本文从小样本目标检测任务和问题、学习策略、检测方法、数据集与实验等角度出发,对当前小样本目标检测的研究成果加以梳理和总结。
今天给大家带来一篇关于小样本目标检测的研究综述。希望这篇文章能对你有所帮助,让你在学习和应用AI技术的道路上更进一步!
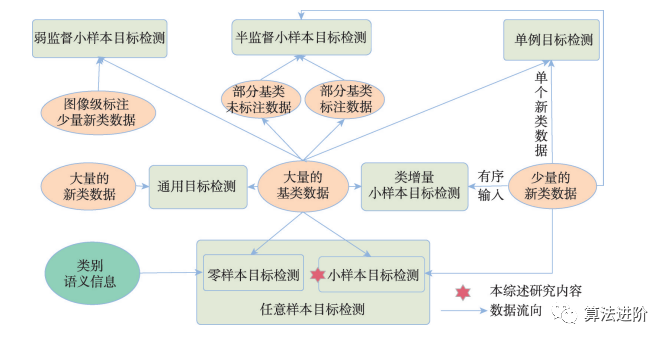
小样本目标检测(Few-shot Object Detection, FSOD)旨在通过少量标注样本实现对图像中目标的分类和定位。从概念上来讲,小样本目标检测是指在带有大量注释信息的基类数据集上训练得到基类检测模型,仅利用极少标注的新类数据集和基类模型提供的先验知识实现对新类的检测,如图 1 所示
图 2 从数据流向的角度展示了小样本目标检测及其相似任务之间的区别与联系
小样本目标检测中的三个核心问题:过拟合、域偏移和数据及分布偏差。
过拟合。小样本目标检测的核心问题之一是过拟合。当新类数据与基类数据属于同域,且新类别仅有少量的训练样本可用,同时还需考虑目标的分类和定位任务时,在训练深度检测模型时极易造成模型过拟合,使训练良好的检测模型在新类数据集上性能较差,从而导致模型的泛化能力不足和鲁棒性差等问题。换言之,小样本数据集与模型复杂度间的高度不匹配导致了模型训练问题,因此,如何在小样本条件下进行模型训练,降低模型的学习难度,进一步增强模型的泛化性能成为当前小样本检测技术发展的难点之一。
域偏移。目前,小样本目标检测方法通常是借助大规模基类数据集来学习通用知识,同时将这些知识迁移至新任务的学习中。然而,当源域和目标域数据具有不同的数据分布时,可能出现域偏移问题。域偏移是指源域训练的模型在应用于具有不同统计量的目标域时表现不佳,属于异构迁移学习的范畴。具体而言,当源域的基类与目标域的新类数据间存在较大的域差异,且二者共享的知识较少时,将基类训练的模型作为知识迁移至新类时很可能出现负迁移,从而导致模型对新任务的检测性能不佳,这就是通常所说的域偏移问题。因此,如何利用先验知识弥补样本数据量不足问题,是当前研究面临的巨大挑战之一。与此同时,构建小样本下的检测模型,需综合考虑合适的先验知识和迁移策略,因此,如何有效地将源域知识迁移并泛化至目标域有待进步探索。
数据及分布偏差。数据集本质上是从数据分布中观察到的样本集合。然而,当训练样本数量不充足时,数据的多样性降低,导致数据偏差及分布偏差等问题。与大规模的数据集相比,有限的训练数据会放大数据集中的噪声,造成数据偏差,比如对于相同类别的图像存在较大的类内变化,不同类别的图像间的距离较小等等。而且,因目标域样本极其有限,无法准确地表征目标域的真实数据分布,导致目标域类别间及类别与背景间相互混淆,从而影响模型的检测精度。因此,如何提升训练数据的多样性,降低分类混淆,进而保证小样本检测模型的稳定性具有很大的研究空间。
针对小样本下的模型训练问题,当前的小样本目标检测方法通常基于任务的episode训练策略和基于数据驱动的训练策略这两种学习策略。
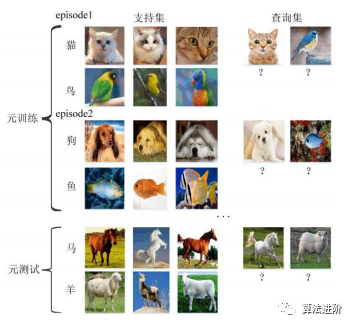
基于任务的 episode 训练策略。基于任务的 episode 训练策略以任务为基本单元,每个任务的数据集分为支持集和查询集,其目标是从大量训练任务中获取先验知识,从而能够通过少量数据在新任务中更快地学习。整个训练过程可分为元训练和元测试两个阶段,在元训练阶段,通过组合不同的训练集构建不同的元任务,使得模型学习独立于任务的泛化能力;在元测试阶段,模型不需要重新训练或仅需少量迭代次数即可学习新任务,最终实现“学会学习”。在训练过程中,模型通过支持集中的样本进行学习,然后在查询集中进行测试和评估。图3展示了 2-way 3-shot 任务的训练范式。
该策略的优点在于能够快速获取先验知识,从而在新任务中更快地学习,但其要求所有任务满足同分布,其任务的设计可能限制了模型的学习能力。
基于数据驱动的训练策略。基于数据驱动的训练策略任务,采用“预训练微调”的训练范式,直接针对数据集进行训练,在具有大量注释的基类数据集上进行预训练获得基类检测模型,在小样本数据集上进行微调泛化至新类。在训练过程中,模型通过批量数据进行学习,然后在小的数据集上通过微调实现模型的可迁移性,使其泛化至新任务。图4展示了基于数据驱动的训练策略。
该策略的优点在于能够通过数据增强等方式增加数据的多样性,提高模型的泛化能力,但其需要大量的标注数据进行训练,且可能存在过拟合的问题。
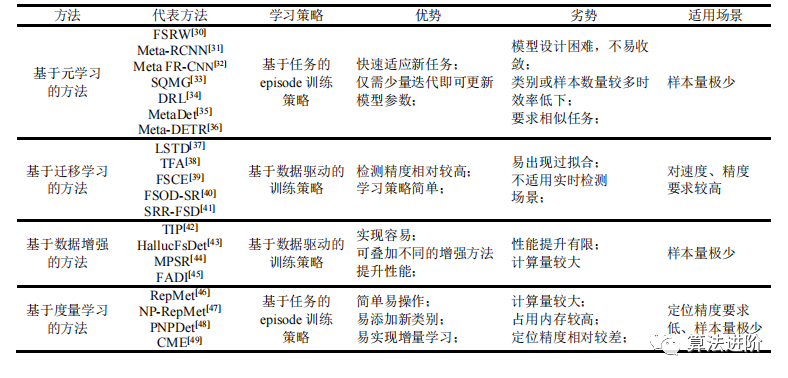
从工作原理的角度出发,我们将小样本目标检测方法分为基于元学习的方法、基于迁移学习的方法、基于数据增强的方法以及基于度量学习的方法四类。表 1 对这四类方法进行了简要地概括和对比。
基于元学习的方法核心思想是通过模拟一系列相似的小样本任务,将先验知识从注释丰富的基类迁移至数据匮乏的新类之上,以应对样本数量不足的问题。元学习方法以任务为单元进行训练,通过任务和数据的双重采样来设计不同的小样本任务,使其能够利用少量的支持集样本快速更新模型参数,最终在特定任务下仅需少量迭代即可快速泛化至新任务,不需要进一步微调。基于元学习的方法在小样本目标检测中取得了一定的成果,但是其设计较为困难,且在学习迭代过程中易出现不收敛问题。
图5将Faster RCNN作为基础检测模型,构建了基于元学习的小样本目标检测框架。该框架通常采用并行结构,整个流程包括元训练和元测试两个阶段。
基于迁移学习的方法与基于元学习的方法不同,基于迁移学习的方法不需要设计训练任务,而是通过微调的方式将基类训练的检测模型迁移至新类。该方法不需要任务间存在很强的关联性,且更强调在迁移的新任务上的性能,但依然存在诸多挑战与难点。基于迁移学习的方法在小样本目标检测中也取得了一定的成果,但是需要解决的问题包括如何减少目标混淆、增强新类特征表示、保持基类的性能等。
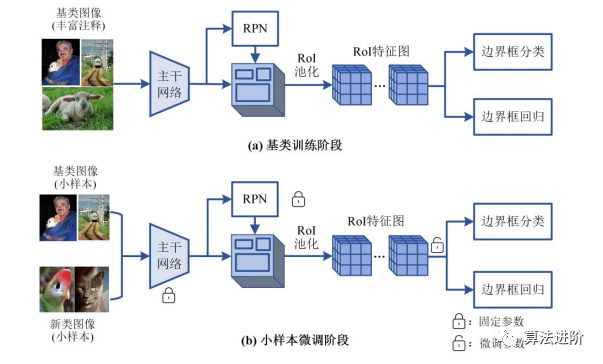
图6以两阶段检测模型为基础,构建了基于迁移学习的小样本目标检测框架该框架分为基类训练和小样本微调两个阶段。
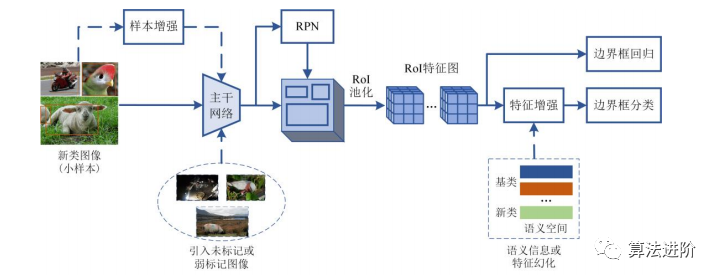
基于数据增强的方法旨在通过生成更多新类样本、增强新类特征表示或为模型提供其他信息等方式,克服训练样本短缺的局限性。对于目标检测任务而言,可以采用两种数据增强方式:一是不改变标注框的增强方式,如色彩变换、高斯噪声以及弹性变换等等;二是改变标注框的增强方式,如裁剪变换、旋转变换以及镜像变换等。在小样本目标检测中,数据增强方法可以提升数据及分布的多样性,从而提高模型的泛化能力。目前,一些工作从如何生成更多示例的角度展开研究,而另一些工作则从未标记/弱标记的图像或语义信息中,如何为模型提供额外的先验知识的角度出发展开研究,提出了一系列创新性方法,并取得了令人可喜的研究成果。
图 7展示了基于Faster RCNN模型的基于数据增强的小样本目标检测方法。当前方法分为三类:样本与特征空间增强、引入未标记或弱标记数据及引入额外的语义信息。
基于度量学习的方法核心思想是将小样本目标检测视为小样本分类问题,通过学习比较的思想,在小样本图像分类任务下取得了良好的性能。该类方法主要从支持集图像的类原型表示、度量机制的实现以及损失函数设计等三个角度分别进行改进。然而,不能简单地将小样本分类中的度量方法直接应用于小样本目标检测中,其原因在于检测模型需要知道潜在目标区域才能进行比较。因此,基于度量学习的小样本目标检测方法需要在度量学习的基础上,进一步考虑如何捕捉目标区域的信息,以提高检测性能。
图 8 给出了基于度量学习的小样本目标检测框架。度量模块的结构如图 9所示。
当前小样本目标检测的数据集主要包括PASCAL VOC、MSCOCO、LVIS和FSOD等四个数据集。数据集的概况如表 2 所示。
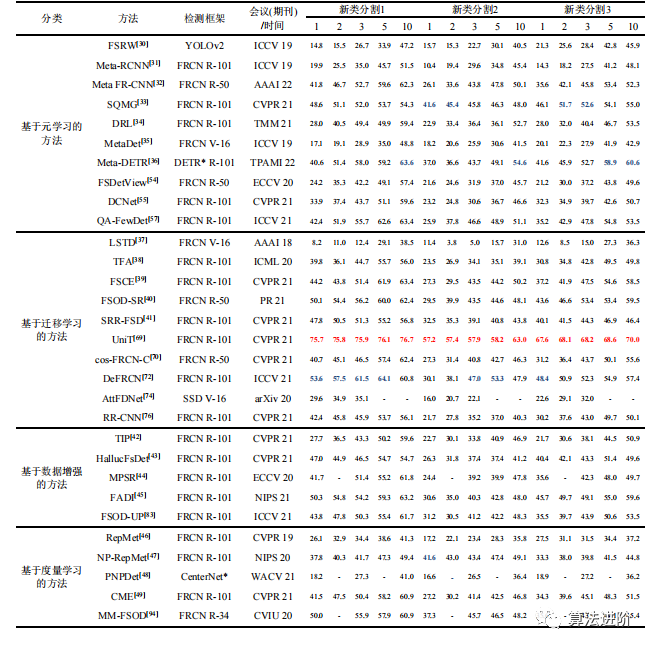
表3列出了在三种不同的基类/新类类别分割设定下,小样本目标检测典型方法在PASCALVOC数据集下的新类检测性能。表中红色加粗/蓝色加粗分别表示性能最优/次优结果,下表同。
表 3 PASCAL VOC 数据集中对新类的小样本检测性能
由表3可知,大多数方法采用Faster RCNN作为基础检测模型,目前性能最好的方法是UniT。此外,基于迁移学习方法的性能在大多数任务下达到 SOTA,基于元学习方法的性能仅次于基于迁移学习方法,基于数据增强和度量学习方法的性能较差,表明在 PASCAL VOC 数据集上还有较大的提升空间。
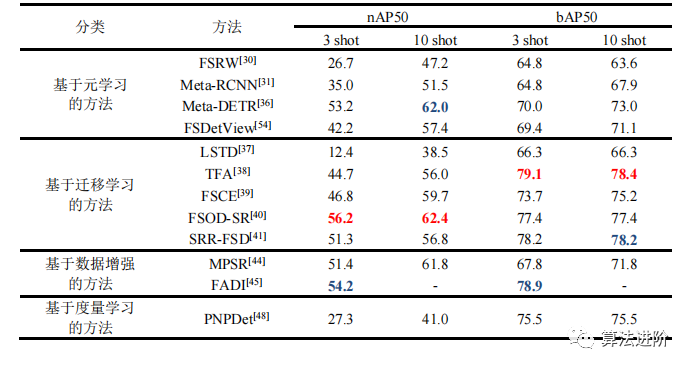
表4给出了第一次分割下,四类经典方法对基类遗忘性能的比较。其中,nAP50表示IoU阈值等于0.5时的新类检测性能,bAP50表示IoU阈值等于0.5时的基类检测性能。从实验结果中可看出,基于迁移学习的两种方法TFA和SRR-FSD分别在基类和新类的检测精度指标上达到了最新水平。
表 4 PASCAL VOC数据集下基类和新类的小样本检测性能
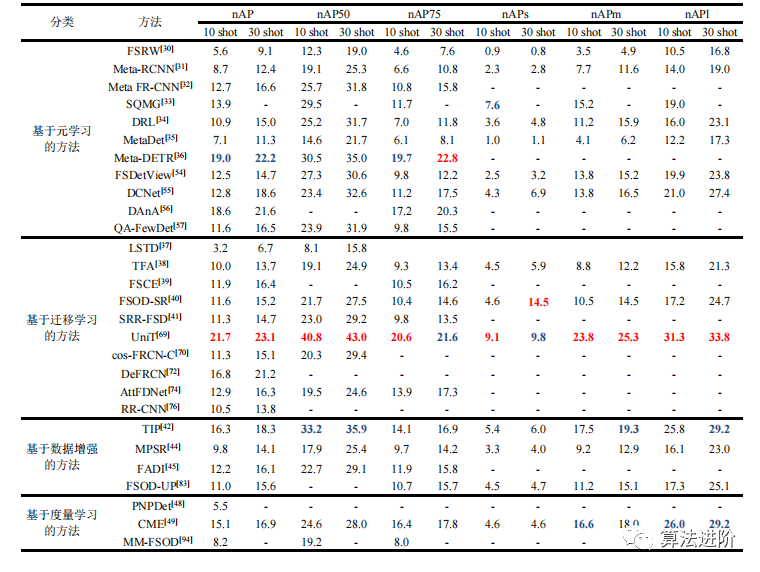
表5列举了四类经典的小样本目标检测方法在COCO数据集上的新类检测性能对比。其中,每类采用10个样本和30个样本,nAP表示新类别的平均检测性能,nAP50表示IoU阈值等于0.5时的新类别检测性能。从实验结果中可以看出,对于检测难度较大的COCO数据集而言,基于小样本的检测性能还有较大的提升空间。
表 5 四类经典方法在COCO数据集10/30个样本下的新类检测性能
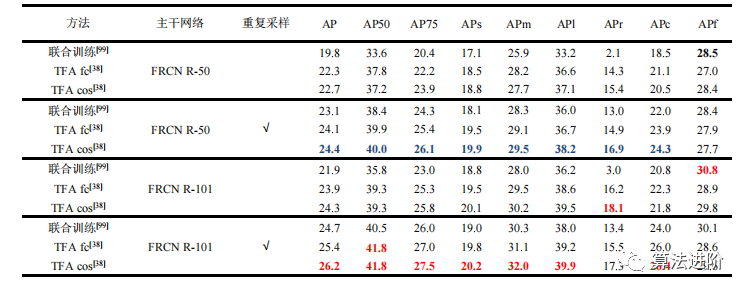
表6列举了TFA方法与联合训练方法在LVIS数据集10-shot下的新类检测性能。
表 6 两种方法在LVIS数据集10个样本下的新类检测性能
表7列举了四种小样本目标检测方法在FSOD数据集上的新类别检测性能对比。从实验结果中可以看出,基于元学习的方法FSOD和MM-FSOD不需要后续的微调步骤就能检测新类别,且MM-FSOD方法的性能与FSOD方法相比平均高出17.95%,而基于迁移学习的LSTD方法则需要进一步的微调。
表 7 四种方法在FSOD数据集5个样本下的新类检测性能
尽管小样本目标检测取得了显著进步,但各类方法仍受限于特定应用场景和局限。目前的算法在有限监督下的小样本场景表现良好,然而在复杂场景,如持续增量学习、弱监督或域适应等方面的小样本目标检测仍面临挑战。特别是,针对无人机和机器人领域的持续增量小样本检测的研究相对匮乏,相关试验性验证也不充分。同时,弱监督或域适应小样本目标检测尚处于起步阶段,需根据特定领域知识和任务特性设计有针对性的小样本检测算法。此外,算法的实际应用也面临挑战,但在人工智能各个领域具有广泛的应用价值和研究意义。因此,在复杂场景下,研发有效的小样本目标检测方法及其应用仍是一个重要的研究方向。







 下载APP
下载APP