综述 | 小样本学习在深度学习中的作用
来源:知乎—沃丰科技
01

02
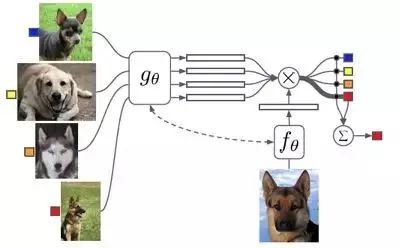
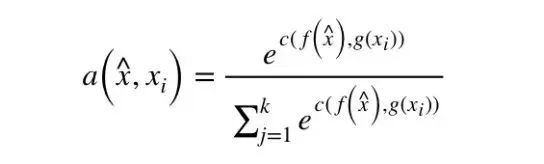
一个batch包括多个task; 一个task包括一个support set和一个test example; 一个support set包括多个sample(image & label); support set中有且只有一个样本与test example同类。
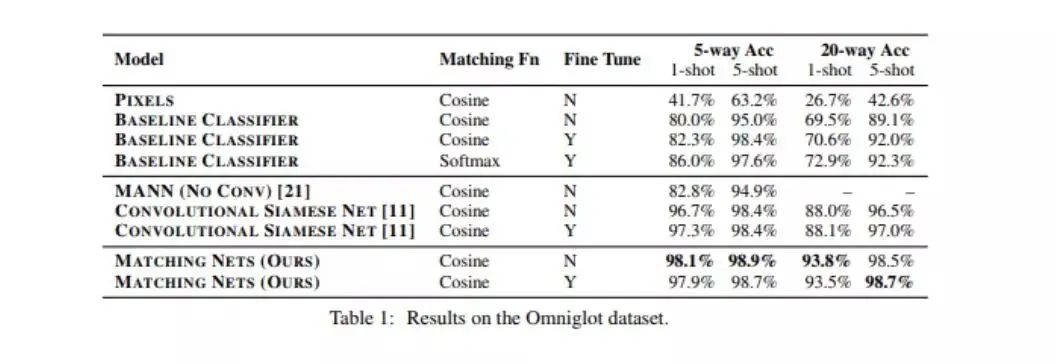
03

猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论
 下载APP
下载APP来源:知乎—沃丰科技
01
02
03
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》