
特斯拉的计算机视觉
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


根据埃隆·马斯克(Elon Musk)的说法,截至2020年7月初,特斯拉接近于自动驾驶汽车,也称为5级自动驾驶。无论是真的还是假的,一件事情变得越来越清晰:特斯拉已准备好在其他任何人之前实现完全的自主权。一旦他们这样做,其他人可能很快就会跟进。

特斯拉实现了5级自主权,相当于运动员罗杰·班尼斯特(Roger Bannister)首次在4分钟内跑了一英里。直到罗杰·班尼斯特(RogerBannister)做到了,然后所有人突然跟随,这项任务才被认为是可能完成的。
特斯拉汽车有什么作用?
包括特斯拉在内的任何自动驾驶汽车的主要功能是保持在正确的车道上,然后改变车道以遵循正确的轨迹。显然,诸如障碍物检测之类的任务占了很大一部分。Smart Summon等其他功能使汽车可以在停车场找到驾驶员。这些额外的任务,除其他外,加入了主要的车道和轨迹功能,以朝着长期目标迈进:全面的自动驾驶功能。
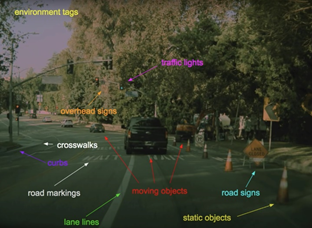
特斯拉需要处理的所有情况
特斯拉的任务今天众所周知。从自动驾驶汽车的最重要功能-车道检测到行人跟踪,它们必须涵盖一切并预测每种情况。为此,他们使用传感器。
特斯拉正在使用8个摄像头来运行。这样,它们可以覆盖车辆周围的所有区域,因此不会出现盲区。8台摄像机与其他RADAR融合在一起,因此它们可以有效地定位并识别障碍物。RADAR是非常好的互补传感器,因为它们可以直接估计速度。
这些相机图像如何处理?使用神经网络。
在车辆,车道线,路缘,人行横道以及所有其他特定的环境变量之间,特斯拉还有很多工作要做。实际上,他们必须至少同时运行50个神经网络才能使其正常运行。这在标准计算机上是不可能的。特斯拉使用称为HydraNets的特定架构,在该架构中共享主干。
与转移学习类似,在这里您有一个通用块并为特定的相关任务训练特定的块,HydraNets的骨干网针对所有对象进行了培训,而负责人则针对特定任务进行了培训。这提高了推理速度以及训练速度。
使用PyTorch(您可能熟悉的深度学习框架)来训练神经网络。
每个尺寸为(1280,960,3)的图像都将通过此特定的神经网络传递。
骨干网是经过修改的ResNet 50 —具体的修改是使用“ Divolution卷积”。
这些头基于语义分段-FPN / DeepLab / UNet体系结构。但是,这似乎并不是“最终任务”,因为2D像素和3D之间的转换容易出错。
同时,特斯拉使用的其他东西是鸟瞰图,因为有时候i必须以3D形式解释神经网络的结果。鸟瞰图可以帮助估计距离并提供对世界的更好更好的了解。
有些任务在多台摄像机上运行。例如,深度估计是我们通常在立体摄像机上执行的操作。拥有2个摄像头有助于更好地估计距离。特斯拉使用神经网络进行深度回归。


2台摄像机深度估算
使用这种立体视觉和传感器融合,特斯拉不需要LiDAR。他们可以仅基于这两个摄像机进行距离估计。唯一的窍门是相机不使用相同的镜头:在右边,更远的距离显得更近。
特斯拉还经常进行诸如道路布局估算的工作。这个想法很相似:多个神经网络分别运行,另一个神经网络正在建立连接。
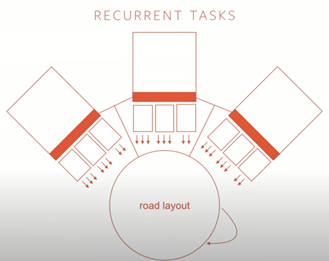
该神经网络可以是递归的,特斯拉的主要问题是它使用8个摄像头,16个时间步长(循环体系结构)和32个批处理量。
这意味着每向前通过,将处理4096张图像。实际上,一个GPU无法做到这一点-甚至没有两个GPU!为了解决这个问题,特斯拉将赌注押在HydraNet架构上。 每个摄像机都通过单个神经网络进行处理。然后将所有内容组合到中间神经网络中。令人惊奇的是,每个任务仅需要这个庞大网络的几个部分。
例如,对象检测可以只需要前置摄像头,前置主干和第二个摄像头。并非所有内容都以相同的方式处理。

特斯拉使用的8个主要神经网络
网络培训是使用PyTorch完成的。需要执行多个任务,并且在所有48个神经网络头上进行训练都可能要花费大量时间。实际上,培训需要70,000个小时的GPU才能完成。差不多8年了。
特斯拉正在将培训模式从“轮循”转变为“工人池”。这是想法:左侧-长而不可能的选择。在中间和右边,它们使用的替代方案。
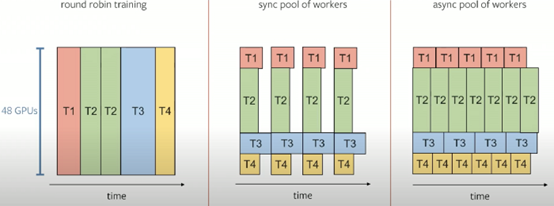
在那部分上,我们没有太多细节要分享,但是从本质上讲,这些工人池会并行执行任务以使网络更快。
我们希望您现在对它在那里的工作方式有一个清晰的认识。这不是不可能理解的,但是我们可能有些不同。因为它涉及非常复杂的现实世界问题。在理想的世界中,您将不需要HydraNet架构-您只需为每个图像和每个任务使用一个神经网络即可,但是今天这是不可能的。
除此之外,特斯拉还必须不断改进其软件。他们必须收集和利用用户的数据。毕竟,他们有成千上万的车辆驶出那里,如果不使用他们的数据来改进他们的模型,那将是愚蠢的。每个数据都被收集,标记并用于训练;与称为主动学习的过程类似
让我们从底部到顶部定义堆栈。数据-特斯拉从车辆收集数据,并由团队标记。
GPU集群— Tesla使用多个GPU(称为集群)来训练其神经网络并运行它们。DOJO —特斯拉使用一种称为dojo的东西来仅训练整个体系结构的一部分来完成特定任务。这与他们的推论非常相似。
PyTorch分布式培训—特斯拉使用PyTorch进行培训。评估—特斯拉使用损失函数评估网络培训。云推理—云处理使特斯拉可以同时改善其车队。@FSD推理—特斯拉建立了自己的计算机,该计算机具有自己的神经处理单元(NPU)和GPU用于推理。阴影模式-特斯拉从车辆收集结果和数据,并将其与预测结果进行比较,以帮助改进注释:这是一个闭环!
特斯拉正在同时执行50个任务,这些任务必须全部在称为FSD(完全自驾车)的小型计算机上运行。
为此,他们使用HydraNet体系结构,该体系结构使他们可以为每个任务使用相同的网络,只是使用不同的主管。所有头部都涉及图像分割。特斯拉使用8台融合在一起的相机。并非每个摄像机都用于单个任务。训练是使用PyTorch和一组工作人员架构完成的(某些任务是同时进行培训的)。
实现了一个完整的循环:驱动程序收集数据,特斯拉标记实际数据,并在其上训练系统。
 End
End 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~