdn.net/alva_bobo/article/details/78552657)
4. 论文笔记:Understanding Black-box Predictions via Influence Functions(https://www.jianshu.com/p/64d3e57c991c)
数学推导很多,数学苦手很南...就结论而言,本文提出了一个影响函数,用来评估一个样本对模型最终结果的影响。消耗算力最大的方法是训练两次数据集,其中一次不包含该样本,而本文通过一步步的推导得到了这种评估影响的近似方法。
A Closer Look at Memorization in Deep Networks
https://arxiv.org/abs/1706.05394
本文是一篇实验经验文,分享大量实验结果及其总结。
论文首先深入了“模型首先学习样本的 pattern”这一结论,由实验中发现的“干净样本在初始时准确率提升速度低于噪音样本”这一现象来说明真实样本中样本的差异性大于噪音样本,这使得真实样本中学到的 pattern 一开始对一些“困难样本”不友好,而噪音样本则因为没有差异性从而可以被模型分别学习与记忆。(这里的差异性可能指的是同类简单样本和复杂样本之间的 pattern 不一样)。
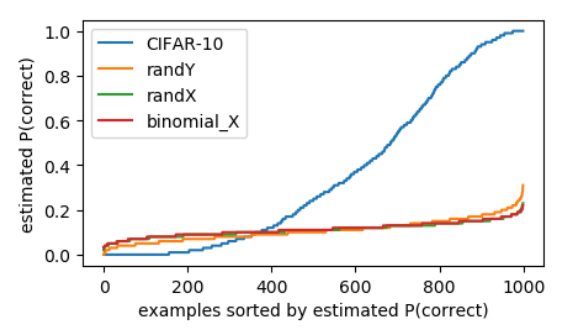
第二,作者通过欧氏距离定义了临界样本这一概念(即不属于同类但又相隔很近的样本),并发现噪音样本在训练过程中具有比干净样本更高的临界样本率,两类样本在训练过程中的临界样本率都会逐步提升,这从侧面证明了模型在拟合的过程中会逐步学习到更复杂的决策边界(more complex hypothese)。
第三,验证了一些正则化方法(尤其是 dropout )能够控制神经网络的记忆速度(regularizers (especially dropout) do control the speed at which DNNs memorize),而在这之前,dropout 通常用于防止灾难性遗忘(catastrophic forgetting),也因此用于帮助 DNN 捕捉模式(retain patterns)。
第四,作者还通过计算训练过程样本梯度相关的数据验证了干净样本比噪音样本包含了更多的类间模式(cross-category patterns)。
第五,模型越大,最终的准确率就越接近干净数据的准确率。
方法篇
大部分噪音标签方法的核心思想就是,既然噪音标签和真实标签在一开始的表现不同,那这种不同表现就可以看做是样本的一种特征,用来帮助我们区分某一样本是干净还是噪音。此外,还有一些方法选择对噪音进行建模,将噪音看成某种分布,构建转移矩阵等。在深度学习下,前一种方法较为主流。
SELF: Learning to Filter Noisy Labels with Self-Ensembling
https://arxiv.org/abs/1910.01842
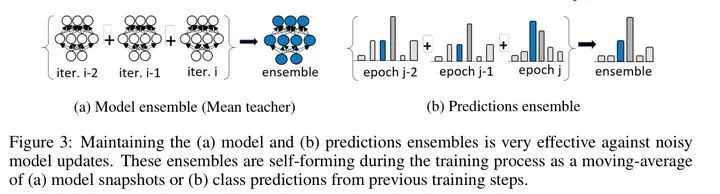
本文算法的关键在于将噪音标签从数据集中去除。去除的方法是用伪标签和噪音标签比较,不相等则去除。
其中,用于预测伪标签的模型和最终用于比较的伪标签,均通过moving average 方法进行平滑。也即所谓的 Self-Ensembling
如下图:
Confident Learning: Estimating Uncertainty in Dataset Labels
http://www.eng.biu.ac.il/goldbej/files/2012/05/ICLR2017.pdf
这篇对数学的要求也蛮大。。。
本文的主要贡献有:
1. 提出了一个置信度学习(CL,confident learning)用于找到并学习噪音标签
2. 证明了一致性联合评估(consistent joint estimation)的平凡条件。
3. 在 cifar 和 ImageNet 上验证了 CL 的有效性
4. 发布了 cleanLab 这一个 Python 库
该方法的输入需要原噪音标签和样本的预测值,因此和样本本身无关。
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
https://arxiv.org/abs/1712.05055
Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels
https://arxiv.org/abs/1911.09781
这两篇是一个作者,来自Google Research,两篇是连续的工作
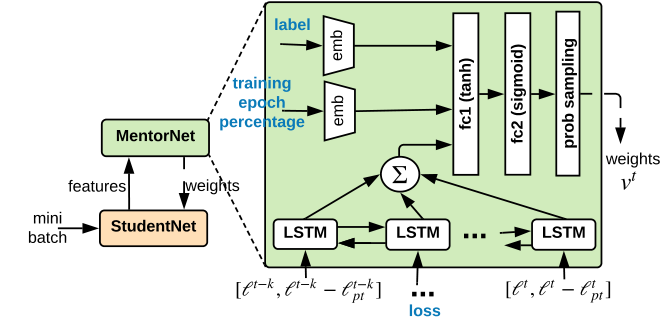
MentorNet 虽然里面有很多课程学习(Curriculum Learning)的内容,但其核心思想是对计算得到的交叉熵损失加权,使噪音标签得到低权重,而干净标签得到高权重,而权重的生成则来自于文中定义的 MentorNet,其可以看做是一个函数,输入是当前 batch 样本所产生的 loss 的历史信息,输出是根据这些 loss 信息计算得到的权重。这是一个非常抽象的形式,实际上概括了所有“生成权重型方法”的表示形式。
而文中提到过两种形式,一种是最简单的,要求样本 loss 小于某一阈值(阈值随训练时间变化),如果满足则将其作为干净样本,否则认作噪音;另一种(也是最终采用的)是一个和 LSTM 结合的网络,结构如下
MentorMix 沿用了MentorNet 的想法,核心仍然是生成权重,但引入了半监督学习的一些想法,加入了伪标签和 mixup,想法类似于 MixMatch。
虽说方法简单,但谷歌出品,质量还是很不错的,里面包含了一些数学上的形式化证明和很多对实验的具体分析,因此很有细读的必要(我就还没细读)。
Learning to Reweight Examples for Robust Deep Learning
https://arxiv.org/abs/1803.09050
Distilling Effective Supervision from Severe Label Noise(IEG)
https://arxiv.org/abs/1910.00701
代码:google-research/google-research
https://github.com/google-research/google-research/tree/master/ieg
Review : IEG: Robust neural net training with severe label noises
这两篇论文虽然不是一个作者,但也可以放在一起讲,第一篇 L2R 是一种通过元学习为样本生成权重的方法,这一方法可以用于类别不平衡,或者是噪音标签,我复现过,在MNIST上类别不平衡的效果非常不错,但是噪音标签上(尤其是高噪音率下)似乎就有些力有未逮。
而在之后是 IEG,很遗憾的是它也是Google Research出品。它采用了 L2R 的元学习方法生成样本权重,并和半监督学习中的 MixMatch 方法融合,最终获得了一个很好的效果。感兴趣可以看看 Review,有人怼这篇论文就是各种方法的融合体,而缺少创意,最终该作者从 ICLR2020 撤稿,然后中了 CVPR2020... (此处不留人,自有留人处啊)
Generalized cross entropy loss for training deep neural networks with noisy labels
https://arxiv.org/abs/1805.07836
Symmetric Cross Entropy for Robust Learning with Noisy Labels
https://arxiv.org/abs/1908.06112
这两篇是比较少的从构建新的损失函数的角度出发的解决噪音标签问题的论文(从我查到的情况下)。
第一篇的论点是,平均绝对误差(mean absolute error, MAE)以均等分配的方式处理各个sample,而CE(cross entropy)会向识别困难的sample倾斜,因此针对noisy label,MAE比CE更加鲁棒,但是CE的准确度更高,拟合也更快。于是这篇文章提出GCE loss,结合MAE与CE二者的优势。
第二篇的角度可能比较新奇,其首先对模型在干净和高噪音率下对不同类别的预测表现进行了分析,然后指出来传统的交叉熵损失(CE)是存在问题的,会导致预测分布出现问题,简单的类会更容易被学习(以及在高噪音下被过拟合)。从而提出了一个新的对称交叉熵损失,实际上就是标签和预测值互换的交叉熵损失和原交叉熵损失的加权和。似乎对对称噪音(Asymmetric Noisy)很有效。具体可以看一下论文里的实验结果。
Decoupling "when to update" from "how to update"
https://arxiv.org/abs/1706.02613
Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
https://arxiv.org/abs/1804.06872
A Novel Self-Supervised Re-labeling Approach for Training with Noisy Labels
https://arxiv.org/abs/1910.05700
DivideMix: Learning with Noisy Labels as Semi-supervised Learning
https://arxiv.org/abs/2002.07394
Combating noisy labels by agreement: A joint training method with co-regularization
https://arxiv.org/pdf/2003.02752.pdf
这五篇论文是可以放在一起看的,因为其核心方法虽然各有差别,但都需要借助两个同时训练的网络来实现。
第一篇 Decoupling 是随机初始化两个网络,随后两个网络只有在两个网络有分歧(disagreement)的时候才进行bp的更新。也即 "when to update"
第二篇是非常典型的 co-training 系,在半监督里也有 co 系的身影,我一直觉得这在某种意义上算是集成学习。每一个模型在训练过程中,都会记录当前 epoch 下每个样本的交叉熵损失,最后进行一个排序,然后按照噪音率分成两部分样本,选取损失更小的那一部分样本作为这个模型选出的干净样本,然后互相喂给对方模型进行下一个epoch的训练。两个人挑一堆零食嚼吧嚼吧,把自己觉得好吃的挑出来喂给对方,大概是这种感觉吧...
第三篇就是 co-teaching 的翻版,基本上换汤不换药,但额外添加了一个自监督环节,以及在 co-teaching 环节结束后,再额外按照 co-teaching 找出的干净样本从头再训练一个模型(我没看错的话应该是这样)。
第四篇 DivideMix 是截止到 2020年11月 的 SOTA 结果,仍然是 co-teaching 的思路,但是在挑出干净样本和噪音样本后,把噪音样本当做无标签样本,通过 MixMatch 的方法进行训练。到这里大家也发现了,噪音样本如果能完美的区分出来,按现在最大噪音率 80% 来算,用半监督方法去解决其实是小 case 的,目前半监督图像分类的 SOTA 应该还是 FixMatch,其在 90% 的无标签样本下都能取得接近有监督的结果...所以现在取得高准确率的思路基本都是朝着半监督和如何完整区分出噪音这个大方向走的...
第五篇被命名为 JoCoR,co-teaching 的翻版,就是两个模型下的交叉熵加一个两个模型之间的对比损失(用 JS 散度构造)。
Joint Optimization Framework for Learning with Noisy Labels
https://arxiv.org/abs/1803.11364
Probabilistic End-to-end Noise Correction for Learning with Noisy Labels(PENCIL)
https://arxiv.org/abs/1903.07788
Joint 这篇提出了一个叫做轮换策略(alternating strategy)的学习框架,大意就是先梯度下降更新一波模型参数,然后用模型参数做一波噪音标签的校正,具体的校正方法自然是通过伪标签进行一个对比...这个方法其实比较普通,有些价值的地方在于本文观察到 DNN 在高学习率下不会记住噪音标签,而是能以很好的性能学习到干净的数据。
Pencil 这篇思路也蛮新奇的,是通过梯度下降更新噪音标签,使噪音标签向干净标签的方向跑,在这之前用大学习率直接训练一段时间做初始化。但我做了下实验发现似乎有问题...还没深入研究,感兴趣的同学欢迎再跟我交流一下。。。
这两篇不太相关,放在一起是因为PENCIL 这篇引了第一篇,因为它用大学习率学习就是因为 Joint 这篇的结论。
推荐阅读
2021-02-23

2021-02-23

2021-02-22

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
