
【机器学习】一文彻底搞懂自动机器学习AutoML:Auto-Sklearn
本文将系统全面的介绍自动机器学习的其中一个常用框架: Auto-Sklearn,介绍安装及使用,分类和回归小案例,以及一些用户手册的介绍。
AutoML
自动化机器学习AutoML 是机器学习中一个相对较新的领域,它主要将机器学习中所有耗时过程自动化,如数据预处理、最佳算法选择、超参数调整等,这样可节约大量时间在建立机器学习模型过程中。
自动机器学习 AutoML: 对于 ,令 表示特征向量, 表示对应的目标值。给定训练数据集 和从与之具有相同数据分布中得出的测试数据集 的特征向量 ,以及资源预算 和损失度量 ,AutoML 问题是自动生成测试集的预测值 ,而 给出了 AutoML 问题的解 的损失值。
AutoML,是为数据集发现数据转换、模型和模型配置的最佳性能管道的过程。
AutoML 通常涉及使用复杂的优化算法(例如贝叶斯优化)来有效地导航可能模型和模型配置的空间,并快速发现对给定预测建模任务最有效的方法。它允许非专家机器学习从业者快速轻松地发现对于给定数据集有效甚至最佳的方法,而技术背景或直接输入很少。
使用过 sklearn 的话,对于上面定义应该不难理解。下面再结合一个流程图来进一步理解一下。

Auto-Sklearn
Auto-Sklearn是一个开源库,用于在 Python 中执行 AutoML。它利用流行的 Scikit-Learn 机器学习库进行数据转换和机器学习算法。
它是由Matthias Feurer等人开发的。并在他们 2015 年题为“efficient and robust automated machine learning 高效且稳健的自动化机器学习[1]”的论文中进行了描述。
… we introduce a robust new AutoML system based on scikit-learn (using 15 classifiers, 14 feature preprocessing methods, and 4 data preprocessing methods, giving rise to a structured hypothesis space with 110 hyperparameters)
我们引入了一个基于 scikit-learn 的强大的新 AutoML 系统(使用 15 个分类器、14 个特征预处理方法和 4 个数据预处理方法,产生具有 110 个超参数的结构化假设空间)。
Auto-Sklearn 的好处在于,除了发现为数据集执行的数据预处理和模型之外,它还能够从在类似数据集上表现良好的模型中学习,并能够自动创建性能最佳的集合作为优化过程的一部分发现的模型。
This system, which we dub AUTO-SKLEARN, improves on existing AutoML methods by automatically taking into account past performance on similar datasets, and by constructing ensembles from the models evaluated during the optimization.
这个我们称之为 AUTO-SKLEARN 的系统通过自动考虑过去在类似数据集上的表现,并通过在优化期间评估的模型构建集成,改进了现有的 AutoML 方法。
Auto-Sklearn 是改进了一般的 AutoML 方法,自动机器学习框架采用贝叶斯超参数优化方法,有效地发现给定数据集的性能最佳的模型管道。
这里另外添加了两个组件:
一个用于初始化贝叶斯优化器的元学习( meta-learning)方法优化过程中的自动集成( automated ensemble)方法
这种元学习方法是贝叶斯优化的补充,用于优化 ML 框架。对于像整个 ML 框架一样大的超参数空间,贝叶斯优化的启动速度很慢。通过基于元学习选择若干个配置来用于种子贝叶斯优化。这种通过元学习的方法可以称为热启动优化方法。再配合多个模型的自动集成方法,使得整个机器学习流程高度自动化,将大大节省用户的时间。从这个流程来看,让机器学习使用者可以有更多的时间来选择数据以及思考要处理的问题本身。
贝叶斯优化
贝叶斯优化的原理是利用现有的样本在优化目标函数中的表现,构建一个后验模型。该后验模型上的每一个点都是一个高斯分布,即有均值和方差。若该点是已有样本点,则均值就是该点的优化目标函数取值,方差为0。而其他未知样本点的均值和方差是后验概率拟合的,不一定接近真实值。那么就用一个采集函数,不断试探这些未知样本点对应的优化目标函数值,不断更新后验概率的模型。由于采集函数可以兼顾Explore/Exploit,所以会更多地选择表现好的点和潜力大的点。因此,在资源预算耗尽时,往往能够得到不错的优化结果。即找到局部最优的优化目标函数中的参数。
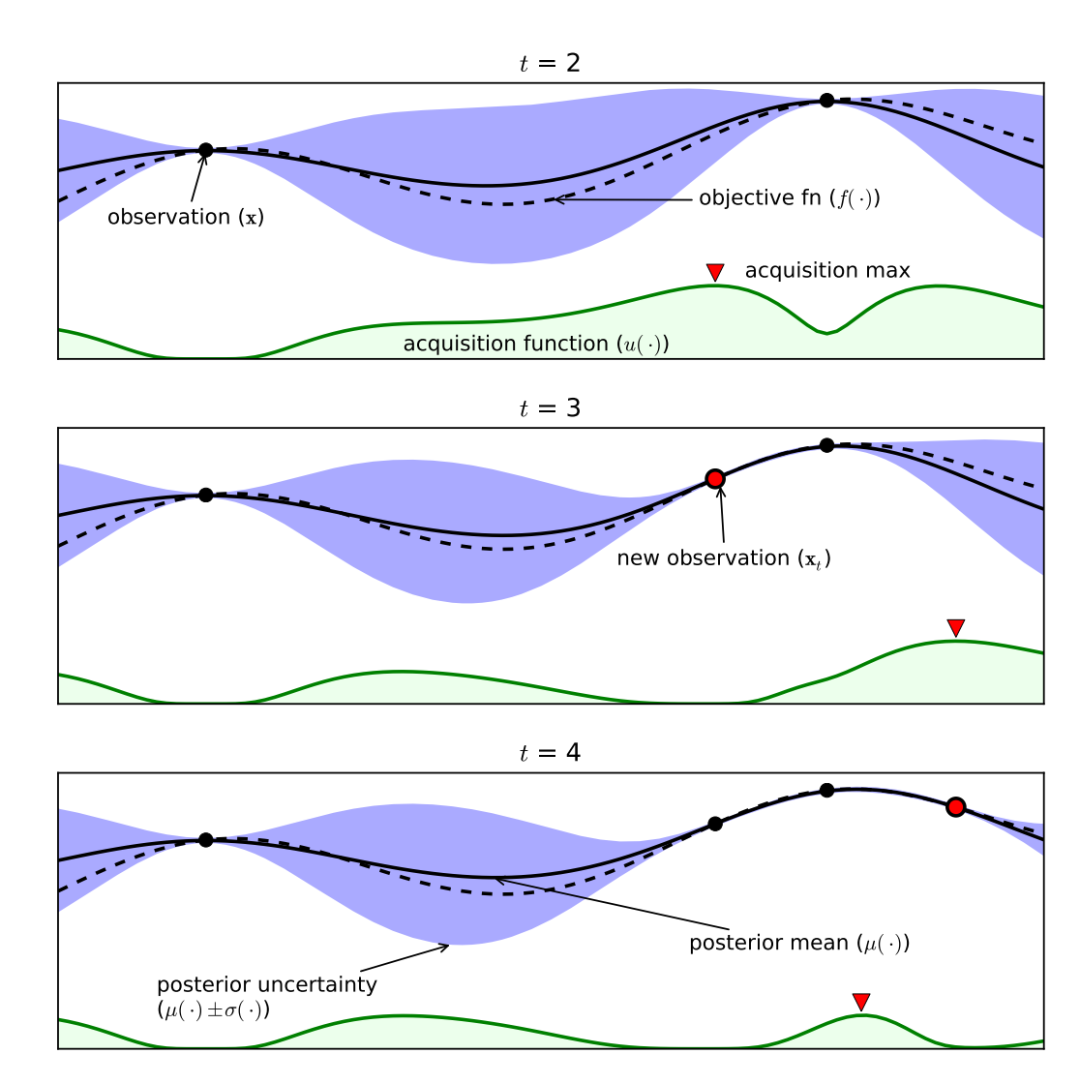
上图是在一个简单的 1D 问题上应用贝叶斯优化的实验图,这些图显示了在经过四次迭代后,高斯过程对目标函数的近似。我们以 t=3 为例分别介绍一下图中各个部分的作用。
上图 2 个 evaluations 黑点和一个红色 evaluations,是三次评估后显示替代模型的初始值估计,会影响下一个点的选择,穿过这三个点的曲线可以画出非常多条。黑色虚线曲线是实际真正的目标函数 (通常未知)。黑色实线曲线是代理模型的目标函数的均值。紫色区域是代理模型的目标函数的方差。绿色阴影部分指的是acquisition function的值,选取最大值的点作为下一个采样点。只有三个点,拟合的效果稍差,黑点越多,黑色实线和黑色虚线之间的区域就越小,误差越小,代理模型越接近真实模型的目标函数。
安装和使用 Auto-Sklearn
Auto-sklearn 提供了开箱即用的监督型自动机器学习。从名字可以看出,auto-sklearn 是基于机器学习库 scikit-learn 构建的,可为新的数据集自动搜索学习算法,并优化其超参数。因此,它将机器学习使用者从繁琐的任务中解放出来,使其有更多时间专注于实际问题。
这里可以参考auto-sklearn官方文档[2]。
ubuntu
>>> sudo apt-get install build-essential swig
>>> conda install gxx_linux-64 gcc_linux-64 swig
>>> curl `https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt` | xargs -n 1 -L 1 pip install
>>> pip install auto-sklearn
anaconda
pip install auto-sklearn
安装后,我们可以导入库并打印版本号以确认它已成功安装:
# print autosklearn version
import autosklearn
print('autosklearn: %s' % autosklearn.__version__)
你的版本号应该相同或更高。
autosklearn: 0.6.0
根据预测任务的不同,是分类还是回归,可以创建和配置 AutoSklearnClassifier[3] 或 AutoSklearnRegressor[4]类的实例,将其拟合到数据集上,仅此而已。然后可以使用生成的模型直接进行预测或保存到文件(使用pickle)以供以后使用。
AutoSklearn类参数
AutoSklearn 类提供了大量的配置选项作为参数。
默认情况下,搜索将在搜索过程中使用数据集的train-test拆分,为了速度和简单性,这里建议使用默认值。
参数n_jobs可以设置为系统中的核心数,如有 8 个核心,则为n_jobs=8。
一般情况下,优化过程将持续运行,并以分钟为单位进行测量。默认情况下,它将运行一小时。
这里建议将time_left_for_this_task参数此任务的最长时间(希望进程运行的秒数)。例如,对于许多小型预测建模任务(少于 1,000 行的数据集)来说,不到 5-10 分钟可能就足够了。如果没有为此参数指定任何内容,则该过程将优化过程将持续运行,并以分钟为单位进行测量,将运行一小时,即60分钟。本案例通过 per_run_time_limit 参数将分配给每个模型评估的时间限制为 30 秒。例如:
# define search
model = AutoSklearnClassifier(time_left_for_this_task=5*60,
per_run_time_limit=30,
n_jobs=8)
另外还有其他参数,如ensemble_size、initial_configurations_via_metalearning,可用于微调分类器。默认情况下,上述搜索命令会创建一组表现最佳的模型。为了避免过度拟合,我们可以通过更改设置 ensemble_size = 1 和initial_configurations_via_metalearning = 0来禁用它。我们在设置分类器时排除了这些以保持方法的简单。
在运行结束时,可以访问模型列表以及其他详细信息。sprint_statistics()函数总结了最终模型的搜索和性能。
# summarize performance
print(model.sprint_statistics())
分类任务
在本节中,我们将使用 Auto-Sklearn 来发现声纳数据集的模型。
声纳数据集[5]是一个标准的机器学习数据集,由 208 行数据和 60 个数字输入变量和一个具有两个类值的目标变量组成,例如二进制分类。
使用具有三个重复的重复分层 10 倍交叉验证的测试工具,朴素模型可以达到约 53% 的准确度。性能最佳的模型可以在相同的测试工具上实现大约 88% 的准确度。这提供了该数据集的预期性能界限。
该数据集涉及预测声纳返回是否指示岩石或模拟矿井。
# summarize the sonar dataset
from pandas import read_csv
# load dataset
dataframe = read_csv(data, header=None)
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
print(X.shape, y.shape)
运行该示例会下载数据集并将其拆分为输入和输出元素。可以看到有 60 个输入变量的 208 行数据。
(208, 60) (208,)
首先,将数据集拆分为训练集和测试集,目标在训练集上找到一个好的模型,然后评估在保留测试集上找到的模型的性能。
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
使用以下命令从 autosklearn 导入分类模型。
from autosklearn.classification import AutoSklearnClassifier
AutoSklearnClassifier配置为使用 8 个内核运行 5 分钟,并将每个模型评估限制为 30 秒。
# define search
model = AutoSklearnClassifier(time_left_for_this_task=5*60,
per_run_time_limit=30, n_jobs=8,
tmp_folder='/temp/autosklearn_classification_example_tmp')
这里提供一个临时的日志保存路径,我们可以在以后使用它来打印运行详细信息。
然后在训练数据集上执行搜索。
# perform the search
model.fit(X_train, y_train)
报告搜索和最佳性能模型的摘要。
# summarize
print(model.sprint_statistics())
可以使用以下命令为搜索考虑的所有模型打印排行榜。
# leaderboard
print(model.leaderboard())
可以使用以下命令打印有关所考虑模型的信息。
print(model.show_models())
我们还可以使用SMOTE、集成学习(bagging、boosting)、NearMiss 算法等技术来解决数据集中的不平衡问题。
最后评估在测试数据集上模型的性能。
# evaluate best model
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("Accuracy: %.3f" % acc)
还可以打印集成的最终分数和混淆矩阵。
# Score of the final ensemble
from sklearn.metrics import accuracy_score
m1_acc_score= accuracy_score(y_test, y_pred)
m1_acc_score
from sklearn.metrics import confusion_matrix, accuracy_score
y_pred= model.predict(X_test)
conf_matrix= confusion_matrix(y_pred, y_test)
sns.heatmap(conf_matrix, annot=True)
在运行结束时,会打印一个摘要,显示评估了 1,054 个模型,最终模型的估计性能为 91%。
auto-sklearn results:
Dataset name: f4c282bd4b56d4db7e5f7fe1a6a8edeb
Metric: accuracy
Best validation score: 0.913043
Number of target algorithm runs: 1054
Number of successful target algorithm runs: 952
Number of crashed target algorithm runs: 94
Number of target algorithms that exceeded the time limit: 8
Number of target algorithms that exceeded the memory limit: 0
然后在holdout数据集上评估模型,发现分类准确率达到了 81.2% ,这是相当熟练的。
Accuracy: 0.812
回归任务
在本节中,使用 Auto-Sklearn 来挖掘汽车保险数据集的模型。
汽车保险数据集[6]是一个标准的机器学习数据集,由 63 行数据组成,一个数字输入变量和一个数字目标变量。
使用具有三个重复的重复分层 10 折交叉验证的测试工具,朴素模型可以实现约 66 的平均绝对误差 (MAE)。性能最佳的模型可以在相同的测试工具上实现约 28 的 MAE . 这提供了该数据集的预期性能界限。
该数据集涉及根据不同地理区域的索赔数量预测索赔总额(数千瑞典克朗)。
可以使用与上一节相同的过程,尽管我们将使用AutoSklearnRegressor类而不是AutoSklearnClassifier。
默认情况下,回归器将优化 指标。如果需要使用平均绝对误差或 MAE ,可以在调用fit()函数时通过metric参数指定它。
# example of auto-sklearn for the insurance regression dataset
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from autosklearn.regression import AutoSklearnRegressor
from autosklearn.metrics import mean_absolute_error as auto_mean_absolute_error
# load dataset
dataframe = read_csv(data, header=None)
# split into input and output elements
data = dataframe.values
data = data.astype('float32')
X, y = data[:, :-1], data[:, -1]
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.33,
random_state=1)
# define search
model = AutoSklearnRegressor(time_left_for_this_task=5*60,
per_run_time_limit=30, n_jobs=8)
# perform the search
model.fit(X_train, y_train, metric=auto_mean_absolute_error)
# summarize
print(model.sprint_statistics())
# evaluate best model
y_hat = model.predict(X_test)
mae = mean_absolute_error(y_test, y_hat)
print("MAE: %.3f" % mae)
在运行结束时,将打印一个摘要,显示评估了 1,759 个模型,最终模型的估计性能为 29 的 MAE。
auto-sklearn results:
Dataset name: ff51291d93f33237099d48c48ee0f9ad
Metric: mean_absolute_error
Best validation score: 29.911203
Number of target algorithm runs: 1759
Number of successful target algorithm runs: 1362
Number of crashed target algorithm runs: 394
Number of target algorithms that exceeded the time limit: 3
Number of target algorithms that exceeded the memory limit: 0
保存训练好的模型
上面训练的分类和回归模型可以使用 python 包 Pickle 和 JobLib 保存。然后可以使用这些保存的模型直接对新数据进行预测。我们可以将模型保存为:
1、Pickle
import pickle
# save the model
filename = 'final_model.sav'
pickle.dump(model, open(filename, 'wb'))
这里的"wb"参数意味着我们正在以二进制模式将文件写入磁盘。此外,我们可以将此保存的模型加载为:
#load the model
loaded_model = pickle.load(open(filename, 'rb'))
result = loaded_model.score(X_test, Y_test)
print(result)
这里的"rb"命令表示我们正在以二进制模式读取文件
2、JobLib
同样,我们可以使用以下命令将训练好的模型保存在 JobLib 中。
import joblib
# save the model
filename = 'final_model.sav'
joblib.dump(model, filename)
我们还可以稍后重新加载这些保存的模型,以预测新数据。
# load the model from disk
load_model = joblib.load(filename)
result = load_model.score(X_test, Y_test)
print(result)
用户手册地址
下面我们从几个方面来解读一下用户手册[7]。
时间和内存限制
auto-sklearn的一个关键功能是限制允许scikit-learn算法使用的资源(内存和时间)。特别是对于大型数据集(算法可能需要花费几个小时并进行机器交换),重要的是要在一段时间后停止评估,以便在合理的时间内取得进展。因此,设置资源限制是优化时间和可以测试的模型数量之间的权衡。
尽管auto-sklearn减轻了手动超参数调整的速度,但用户仍然必须设置内存和时间限制。对于大多数数据集而言,大多数现代计算机上的3GB或6GB内存限制已足够。对于时间限制,很难给出明确的指导原则。如果可能的话,一个很好的默认值是总时限为一天,单次运行时限为30分钟。
可以在auto-sklearn/issues/142[8]中找到更多准则。
限制搜索空间
除了使用所有可用的估计器外,还可以限制 auto-sklearn 的搜索空间。下面示例展示了如何排除所有预处理方法并将配置空间限制为仅使用随机森林。
import autosklearn.classification
automl = autosklearn.classification.AutoSklearnClassifier(
include_estimators=["random_forest",],
exclude_estimators=None,
include_preprocessors=["no_preprocessing", ],
exclude_preprocessors=None)
automl.fit(X_train, y_train)
predictions = automl.predict(X_test)
注意: 用于标识估计器和预处理器的字符串是不带 .py 的文件名。
关闭预处理
auto-sklearn 中的预处理分为数据预处理和特征预处理。数据预处理包括分类特征的独热编码,缺失值插补以及特征或样本的归一化。这些步骤目前无法关闭。特征预处理是单个特征变换器,可实现例如特征选择或将特征变换到不同空间(如PCA)。如上例所示,特征预处理可以通过设置include_preprocessors=["no_preprocessing"] 将其关闭。
重采样策略
可以在 auto-sklearn/examples/ 中找到使用维持数据集和交叉验证的示例。
结果检查
Auto-sklearn 允许用户检查训练的结果和产看相关的统计信息。以下示例展示了如何打印不同的统计信息以进行相应检查。
import autosklearn.classification
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
automl.cv_results_
automl.sprint_statistics()
automl.show_models()
cv_results_返回一个字典,其中的键作为列标题,值作为列,可以将其导入到pandas的一个DataFrame类型数据中。sprint_statistics()可以打印出数据集名称、使用的度量以及通过运行auto-sklearn获得的最佳验证分数。此外,它还会打印成功和不成功算法的运行次数。通过调用 show_models(),可以打印最终集成模型产生的结果。
并行计算
auto-sklearn支持通过共享文件系统上的数据共享来并行执行。在这种模式下,SMAC算法通过在每次迭代后将其训练数据写入磁盘来共享其模型的训练数据。在每次迭代的开始,SMAC都会加载所有新发现的数据点。我们提供了一个实现scikit-learn的n_jobs功能的示例,以及一个有关如何手动启动多个auto-sklearn实例的示例。
在默认模式下,auto-sklearn已使用两个核心。第一个用于模型构建,第二个用于在每次新的机器学习模型完成训练后构建整体。序列示例显示了如何以一次仅使用一个内核的方式顺序运行这些任务。
此外,根据scikit-learn和numpy的安装,模型构建过程最多可以使用所有内核。这种行为是auto-sklearn所不希望的,并且很可能是由于从pypi安装了numpy作为二进制轮子(请参见此处)。执行export OPENBLAS_NUM_THREADS=1应该禁用这种行为,并使numpy一次仅使用一个内核。
Vanilla auto-sklearn
auto-sklearn 主要是基于 scikit-learn 的封装。因此,可以遵循 scikit-learn 中的持久化示例。
为了获得在资料 Efficient and Robust Automated Machine Learning 中使用的 vanilla auto-sklearn,设置ensemble_size = 1 和 initial_configurations_via_metalearning=0。
import autosklearn.classification
automl = autosklearn.classification.AutoSklearnClassifier(
ensemble_size=1, initial_configurations_via_metalearning=0)
集成的大小设为 1 将导致始终选择在验证集上的测试性能最佳的单一模型。将初始配置的元学习设置为 0,将使得 auto-sklearn 使用常规的 SMAC 算法来设置新的超参数配置。
参考资料
efficient and robust automated machine learning: https://papers.nips.cc/paper/5872-efficient-and-robust-automated-machine-learning
[2]auto-sklearn官方文档: https://automl.github.io/auto-sklearn/master/installation.html
[3]AutoSklearnClassifier: https://automl.github.io/auto-sklearn/master/api.html#classification
[4]AutoSklearnRegressor: https://automl.github.io/auto-sklearn/master/api.html#regression
[5]声纳数据集: https://gitee.com/yunduodatastudio/picture/raw/master/data/auto-sklearn.png
[6]汽车保险数据集: https://gitee.com/yunduodatastudio/picture/raw/master/data/auto-sklearn.png
[7]用户手册: https://automl.github.io/auto-sklearn/master/manual.html#manual
[8]auto-sklearn/issues/142: https://github.com/automl/auto-sklearn/issues/142
[9]https://cloud.tencent.com/developer/article/1630703
[10]https://machinelearningmastery.com/auto-sklearn-for-automated-machine-learning-in-python/
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: