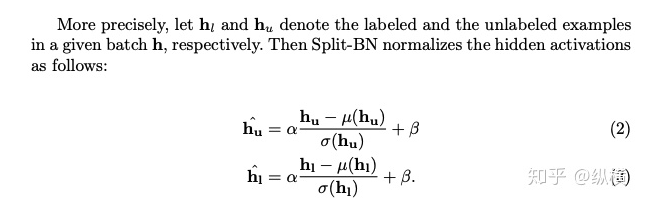加入极市专业CV交流群,与 1 0000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 , 回复 加群, 立刻申请入群~
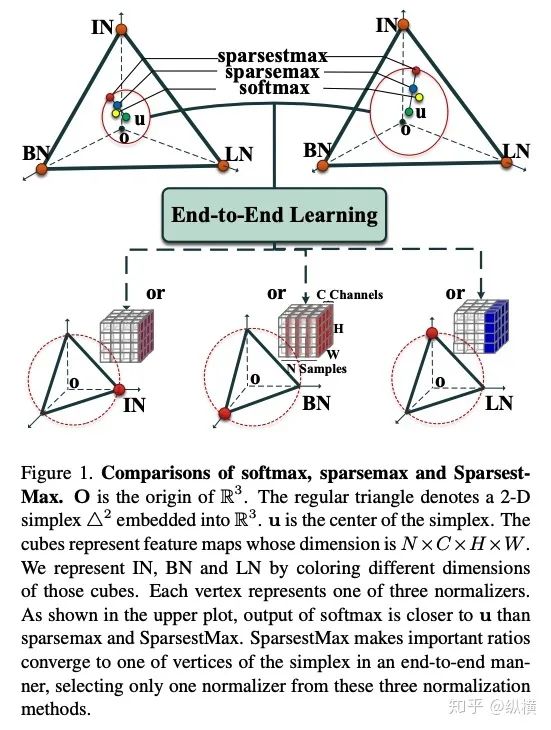
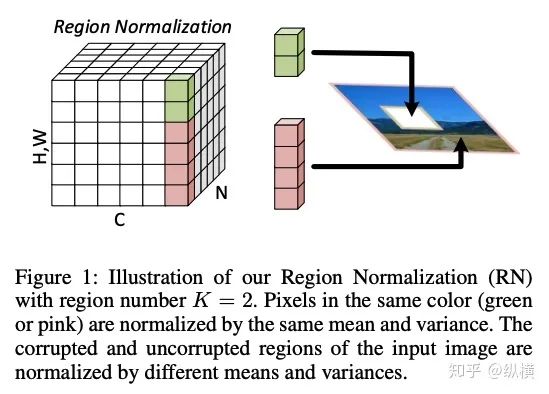
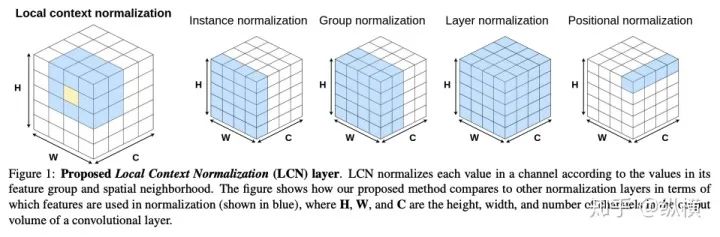
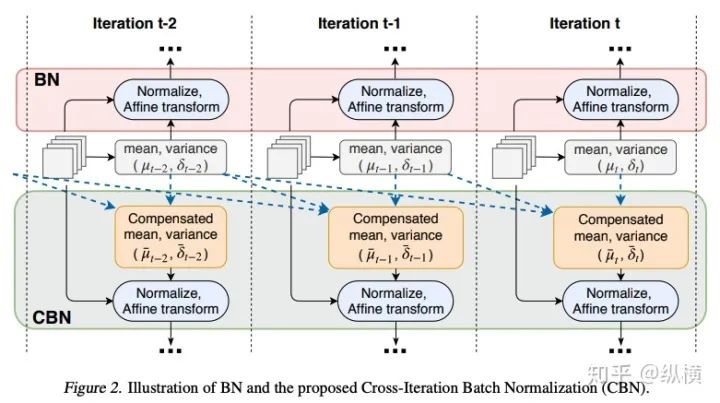
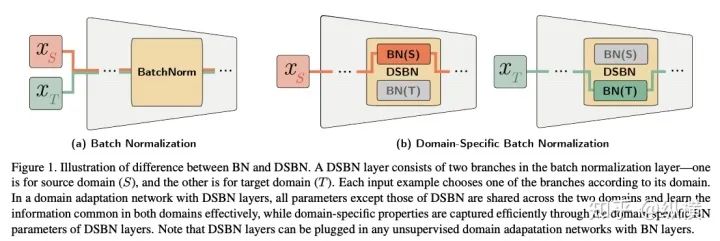
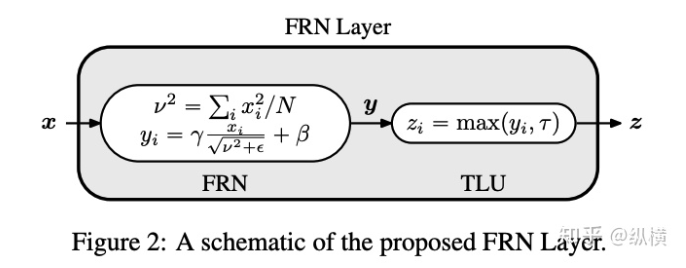
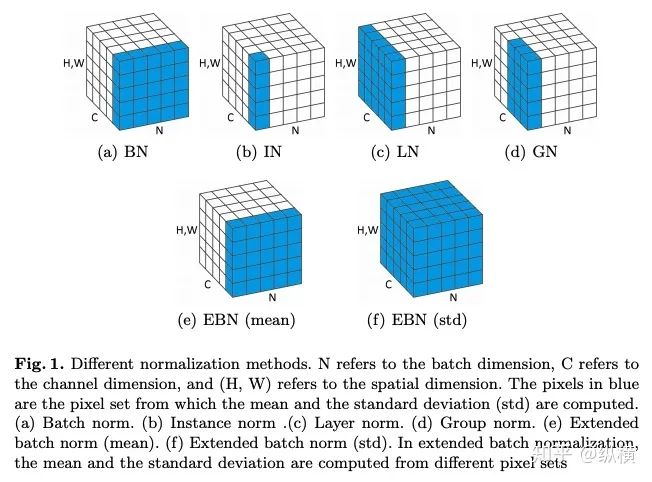
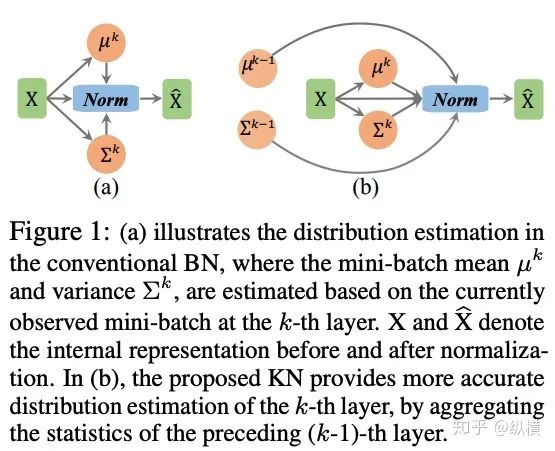
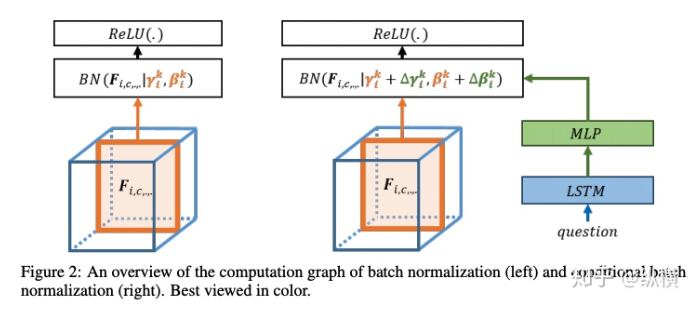
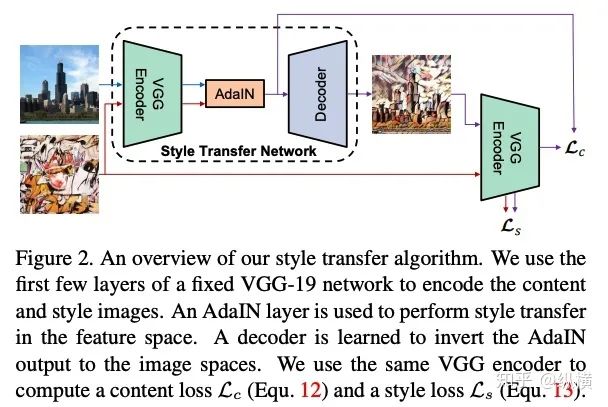
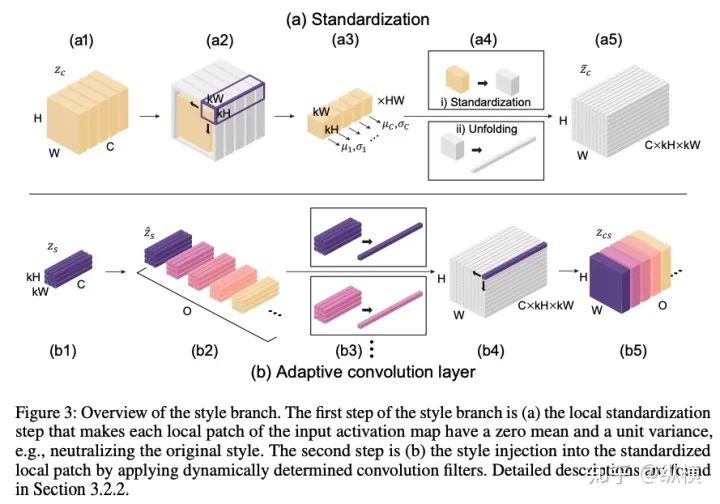
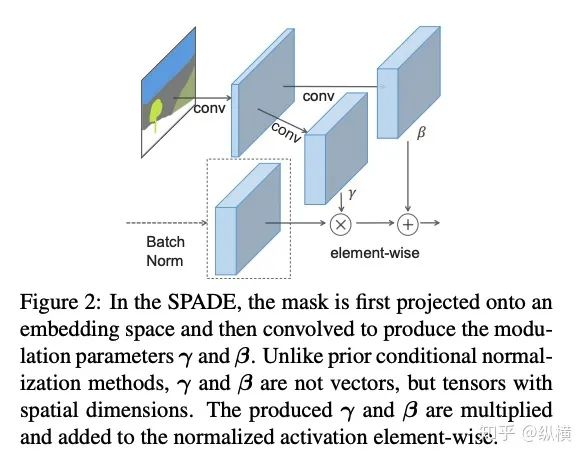
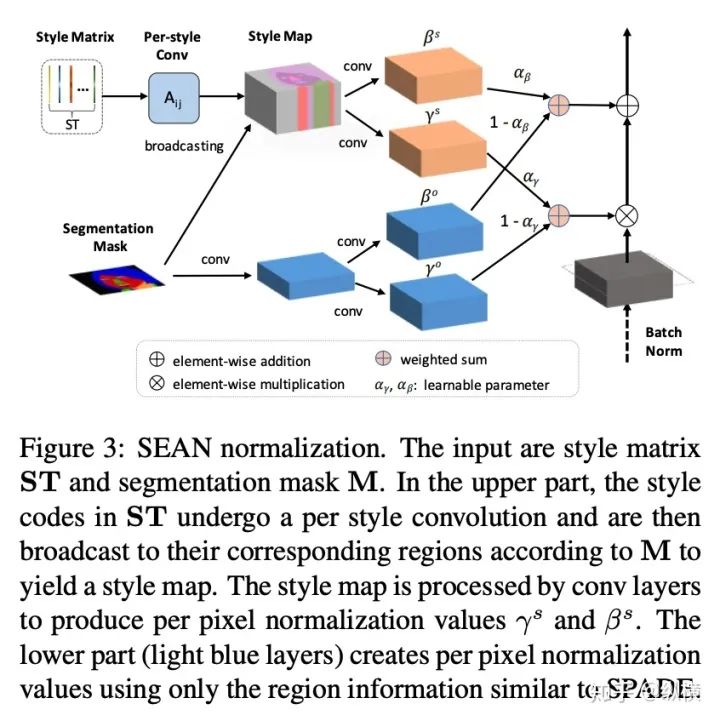
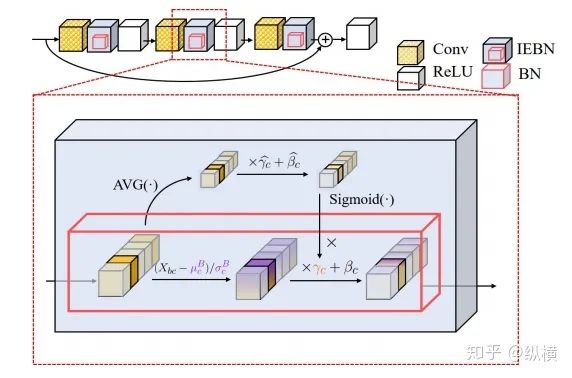
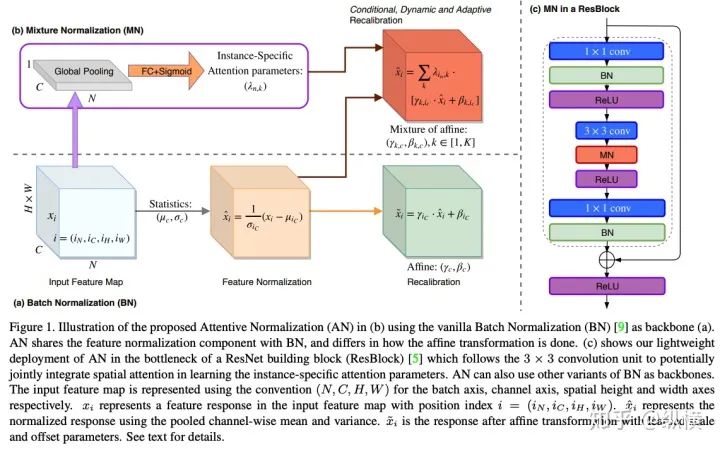
来源丨https://zhuanlan.zhihu.com/p/166101119 2020 年已经要迎来了第二学期,内卷、红海、赛马似乎仍是 CV 领域的主旋律。不考虑 ddl 的话,在这样的主旋律下做一个 C(ctrl c)V (ctrl v)研究生也乐得清闲自在。然而,就在本周的划水星期五,笔者发现 Normalization 领域(如果能叫领域的话)似乎还留有一片知识的荒原,阻碍了 ctrl c + ctrl v 的进程。 这里,没有 survey,没有 toolbox,甚至连 awesome list 都没有。因此,本着周五(划水)精神,笔者重新调研了一下 Normalization 的相关技术 首先,在笔者看来,“批量归一化”这个名称有些失败。归一化,意味着把 tensor 中的每个 element(或其 L1 范数)规范化到 [0, 1] 区间内(或者使其均值为 0 方差为 1) 。按照这种叫法,在形式自由主义者看来,Sigmoid 是归一化,Tanh 也是归一化。归一化反倒成了一种特殊的激活函数。 这显然不是我们想表达的。笔者认为,批量归一化的真正精妙之处在于,在归一化的过程中,BN 用一种极为节能的方式建模了整体与个体的相对关系 。而 Sigmoid、Tanh 等激活函数虽然借助于其非线性性将每个 element(个体)规范化了,但是 element-wise 的操作始终不 涉及到整体的统计特征 。 至于整体是什么的整体,这种相对关系带来了哪些好处,每个魔改的 BN 都给出了不同的回答。笔者相信未来也会有更多的答案。 从 Batch Normalization 看魔改方向 Batch Normalization 为了方便后续的魔改,笔者用 vanilla pytorch 实现了 BatchNorm2d。对于一个形状为 (N, C, H, W) 的 input(其中 N 为 batch size, C 为通道数,H 为高,W 为宽),Batch Normalization 的计算方法如下: ... if self.training: # 计算当前 batch 的均值 mean = input.mean([0, 2, 3]) # 计算当前 batch 的方差 var = input.var([0, 2, 3], unbiased=False) n = input.numel() / input.size(1) with torch.no_grad(): # 使用移动平均更新对数据集均值的估算 self.running_mean = exponential_average_factor * mean\ + (1 - exponential_average_factor) * self.running_mean # 使用移动平均更新对数据集方差的估算 self.running_var = exponential_average_factor * var * n / (n - 1)\ + (1 - exponential_average_factor) * self.running_var else: mean = self.running_mean var = self.running_var # 使用均值和方差将每个元素标准化 input = (input - mean[None, :, None, None]) / (torch.sqrt(var[None, :, None, None] + self.eps)) # 对标准化的结果进行缩放(可选) if self.affine: input = input * self.weight[None, :, None, None] + self.bias[None, :, None, None] ... 1、BN 时作用于 batch 中所有样本 feature map 的归一化方法,统计 (N, H, W) 的均值和方差;这里,统计的对象 可以魔改; 2、在规范化每个元素时,BN 使用了减均值除以方差的方法;这里,规范化的方式 可以魔改; 3、对标准化的结果进行缩放时,BN 使用了一个简单的仿射变换(线性变换),这里仿射变换的方式 可以魔改。 其实在实现细节中可以魔改 的地方还有很多,例如,我们是否可以预先估计数据集的均值和方差呢 ?这实际上就是均值和方差初始化的魔改。我们可以先在数据集上运行一遍模型,只使用移动平均更新 BN,得到数据集均值和方差的估计,再进行正常地训练。笔者经常用这种方法初始化成对样本训练的模型,对于稳定模型性能很有帮助。 下面笔者将介绍这几种魔改方向的典型案例,希望能够抛砖引玉。由于篇幅有限,更多归一化方法请参考awesome-list(链接:https://github.com/tczhangzhi/awesome-normalization-techniques )。如果你已经有 idea 或正在参加比赛,可以使用其中的 code collections 进行魔改或 CV 研究,对于每种 Normalization,代码示例如下: import torch import torch.nn as nn import torch.nn.functional as F # 实现细节尽量贴合 official,使用习惯尽量贴合 pytorch class AdaptiveBatchNorm2d(nn.Module): """Adaptive Batch Normalization Parameters num_features – C from an expected input of size (N, C, H, W) eps – a value added to the denominator for numerical stability. Default: 1e-5 momentum – the value used for the running_mean and running_var computation. Can be set to None for cumulative moving average (i.e. simple average). Default: 0.1 affine – a boolean value that when set to True, this module has learnable affine parameters. Default: True Shape: Input: (N, C, H, W) Output: (N, C, H, W) (same shape as input) Examples: >>> m = AdaptiveBatchNorm2d(100) >>> input = torch.randn(20, 100, 35, 45) >>> output = m(input) """ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True): super(AdaptiveBatchNorm2d, self).__init__() self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine) self.a = nn.Parameter(torch.FloatTensor(1, 1, 1, 1)) self.b = nn.Parameter(torch.FloatTensor(1, 1, 1, 1)) def forward(self, x): return self.a * x + self.b * self.bn(x) # 这里是测试用例,可以作为示例使用 if __name__ == '__main__': m = AdaptiveBatchNorm2d(100) input = torch.randn(20, 100, 35, 45) output = m(input) 统计对象的魔改 笔者看来,该方向算是历史最久,研究最深入的魔改方向了。包括 Group Normization 在内的 5 个经典的魔改,仅通过修改统计对象的维度就在相应任务中取得了不错的结果。近年来,仍不断有新的工作结合语义信息在 feature map 上进一步划分统计范围,也让人耳目一新。 Layer Normalization 是作用于每个本上 (C, H, W) 的归一化方法(即计算 (C, H, W) 上的均值和方差),这样的归一化方式,使 batch 中的每个样本均可利用其本身的数据的进行归一化操作。更高效方便,也不存在更新均值和方差时,batch 内均值和方差不稳定的问题。在 NLP 中(Transformer)比较常用,CNN 上作用不大。 Instance Normalization 是作用于每个样本的每个通道上的归一化方法(即计算 (H, W) 上的均值和方差)。由于其计算均值和方差的粒度较细,在 low-level 的任务中(例如风格迁移)通常表现突出。在 GAN 网络的生成器中使用,IN 会降低生成图像中的网格感,使其更加自然。 在分类任务中,Layer Normalization 的粒度太粗,Instance Normalization 的粒度又显得过细。因此,Group Normalization 对二者进行了平衡,在一定数目的 channel 上进行归一化(即计算 (c, H, W) 上的均值和方差)。当 batch size 小于 8 的时候,通常使用 Group Normalization 代替 Batch Normalization,对训练好的模型 fineture,效果还不错。 Switchable Normalization 是将 Batch Normalization、Layer Normalization 和 Instance Normalization 自动结合的懒人版。其归一化操作是上述三个归一化操作结果的加权和,加权系数由网络自己学习(softmax)。这种设计允许模型自适应地选择归一化的粒度完成指定任务。个人较少使用,会影响收敛速度。 Sync Batch Normalization 是为跨卡(GPU)同步提出的 Batch Normalization。SN 能够帮助我们屏蔽多卡训练的分布式细节,将分散在每个 GPU 上的 batch 合并,视为一个机器上的一个 batch。其关键是在前向运算的时候,计算并同步全局(所有 GPU 上 batch)的均值和方差;在反向运算时候,同步相应的全局梯度。笔者会在比赛中使用,以更快得到初步结果,但是在研究中往往不需要那么大 batch。 Sparse Switchable Normalization Sparse Switchable Normalization 是 Switchable Normalization 的改进版。通过稀疏约束,使用 sparsestmax 替代了 softmax,在保持性能的同时减少了 switchable 的计算量,增加了鲁棒性。文章的行文很棒,推荐一读。 Region Normalization 在 Batch Normalization 的基础上进一步对 (N, H, W) 中的 (H, W) 进行了划分。Region Normalization 根据输入掩码将空间像素划分为不同的区域,并计算每个区域的均值和方差以进行归一化。实现时只需将输入先进行 mask,再输入 BN 即可。 Local Context Normalization Local Context Normalization 在 Layer Normalization 的基础上对 (C, H, W) 进行了划分。Local Context Normalization 根据每个特征值所在的局部邻域,计算邻域的均值和方差以进行归一化。实现时作者借助了空洞卷积获取 window 内均值和方差,比较巧妙。 Cross-Iteration Batch Normalization Cross-Iteration Batch Normalization 在 Batch Normalization 的基础上,希望使用多个 iteration 的 batch 组成更大的样本空间,形成对均值和方差更准确的估计。文章主要解决的问题是,第 Split Batch Normalization Split Batch Normalization 根据样本是否有标签,在 sample 层面将 batch 内的样本分为了两组,分别进行统计。这种分组的思想是 stable 的,笔者在实践过程中发现还可以根据 class 或者 feature 分组,不过该文章似乎没有进行过多的探讨。 Domain-Specific Batch Normalization Domain-Specific Batch Normalization 与 Split Batch Normalization 类似,都针对 sample 的不同进行了分组。不同的是,在 Domain adaptation 任务中,Domain-Specific Batch Normalization 选择对 source domain 和 target domain 进行分组。在计算时,干脆创建了两个 Batch Normalization,根据 domain 选择相应的分支输入。 顾名思义,在 channel 维度求统计量,对 tensor 进行归一化。作者生成,这种设计可以在一定程度上解决梯度弥散的问题。然而,在具体 task 中用梯度弥散来描述问题似乎过于泛泛而谈了,因此笔者恐怕很难用到这个方法。 规范化方式的魔改 随着这一块研究的深入,笔者愈发崇拜 BN 的精妙之处。笔者也尝试了使用不同的方式,利用整体的统计特征,将 element 规范化到 [0, 1] 之间。但性能都与 BN 没什么差异,反而消耗了大量的计算时间。可能这就是深度学习所推崇的 "simple is the best" 吧。向在这个道路上努力的大佬致敬~ Filter Response Normalization Filter Response Normalization 改进了 Instance Normalization,在 (H, W) 维度上计算统计量。不同的是,Filter Response Normalization 并不计算平均值,在规范化的过程中,直接使用每个元素除以 (H, W) 维度二范数的平均值。由于缺少减去均值的操作,因此归一化的结果可能会产生偏移(不以 0 为中心),这对于后续的 ReLU 激活是不利的。因此,作者还提出了配套的激活函数 TLU。(其实 TLU 单独使用也挺好用的) Extended Batch Normalization Extended Batch Normalization 改进了 Batch Normalization。虽然仍使用均值和方差进行规范化,不同之处在于,Extended Batch Normalization 在 (N, H, W) 的维度上求平均值,在 (N, C, H, W) 的维度上求方差。直观上看,统计元素数量的增多使得方差更为稳定,因而能够在小 batch 上取得较好的效果。 Kalman Normalization 改进了 Batch Normalization,使得不同层之间的统计量得以相互关联。在 Kalman Normalization,当前归一化层的均值和方差是通过和上一个归一化层的均值和方差进行卡尔曼滤波得到的(可以简单理解当前状态为加权历史状态),其在大尺度物体检测和风格任务上都取得了较好的效果。笔者猜测其能够在融合不同尺度信息上表现出一定优势,但经过尝试没有发现提高。 L1-Norm Batch Normalization L1-Norm Batch Normalization 将 Batch Normalization 中的求方差换成了 L1 范数。在 GAN 中表现出了较好的效果。感兴趣的同学可以使用上文中提到的代码仓库中的 startkit 修改一下 var 操作感受一下魔改的快乐~(逃 提出使用 cosine similarity 进行归一化,文章使用 PCC 将其转化为了公式 13。虽然目前受到的关注有限,但是笔者猜测其可以用在 domain adaption 等领域中(虽然笔者的尝试失败了)。 仿射变换方式的魔改 学习,可以说是深度学习最擅长的领域了。最初的仿射变换,当然也可以学习其他更多的特征。尽管这个方向的魔改发展最为迅速,笔者仍站在旧势力的阵营:谁知道这是不是"聪明的汉斯"呢?毕竟参数量为王。不过不可否认的是,该领域的工作确实为引入其他先验信息的方式开辟了一条新的道路,我们手里的武器不再只有 "feature map 层面" 的 fusion 和 attention 了~ Conditional Batch/Instance Normalization Conditional Batch Normalization 在 Batch Normalization 的基础上改进了仿射变换的部分。它使用 LSTM 和多层感知器,将自然语言映射为一组特征向量,作为仿射变换的权重 γ 和偏置 β 引导后续任务。Conditional Instance Normalization 则是对 style 信息进行编码,使用在风格迁移中(正如之前所介绍的,Instance Normalization 在 low-level 任务中更有优势)。笔者认为,二者都可以看作使用 attention 机制引入了外部信息。 Adaptive Instance Normalization Adaptive Instance Normalization 进一步放宽了权重 γ 和偏置 β 在风格迁移中的估计方法。作者提出的方法不再需要一个单独的 style 特征提取模块,对于给定的风格图像和原始图像都使用相同的 backbone (VGG)提取特征,用风格图像算出权重 γ 和偏置 β ,用于原始图像的仿射变换中。 Adaptive Convolution-based Normalization Adaptive Convolution-based Normalization 是 Adaptive Instance Normalization 的改良版。不同之处在于,Adaptive Convolution-based Normalization 在仿射变换的过程中,使用一个动态的卷积层完成。这时的仿射变换已经漏出了卷积的獠牙,传统意义上的仿射变换名存实亡。 Spatially-Adaptive Normalization Spatially-Adaptive Normalization 在使用均值和方差将每个元素标准化到 [0,1] 后,在仿射变换层融入了 mask 引导的 attention 机制。作者首先使用卷积层对 mask 进行变换,在得到的 feature map 上分别使用两个卷积层得到权重 γ 和偏置 β 的估计。最后使用权重 γ 和偏置 β 的估计对归一化的结果进行 element-wise 的乘加操作,完成归一化。 Region-Adaptive Normalization Region-Adaptive Normalization 在 Spatially-Adaptive Normalization 的基础上进行了 style map 和 segmentation mask 两个 branch 的 fusion。分别使用 style map 和 mask 套用 Spatially-Adaptive Normalization 得到权重 γ 和偏置 β 的估计,再将两个 branch 的估计加权平均,得到最终的估计。而后进行仿射变换完成归一化。 Instance Enhancement Batch Normalization Instance Enhancement Batch Normalization 对权重 γ 的估计则更为简单粗暴。在使用时,不需要引入 mask 等额外信息做引导,由网络自适应地学习。作者借鉴了 SENet 的思路,通过池化、变换、Sigmoid 得到一组权重 γ 。这使得 Instance Enhancement Batch Normalization 具有很强的通用性,尽管参数量有所提升,但是即插即用无痛涨点。 Attentive Normalization 与 Instance Enhancement Batch Normalization 的方法类似。笔者认为 Attentive Normalization 这个名称似乎更加形象一些。 后记 由于近期杂七杂八的工作很多,笔者阅读文献和复现代码的时间并不多。有很多优秀的工作只来得及总结到 awesome list 中,并未阅读。因此这里只能抛砖引玉,等大佬们能为我等 ctrl c+ctrl v 工程师开路了~感兴趣的同学可以参考 awesome-list,欢迎大家提 issue 和 pr 呀~ 其实,有些蓝海只是还未受到关注的红海,今天爱理不理,明天可能就高攀不起了,譬如深度学习的安全领域。可能有些时候,还是需要一些科研直觉的吧。当大佬拍脑袋的时候,笔者只能拍大腿:当时为啥我就想不到呢......
添加极市小助手微信 (ID : cv-mart) ,备注: 研究方向-姓名-学校/公司-城市 (如:目标检测-小极-北大-深圳),即可申请加入 极市技术交流群 ,更有 每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、 干货资讯汇总、行业技术交流 , 一起来让思想之光照的更远吧~ 觉得有用麻烦给个在看啦~