
【机器学习基础】一文"看透"多任务学习
大家在做模型的时候,往往关注一个特定指标的优化,如做点击率模型,就优化AUC,做二分类模型,就优化f-score。然而,这样忽视了模型通过学习其他任务所能带来的信息增益和效果上的提升。通过在不同的任务中共享向量表达,我们能够让模型在各个任务上的泛化效果大大提升。这个方法就是我们今天要谈论的主题-多任务学习(MTL)。
所以如何判定是不是多任务学习呢?不需要看模型结构全貌,只需要看下loss函数即可,如果loss包含很多项,每一项都是不同目标,这个模型就是在多任务学习了。有时,虽然你的模型仅仅是优化一个目标,同样可以通过多任务学习,提升该模型的泛化效果。比如点击率模型,我们可以通过添加转化样本,构建辅助loss(预估转化率),从而提升点击率模型的泛化性。
为什么多任务学习会有效?举个例子,一个模型已经学会了区分颜色,如果直接把这个模型用于蔬菜和肉类的分类任务呢?模型很容易学到绿色的是蔬菜,其他更大概率是肉。正则化算不算多任务?正则化的优化的loss不仅有本身的回归/分类产生的loss,还有l1/l2产生的loss,因为我们认为"正确且不过拟合"的模型的参数应该稀疏,且不易过大,要把这种假设注入到模型中去学习,就产生了正则化项,本质也是一个额外的任务。
MTL两个方法
第一种是hard parameter sharing,如下图所示:
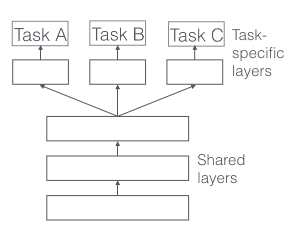
比较简单,前几层dnn为各个任务共享,后面分离出不同任务的layers。这种方法有效降低了过拟合的风险: 模型同时学习的任务数越多,模型在共享层就要学到一个通用的嵌入式表达使得每个任务都表现较好,从而降低过拟合的风险。
第二种是soft parameter sharing,如下图所示:
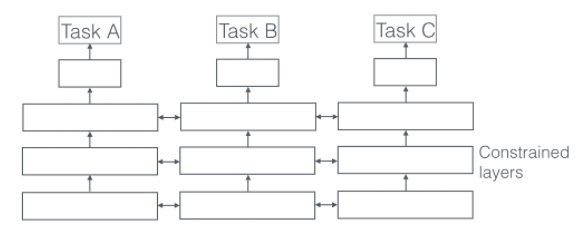
在这种方法下,每个任务都有自己的模型,有自己的参数,但是对不同模型之间的参数是有限制的,不同模型的参数之间必须相似,由此会有个distance描述参数之间的相似度,会作为额外的任务加入到模型的学习中,类似正则化项。
多任务学习能提效,主要是由于以下几点原因:
隐式数据增强:每个任务都有自己的样本,使用多任务学习的话,模型的样本量会提升很多。而且数据都会有噪声,如果单学A任务,模型会把A数据的噪声也学进去,如果是多任务学习,模型因为要求B任务也要学习好,就会忽视掉A任务的噪声,同理,模型学A的时候也会忽视掉B任务的噪声,因此多任务学习可以学到一个更精确的嵌入表达。
注意力聚焦:如果任务的数据噪声非常多,数据很少且非常高维,模型对相关特征和非相关特征就无法区分。多任务学习可以帮助模型聚焦到有用的特征上,因为不同任务都会反应特征与任务的相关性。
特征信息窃取:有些特征在任务B中容易学习,在任务A中较难学习,主要原因是任务A与这些特征的交互更为复杂,且对于任务A来说其他特征可能会阻碍部分特征的学习,因此通过多任务学习,模型可以高效的学习每一个重要的特征。
表达偏差:MTL使模型学到所有任务都偏好的向量表示。这也将有助于该模型推广到未来的新任务,因为假设空间对于足够多的训练任务表现良好,对于学习新任务也表现良好。
正则化:对于一个任务而言,其他任务的学习都会对该任务有正则化效果。
多任务深度学习模型
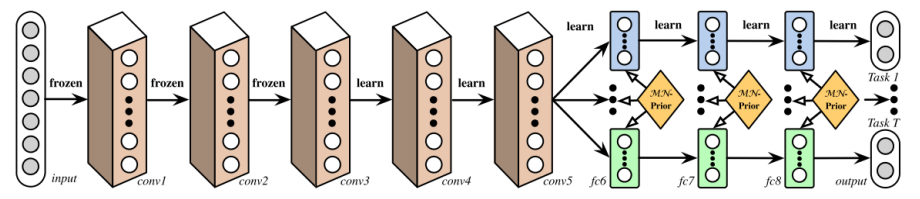
Deep Relationship Networks:从下图,我们可以看到卷积层前几层是预训练好的,后几层是共享参数的,用于学习不同任务之间的联系,最后独立的dnn模块用于学习各个任务。
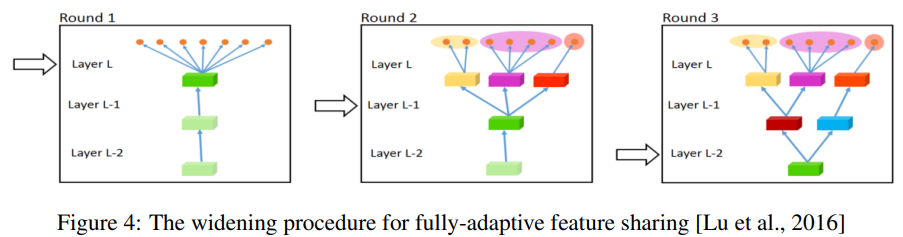
Fully-Adaptive Feature Sharing:从另一个极端开始,下图是一种自底向上的方法,从一个简单的网络开始,并在训练过程中利用相似任务的分组准则贪婪地动态扩展网络。贪婪方法可能无法发现一个全局最优的模型,而且只将每个分支分配给一个任务使得模型无法学习任务之间复杂的交互。
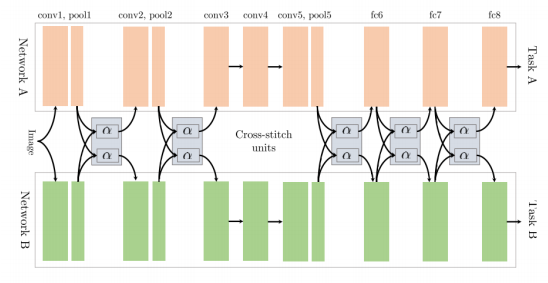
cross-stitch Networks: 如上文中所谈到的soft parameter sharing,该模型是两个完全分离的模型结构,该结构用了cross-stitch单元去让分离的模型学到不同任务之间的关系,如下图所示,通过在pooling层和全连接层后分别增加cross-stitch对前面学到的特征表达进行线性融合,再输出到后面的卷积/全连接模块。
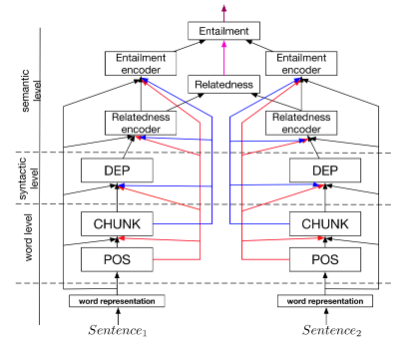
A Joint Many-Task Model:如下图所示,预定义的层级结构由各个NLP任务组成,低层级的结构通过词级别的任务学习,如此行分析,组块标注等。中间层级的结构通过句法分析级别的任务学习,如句法依存。高层级的结构通过语义级别的任务学习。
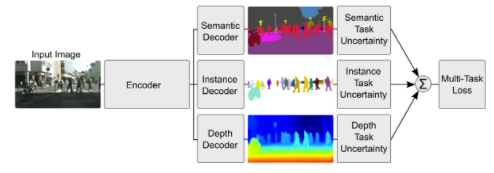
weighting losses with uncertainty:考虑到不同任务之间相关度的不确定性,基于高斯似然最大化的多任务损失函数,调整每个任务在成本函数中的相对权重。结构如下图所示,对像素深度回归、语义和实例分割。
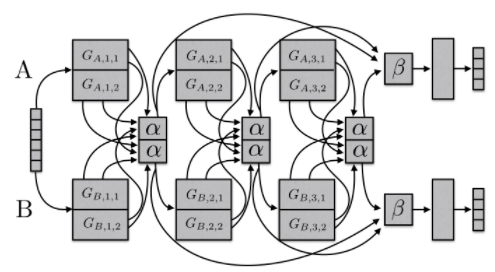
sluice networks: 下图模型概括了基于深度学习的MTL方法,如硬参数共享和cross-stitch网络、块稀疏正则化方法,以及最近创建任务层次结构的NLP方法。该模型能够学习到哪些层和子空间应该被共享,以及网络在哪些层学习了输入序列的最佳表示。
ESSM: 在电商场景下,转化是指从点击到购买。在CVR预估时候,我们往往会遇到两个问题:样本偏差和数据系数问题。样本偏差是指训练和测试集样本不同,拿电商举例,模型用点击的数据来训练,而预估的却是整个样本空间。数据稀疏问题就更严重了,本身点击样本就很少,转化就更少了,所以可以借鉴多任务学习的思路,引入辅助学习任务,拟合pCTR和pCTCVR(pCTCVR = pCTR * pCVR),如下图所示:
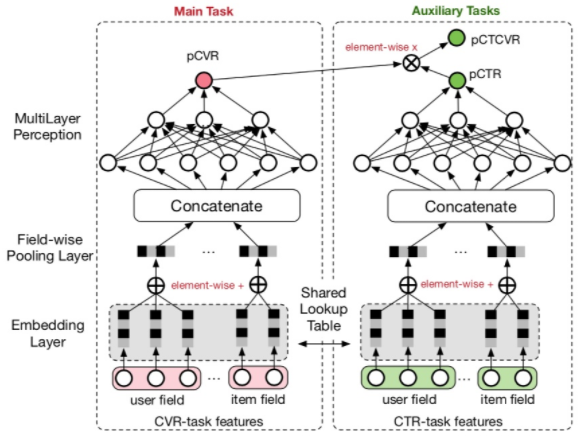
对于pCTR来说,可将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本
对于pCTCVR来说,可将同时有点击行为和购买行为的曝光事件作为正样本,其他作为负样本
对于pCVR来说,只有曝光没有点击的样本中的梯度也能回传到main task的网络中
另外这两个子网络的embedding层是共享的,由于CTR任务的训练样本量要远超过CVR任务的训练样本量,从而能够缓解训练数据稀疏性问题。
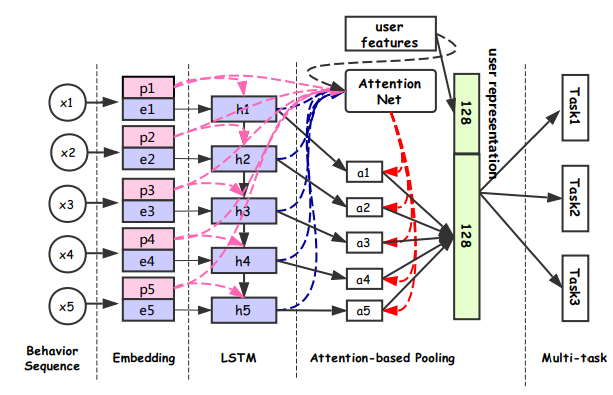
DUPN:模型分为行为序列层、Embedding层、LSTM层、Attention层、下游多任务层(CTR、LTR、时尚达人关注预估、用户购买力度量)。如下图所示

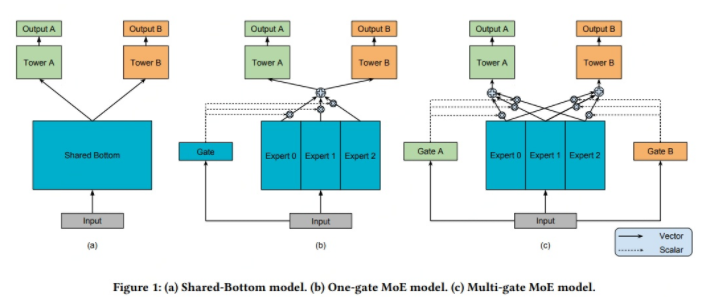
MMOE: 如下图所示,模型(a)最常见,共享了底层网络,上面分别接不同任务的全连接层。模型(b)认为不同的专家可以从相同的输入中提取出不同的特征,由一个Gate(类似) attention结构,把专家提取出的特征筛选出各个task最相关的特征,最后分别接不同任务的全连接层。MMOE的思想就是对于不同任务,需要不同专家提取出的信息,因此每个任务都需要一个独立的gate。
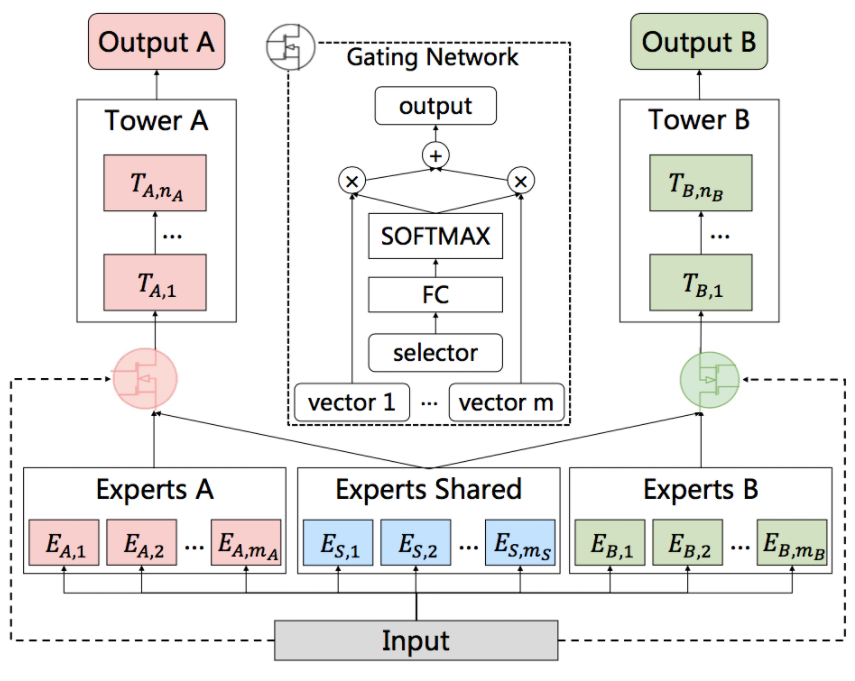
PLE:即使通过MMoE这种方式减轻负迁移现象,跷跷板现象仍然是广泛存在的(跷跷板现象指多任务之间相关性不强时,信息共享就会影响模型效果,会出现一个任务泛化性变强,另一个变弱的现象)。PLE的本质是MMOE的改进版本,有些expert是任务专属,有些expert是共享的,如下图CGC架构,对于任务A而言,通过A的gate把A的expert和共享的expert进行融合,去学习A。
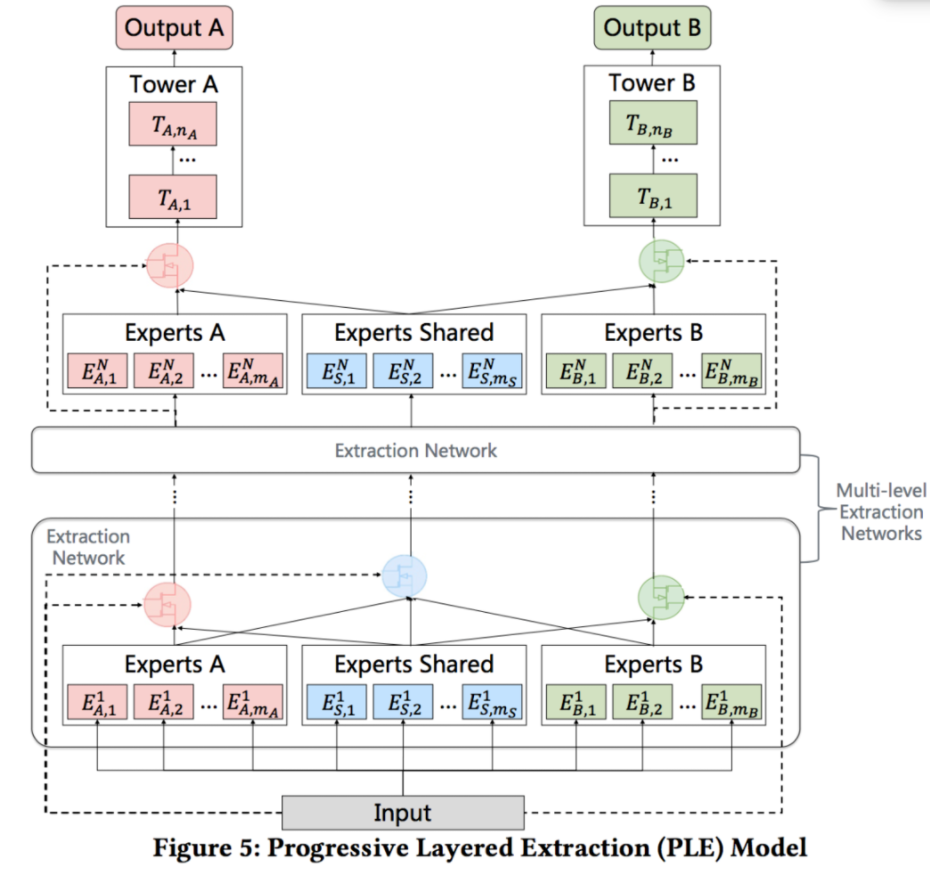
最终PLE结构如下,融合了定制的expert和MMOE,堆叠多层CGC架构,如下所示:
参考文献
1. An overview of multi-task learning in deep neural networks. Retireved from https://arxiv.org/pdf/1706.05098.pdf
2. Long, M., & Wang, J. (2015). Learning Multiple Tasks with Deep Relationship Networks. arXiv Preprint arXiv:1506.02117. Retrieved from http://arxiv.org/abs/1506.02117
3. Lu, Y., Kumar, A., Zhai, S., Cheng, Y., Javidi, T., & Feris, R. (2016). Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification. Retrieved from http://arxiv.org/abs/1611.05377
4. Misra, I., Shrivastava, A., Gupta, A., & Hebert, M. (2016). Cross-stitch Networks for Multi-task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.433
5. Hashimoto, K., Xiong, C., Tsuruoka, Y., & Socher, R. (2016). A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks. arXiv Preprint arXiv:1611.01587. Retrieved from http://arxiv.org/abs/1611.01587
6. Yang, Y., & Hospedales, T. (2017). Deep Multi-task Representation Learning: A Tensor Factorisation Approach. In ICLR 2017. https://doi.org/10.1002/joe.20070
7. Ruder, S., Bingel, J., Augenstein, I., & Søgaard, A. (2017). Sluice networks: Learning what to share between loosely related tasks. Retrieved from http://arxiv.org/abs/1705.08142
8. Entire Space Multi-Task Model: An Effective Approach for
Estimating Post-Click Conversion Rate. Retrieved from: https://arxiv.org/pdf/1804.07931.pdf
9. Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks. Retrieved from: https://arxiv.org/pdf/1805.10727.pdf
往期精彩回顾
本站qq群851320808,加入微信群请扫码: