
【学术相关】作者解读ICML接收论文:如何使用不止一个数据集训练神经网络模型?
导读:在实际的深度学习项目中,难免遇到多个相似数据集,这时一次仅用单个数据集训练模型,难免造成局限。是否存在利用多个数据集训练的可能性?本文带来解读。
01 介绍
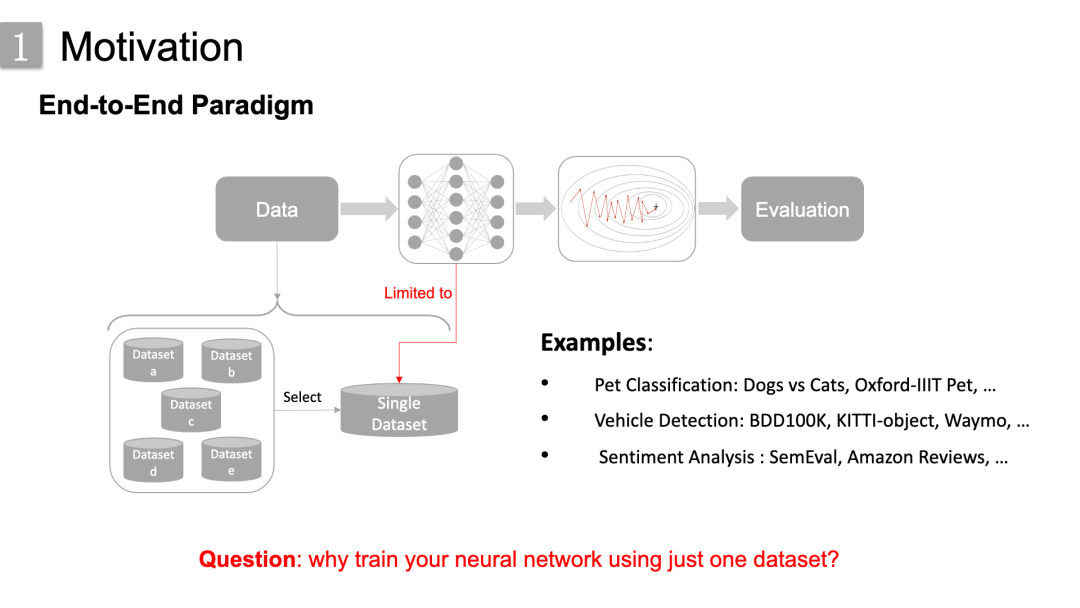
迄今为止,在深度学习领域,最流行的范式或者大家最常用的范式是端到端学习范式。
我们可以把该范式简单概括为四个步骤:准备数据,喂入网络数据,神经网络优化,最后评估模型。这个范式确实也在各个领域取得了巨大成功。
然而,当我们在做一些实际的工程应用时,一项任务可能有多个相似数据集,比如在宠物分类的Dogs vs Cats, Oxford-IIIT Pet数据集,交通车辆检测的BDD100k,KITTI-object等数据集。通常的做法是一次仅选择其中的一个进行各种模型训练,这不仅浪费了其他的数据集,也同时给模型带来局限。
因此,我们可能会问这样一个问题:为什么只使用一个数据集来训练神经网络模型?
这是我在Graviti作为算法实习生,与leader以及导师一起完成的一项研究工作,已经被ICML2021接受了,非常感谢Datawhale给我向大家分享论文。今天的分享简单分为 介绍(包括movivation,related work等等),方法,实验验证,最后的结论 四个部分。
回到正题,针对上面的问题,那肯定要利用起多个数据集的。
有些数据集可以轻松融合在一起,因为他们有重叠的标签,就像下面这两个traffic相关的数据集有共同的标签类 person和bike,
但有些不能,我们认为其中一个主要的瓶颈之一是标签差异,标签集存在不同的语义层次或粒度。
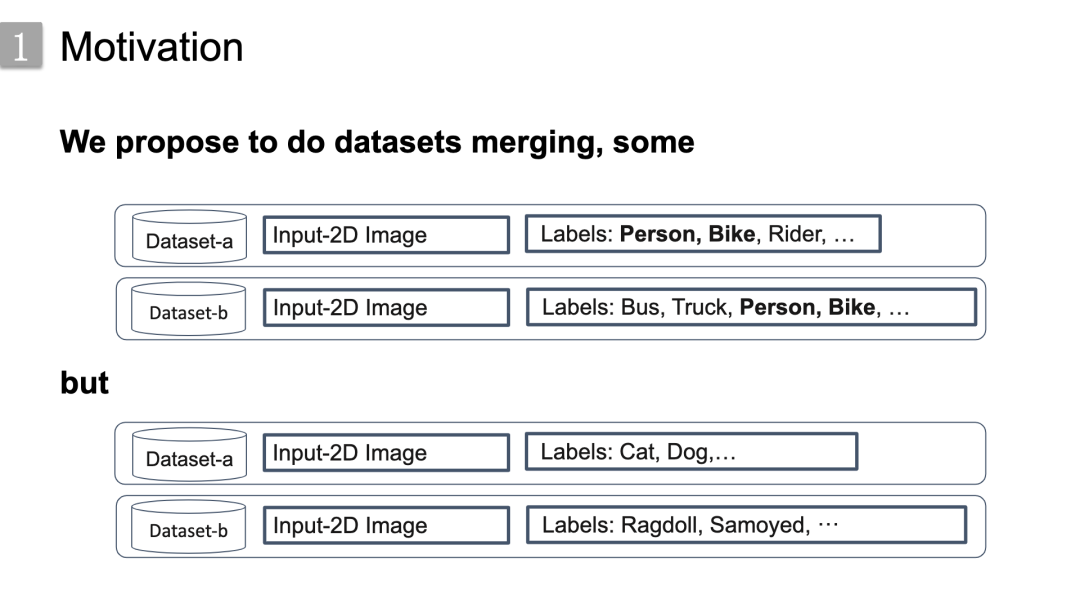 就像这里底部宠物数据集的例子,数据集a标签是猫狗等,数据集b标签是一些猫狗的品种如布偶猫,萨摩耶等,因为两个数据集的标签粒度存在差异,导致其无法直接融合。
就像这里底部宠物数据集的例子,数据集a标签是猫狗等,数据集b标签是一些猫狗的品种如布偶猫,萨摩耶等,因为两个数据集的标签粒度存在差异,导致其无法直接融合。
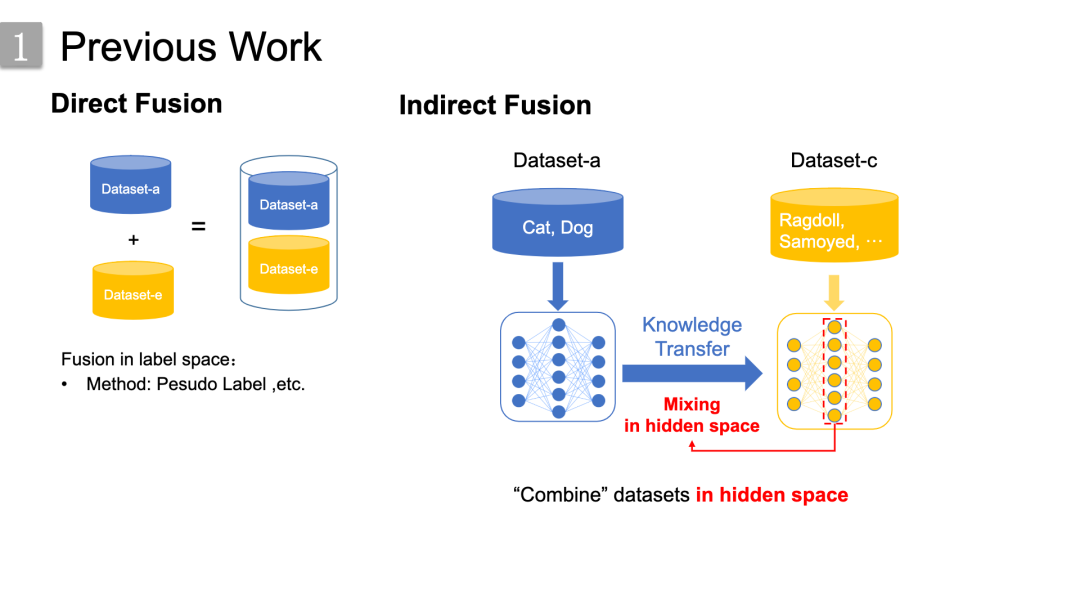 事实上,确实有些前人的工作涉及该方面,
事实上,确实有些前人的工作涉及该方面,
我将这些工作主要分为了两类:1.是左边的直接融合,直接在标签空间进行,这要求标签的一致性,这通常可以通过伪标签的方式进行;2.是右边的间接融合,它可以抽象为通过共享的隐藏向量空间进行数据集融合,相应的算法框架涉及迁移学习、领域自适应等。
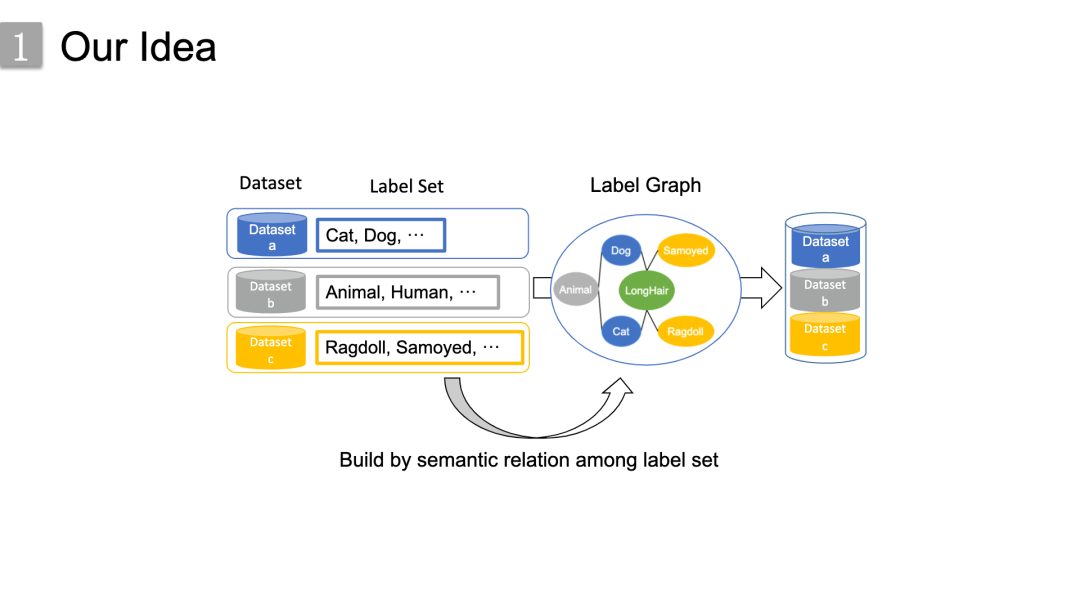 而我们的思路是从数据集的语义信息角度出发,
而我们的思路是从数据集的语义信息角度出发,
由于具有相似目的的数据集其标签在领域知识是具有的语义关联,所以我们就通过构造一个统一的知识驱动的标签图来在标签空间中直接进行数据集融合。
这里举了个具体的例子,左边的部分是动物领域的三个相似的数据集及其标签集,由于这些标签集之间的语义层次和粒度不同,它们无法轻松融合。然而,在通过标签集之间的语义关系建立标签图之后,这些数据集成功地连接起来,三个数据集就被组合成一个单一的数据集。
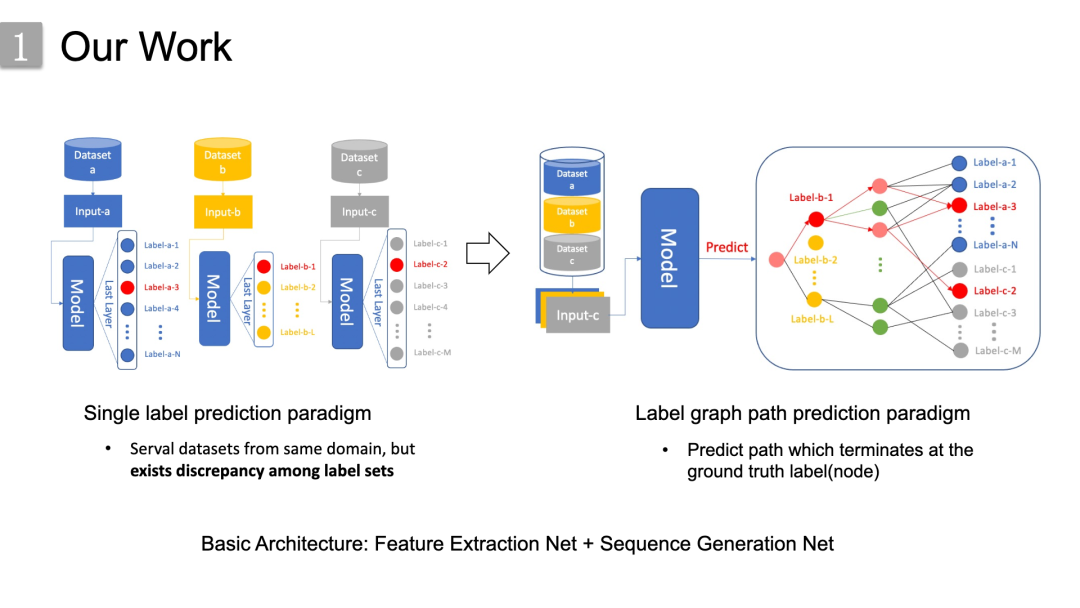 更具体地来说,左边是传统的未融合数据集的示例,几个相似的数据集,但标签集之间存在差异,每个数据集对应一个单标签预测模型的训练过程。右边我们提出的方法,我们将这些数据集连接在一起,驱动模型预测 标签图上以目标节点为终点的整个轨迹,而不是单一的标签预测。
更具体地来说,左边是传统的未融合数据集的示例,几个相似的数据集,但标签集之间存在差异,每个数据集对应一个单标签预测模型的训练过程。右边我们提出的方法,我们将这些数据集连接在一起,驱动模型预测 标签图上以目标节点为终点的整个轨迹,而不是单一的标签预测。
我们模型的基本架构就是特征提取网络接上序列生成网络,即Encoder-Decoder的结构。
介绍部分就到这里,接下来是方法部分。
02 方法
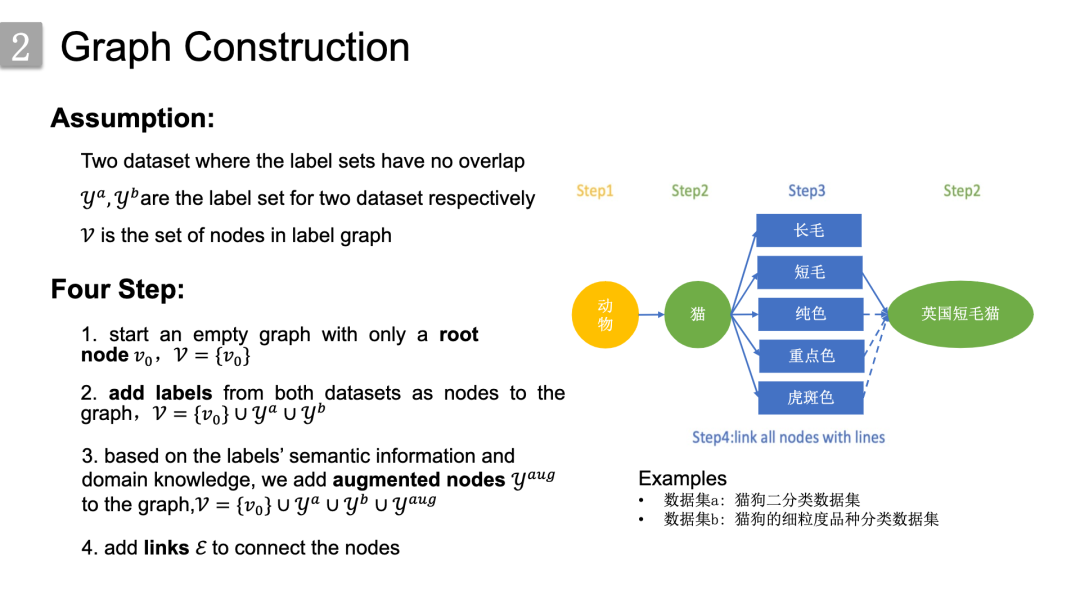 首先是图谱构建的流程,这里其实是展示了一个抽象化的流程。这里假设对两个数据集的标签来构建图谱,
首先是图谱构建的流程,这里其实是展示了一个抽象化的流程。这里假设对两个数据集的标签来构建图谱,
这两个数据集分别假设为:
猫狗二分类数据集 猫狗的细粒度品种分类数据集
构建步骤抽象为以下四个步骤,
1.首先是添加根节点,就是黄色的动物节点;2. 所有数据集的标签节点,就是绿色的节点;3. 以及代表属性特征的扩展节点,即蓝色的节点;4. 最后连接边。
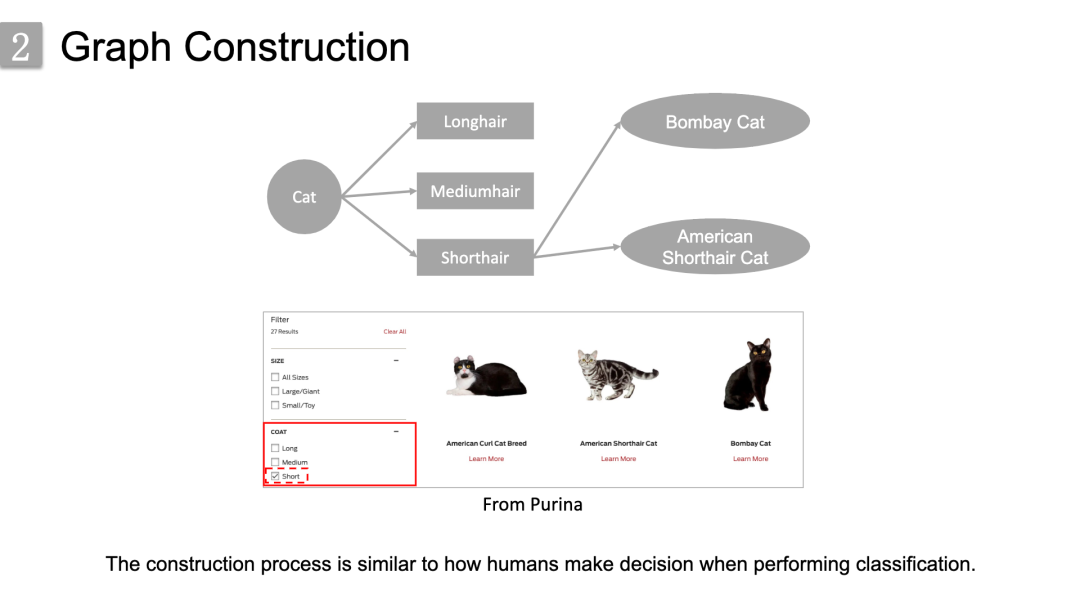 但实际上这个图的构建过程是更为具体和直接的,因为这个图其实不是我们构造的,而是通过 “窃取”来的。因为这个标签图本质上是从相关的领域几十年来积累的领域知识中获得的。
但实际上这个图的构建过程是更为具体和直接的,因为这个图其实不是我们构造的,而是通过 “窃取”来的。因为这个标签图本质上是从相关的领域几十年来积累的领域知识中获得的。
以猫的品种分类为例:
首先,我们将cat设置为根节点,接着我们从Purina这样的领域网站上发现了三种类型的coat特性。因此,我们添加它们作为增强节点来表示猫的一方面外观特征;其次,我们check了coat field中的对应框“Short”,发现了许多短毛品种,并将它们放置在增强节点shorthair下。通过类似的方式,就可以构建出一张很大的或者说完整的标签图。
同时在刚刚的这个过程中,我们很容易发现,构造过程类似于人类在执行分类时的决策方式。当我们人看到一种动物时,我们首先根据它的全局特征来判断它的大致类别,然后仔细观察它的局部特征来确定它细分的品种。
也就是说在我们的方法中,模型在执行推理时,标签图其实提供了一个“决策过程”。
此外,我们认为这种方法是象征主义和连接主义的结合。也就是说,我们将几十年积累起来的领域知识归纳为一个深度神经网络模型。
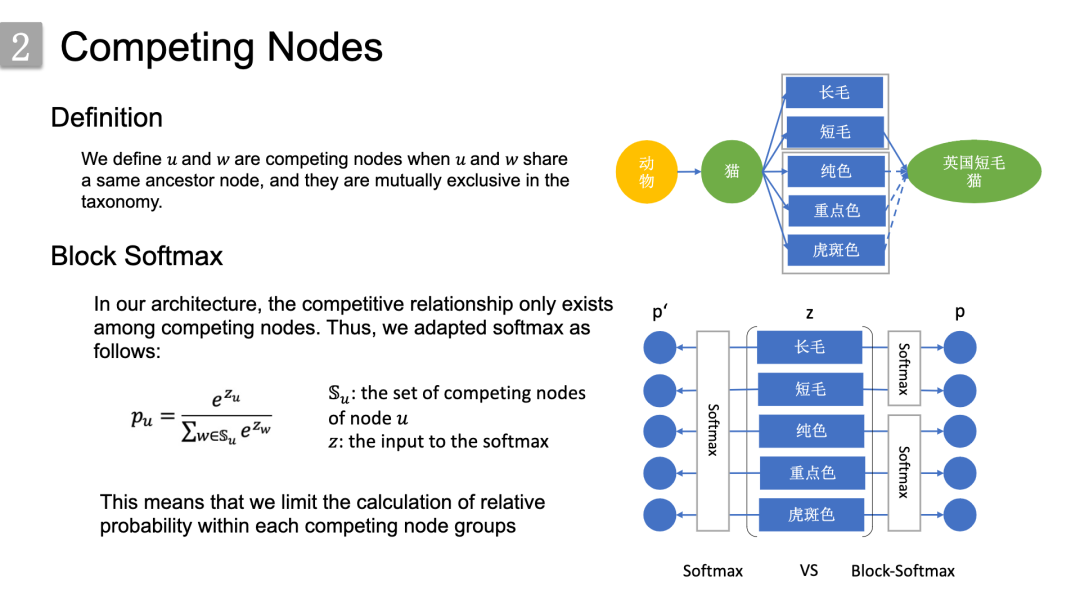 为了更好地捕捉下方标签图上同一层级节点间的关系,我们定义了竞争节点的概念。
为了更好地捕捉下方标签图上同一层级节点间的关系,我们定义了竞争节点的概念。
定义u和w是竞争节点,当且仅当u和w有着共同的祖先节点,并且它们在分类法上是互斥的。
针对竞争节点,我们提出了block-softmax;因为对于一般softmax,所有类别都在相互竞争。但是,在我们的体系结构中,竞争关系仅存在于竞争节点之间。因此做了一个block的限制,从而将相对概率的计算限制到了每个竞争节点组内。右图就是一个对比示意图:
说完节点来到路径,我们也定义了确定性和不确定性路径来分别处理 类别具有确定性以及不确定特征 的情况。首先是确定性路径,它的定义如这里所示,比较抽象,我们就直接来看一个具体的例子:
给定标签节点v和经过该节点的路径P(v),如果不存其他路径P′(v)满足条件:∃ u∈P(v),w∈P^′(v), u,w形成竞争节点并且u ≠w 则P(v)是确定性路径。
右图中的一个例子就是动物-》猫-〉短毛->英国短毛猫,
之所以说这条路径是确定的是因为,所有的英国短毛猫都是短毛的。
首先是确定性路径的训练,我们采用了Teacher forcing的训练策略,
该流程如右图所示,对于确定性ground truth路径P,我们将其视为一个序列,让循环单元自回归地预测序列上的每个节点,
然后我们就能得到如下的损失函数,(本质上就是最大化整条正确路径的概率),从而反向传播并优化。
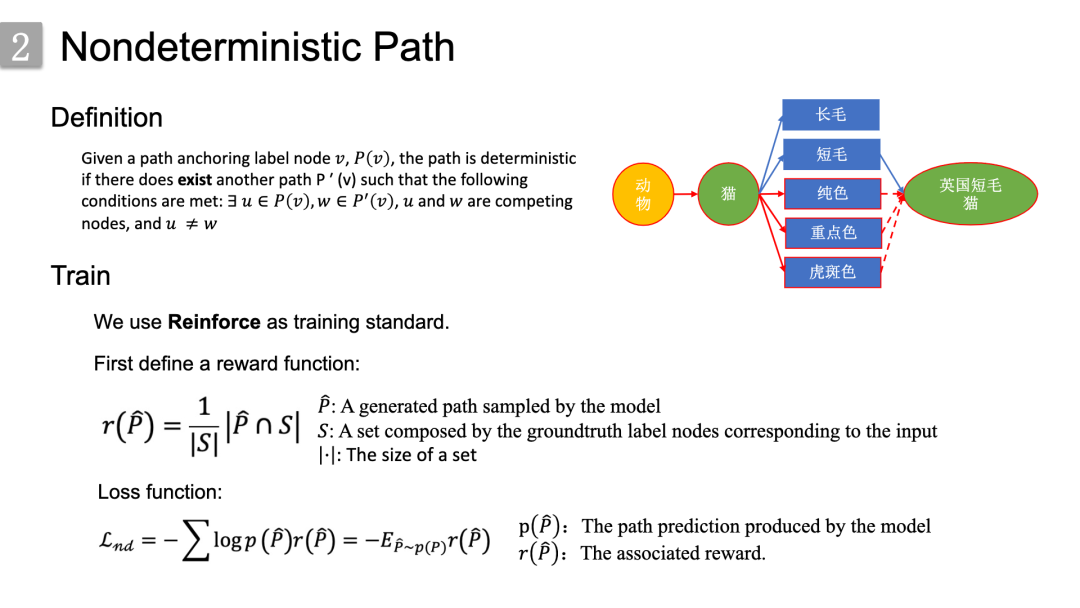 然后是关于非确定性路径。给定路径锚定(anchoring)标签节点,,如果存一条其他路径满足条件:,,,形成竞争节点并且 ,则是非确定性路径。
然后是关于非确定性路径。给定路径锚定(anchoring)标签节点,,如果存一条其他路径满足条件:,,,形成竞争节点并且 ,则是非确定性路径。
右图中有三条不确定性路径,被标记为红色。因为英国短发猫的毛色模式可以是纯色、重点色、虎斑色中的任意一种。因此,经过这三个节点到英国短毛节点的路径都是不确定的。
由于其路径中的不确定节点导致teacher forcing策略无法正常使用,所以我们采用了Reinforce算法。首先我们定义了一个激励函数,即“模型采样的生成路径”和“ground truth标签节点集”之间交集的归一化大小。进而定义出了损失函数,其实本质上就是最大化采样生成路径的期望奖励,能够通过最后一个式子估计出不确定性路径的梯度,具体的推导请参考reinforce的论文。
然后我们最终的训练策略的话其实就是在一个batch中依次进行确定性和非确定性路径的训练,具体详细的训练流程就不在这里说了,有兴趣的可以看一下我们论文中的伪代码。
03 实验
 实验部分我们分别在单标签图像和文本分类任务上进行的。
实验部分我们分别在单标签图像和文本分类任务上进行的。
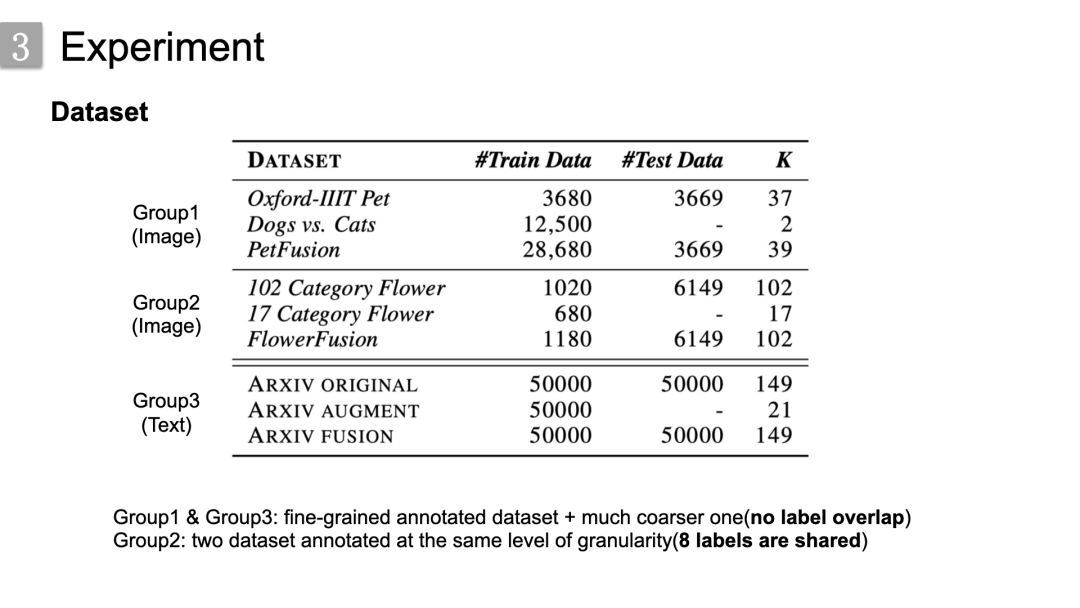
首先,关于数据集设置,分为三组:
第一组是关于宠物分类,第二组是关于花分类,
第三组是对arxiv文章进行学科分类,arxiv学科的标签其实是有层级的,比如第一级cs,第二级 ml,arxiv augment就只保留了其最高层级的标签。
前两组的标签图都是我们通过现有的领域知识构建的,arxiv那一组标签其实是有层级的,比如第一级cs,第二级 ml,就直接将层级关系展开为标签图。
组1和组3对应于细粒度和粗粒度数据集的融合,并且数据集之间没有标签重叠,
组2对应于在相同粒度级别上标注的两个数据集的融合,其中重叠标签数量为8
出于评估目的,我们的测试都是在难度更大的细粒度数据集上进行的:
 然后,是关于模型的设置的。
然后,是关于模型的设置的。
首先是baseline,
在图像分类中,有三种。1.传统的单标签预测模型
2.基于伪标签的融合数据集,即为粗数据集中的样本生成细粒度伪标签,并将这些样本合并到细粒度数据集中。3.它是一个多标签分类设置,采用了之前工作中的一个关键实验。而在文本分类任务中,基线是传统的单标签预测模型。
然后是我们的模型。其中对于Encoder,图像分类任务中使用EfficientNet-b4而文本分类任务使用Bert或LSTM作为特征提取器,对于Decoder使用GRU,
并且在图像分类任务中融合了注意力模块来帮助GRU单元在不同的step关注到图像中不同位置的信息。
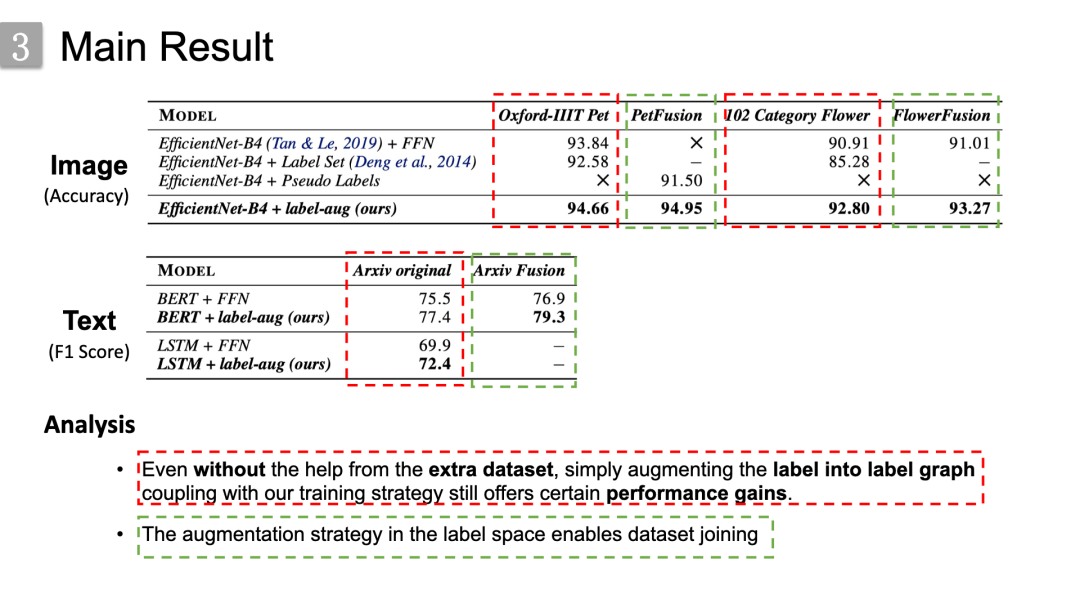 然后是实验的主要结果。从表中可以看出两点:
然后是实验的主要结果。从表中可以看出两点:
1.如红色虚线框中对比数据所示,即使没有额外数据集的帮助,简单地将标签扩展为标签关系图,再加上我们的训练策略,表现仍然会有所提升。因为将标签扩展为标签关系图,其实本质上就是一种数据增强的方式,只是与传统的数据增强方法集中于数据本身上不同,本文增强了标签之间的关系,或者另一种角度来看本文为每个标签的样本又引入了额外的标签,即额外的监督信息。
2.如绿色虚线框中的对比数据所示,使用本文所提出的方法要优于直接融合,以及基于伪标签融合的方法,同时也要优于传统的单标签预测模型,说明了我们方法在标签空间进行数据集融合的可行性。
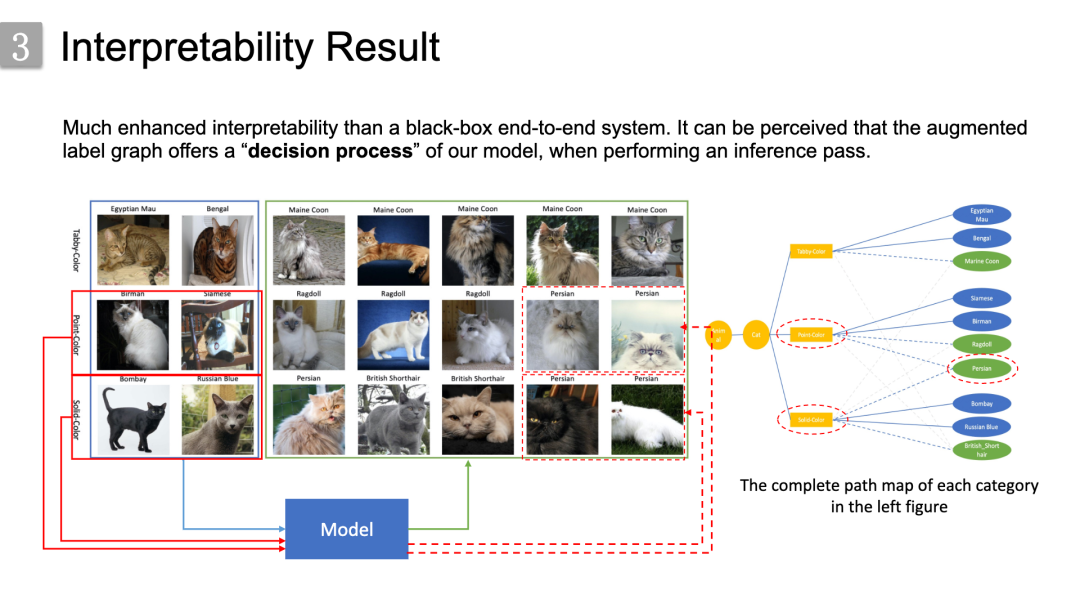
更重要的是,我们的方法具有增强的可解释性。为了说明这一点,我们以波斯猫为例,波斯猫用红色虚线椭圆标记,波斯猫的毛色模式是重点色或纯色,这是不确定的。该模型通过确定性的重点色和纯色的猫类样本来学习这两种颜色模式的特征,应用在不确定性路径样本的推理上,从而区分波斯猫中不同毛色模式的样本。这就像之前说的,我们的标签图其实就是为我们的模型在推理时提供了决策过程的过程,从而使其更具有可解释性。实验部分到此结束。
04 结论
在这项工作中,我们研究了数据集连接的问题,更具体地说是在标签系统不一致时的标签集连接问题。我们提出了一个新的框架来解决这个问题,包括标签空间扩充、递归神经网络、序列训练和策略梯度。经过训练的模型在性能和可解释性方面都显示出良好的结果。
当然这项工作只是一个多数据集连接初步的探索,
其中还有很多问题可以研究解决,包括以下:
图谱质量的如何衡量, 如何构建更加鲁棒的方法来适应的有噪声标签关系图, 融合后数据集产生的分布偏移问题该如何解决,
同时直接还有很多可扩展的方向,包括:
伪标签方法相结合 在其他任务如目标检测、分割上进行探索
以上的话就是对我们这项工作的整体介绍,关于该项工作的更多细节可以去arxiv上看看我们的paper。
往期精彩回顾 本站qq群554839127,加入微信群请扫码: