
一文了解机器学习
来源:DeepHub IMBA
本文约2300字,建议阅读8分钟
本文介绍了机器学习的种类。
机器学习
机器学习根据不同的任务类型可以分为以下三大类型:
有监督学习
无监督学习
强化学习
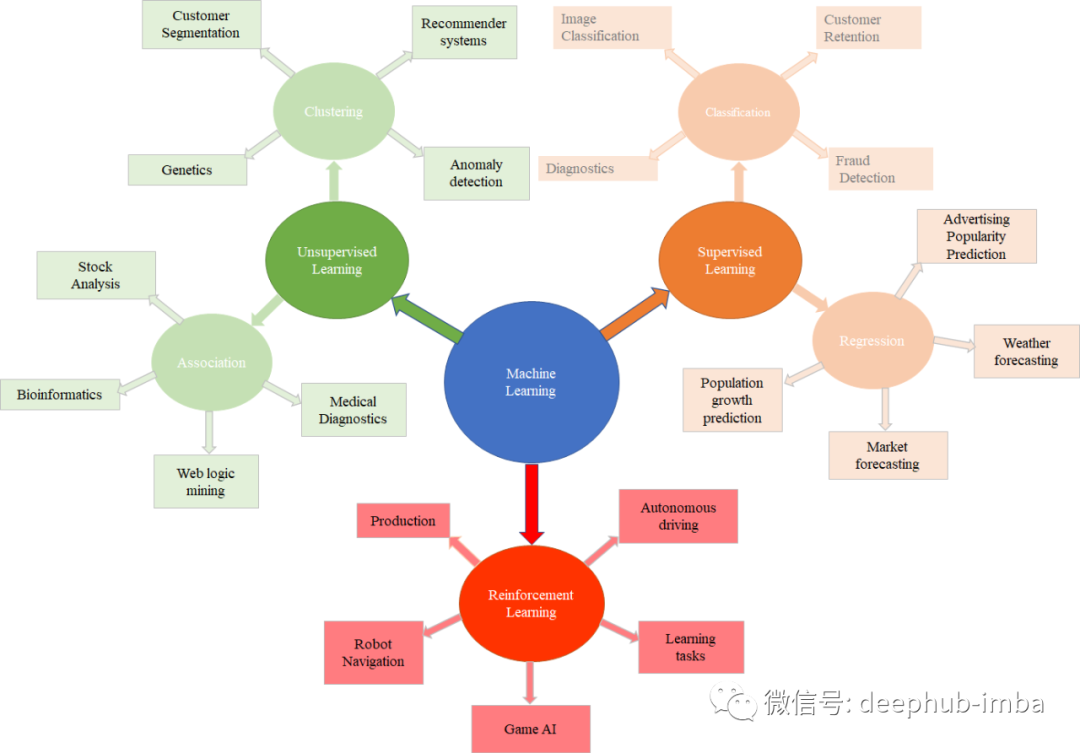
有监督学习
在这种类型中,机器学习算法是在标记数据上训练的。尽管这种方法需要准确地标记数据,但在适当的情况下使用监督学习是非常有效的。
开始时,系统接收输入数据和输出数据。它的任务是创建适当的规则,将输入映射到输出。训练过程应该持续,直到表现水平足够高为止。
在训练之后,系统应该能够分配一个在训练阶段没有看到的输出对象。在大多数情况下,这个过程是非常快速和准确的。
监督学习的类型:
Regression:回归,输出是连续值
Classification:分类,输出是离散值
回归
回归是一种有监督的机器学习技术,用于预测连续值。例如,我们可以用它来预测某种产品的价格,比如某个城市的房价或股票的价值。
机器学习中的回归由数学方法组成,数据科学家可以根据一个或多个预测变量(x)的值预测一个连续的结果(y)。线性回归可能是回归分析中最流行的形式,因为它在预测和预测中很容易使用。
分类
分类是一种旨在重现类别分配的技术。它可以预测响应值,并将数据分成“类”。例如识别照片中的汽车类型,鉴别垃圾邮件,检测表情,人脸识别等等。
分类的三种主要类型是:
二元分类 Binary Classification
它是分类的过程或任务,其中将给定的数据分为两类。它基本上是一种关于事物属于两个群体中的哪一个的预测。
假设有两封电子邮件发送给您,一封是由不断发送广告的保险公司发送的,另一封是您的银行发送的关于您的信用卡账单的电子邮件。
电子邮件服务提供商将对两封电子邮件进行分类,第一封将发送到垃圾邮件文件夹,第二封将保留在主邮件中。这个过程被称为二元分类,因为有两个离散的类,一个是垃圾邮件,另一个不是垃圾邮件的。所以这是一个二元分类的问题。
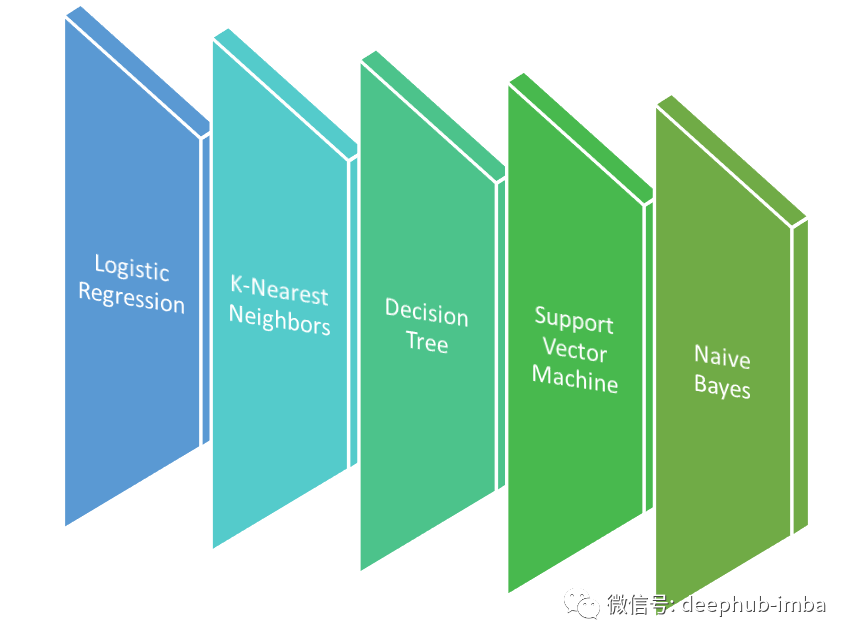
算法:
逻辑回归
KNN
决策树/随机森林/提升树
支持向量机 SVM
朴素贝叶斯
多层感知机
多分类 Multi-class Classification
多类分类是指那些具有两个以上类标签,但是输入数据只对应一个类标签的分类任务。
算法:
KNN
决策树/随机森林/提升树
朴素贝叶斯
多层感知机
注:这里去掉了SVM和逻辑回归,因为他们只支持二分类,但是可以通过其他方法实现多分类,一般情况下会构建与分类数相同的模型并进行二元分类,比如数字识别0-9,SVM会训练10个二元模型,分别判断是否是1,是否是2,逻辑回归也是同理。

多标签分类 Multi-Label Classification
多标签分类是指那些具有两个或多个类标签的分类任务,其中每个示例可以预测一个或多个类标签。
多分类可以叫做单标签多分类,是一对一的关系,而多标签分类是一对多的关系。
通俗的讲,一张照片里面有猫和狗,如果使用多分类来说,他只能将照片分成1类,猫或狗(一对一),但是对于多标签来说,会同时输出猫和够(一对多)
无监督学习
无监督学习算法可以执行比监督学习系统更复杂的处理任务。
无监督学习的类型:
A.聚类
聚类是指自动将具有相似特征的数据点组合在一起并将它们分配给“簇”的过程。
常用算法:
K-Means(K均值)
DBSCAN
使用高斯混合模型(GMM)
B.关联
关联规则学习是一种无监督学习技术,它在大型数据中检查一个数据项对另一个数据项的依赖性 ,它试图在数据集的变量之间找到一些有趣的关系或关联。根据不同的规则来发现数据中变量之间的有趣关系。
常用算法:
Apriori算法
PCY算法
FP-Tree算法
XFP-Tree算法
GPApriori算法
市场分析:是关联规则挖掘的流行示例和应用之一。大型零售商通常使用这种技术来确定商品之间的关联。(啤酒尿布)
医学诊断:关联规则有助于识别特定疾病的患病概率。
蛋白质序列:关联规则有助于确定人工蛋白质的合成。
强化学习
尽管监督学习和强化学习都使用输入和输出之间的映射,但与向代理提供的反馈是执行任务的正确动作集的监督学习不同,强化学习使用奖励和惩罚作为积极和消极行为的信号。
与无监督学习相比,强化学习在目标方面有所不同。虽然无监督学习的目标是找到数据点之间的异同,但在强化学习的情况下,目标是找到一个合适的动作模型,使代理的总累积奖励最大化。
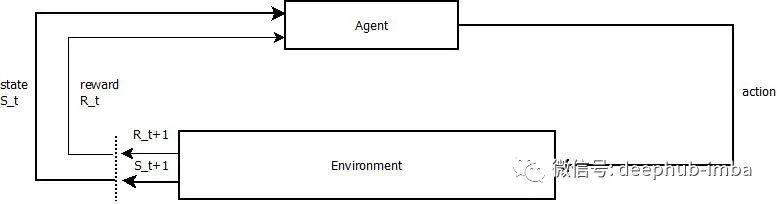
描述 RL 问题基本要素的一些关键术语是:
- 环境Environment ——代理运行的物理世界
- 代理Agent ——也叫智能体,就是我们所写的算法
- 行动Action——代理产生的动作
- 状态State——代理的状态
- 奖励Reward——来自环境的反馈,好的还是坏的
- 策略Policy ——将代理的状态映射到动作的方法,通过状态选择做什么行动
- 价值Value ——代理在特定状态下采取行动将获得的未来奖励
deephub译者注
对于实现的方法,我们还可以根据模型分成不同的实现方法,例如:
传统的机器学习:各种回归
核方法:SVM等
贝叶斯模型:概率相关
树型模型:决策树、随机森林、各种boosting
神经网络:多层感知机、各种NN
以上分类并不冲突并且是交叉的。最简单的就是我们在使用神经网络分类和回归的时候,最后一层一般都会使用线性层(有的也叫稠密层)这一层使用的算法就是线性回归,再例如我们也可以使用神经网络来进行聚类算法,比如deepCluster。
本文内容来源以上网址及公众号。以上内容仅供学习使用,不作其它用途,如有侵权,请留言联系,作删除处理!
有任何疑问及建议,扫描以下公众号二维码添加交流:
评论