
如何正确使用COCO数据集
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

COCO数据集,意为“Common Objects In Context”,是一组具有挑战性的、高质量的计算机视觉数据集,是最先进的神经网络,此名称还用于命名这些数据集使用的格式。
COCO 是一个大规模的对象检测、分割和字幕数据集。COCO有几个特点:
- 对象分割
- 在上下文中识别
- 超像素素材分割
- 330K 图像(> 200K 标记)
- 150 万个对象实例
- 80 个对象类别
该数据集的格式可以被高级神经网络库自动理解,例如Facebook的Detectron2,甚至还有专门为处理 COCO 格式的数据集而构建的工具,例如COCO- annotator和COCOapi。了解此数据集的表示方式将有助于使用和修改现有数据集以及创建自定义数据集。具体来说,我们对注释文件感兴趣,是因为完整的数据集由图像目录和注释文件组成,提供机器学习算法使用的元数据。
实际上有多个 COCO 数据集,每个数据集都是为特定的机器学习任务创建的,并带有附加数据。3个最受欢迎的任务是:
对象检测——模型应该获取对象的边界框,即返回对象类列表和它们周围矩形的坐标;物体(也称为“事物”)是离散的、独立的物体,通常带有零件,如人和汽车。
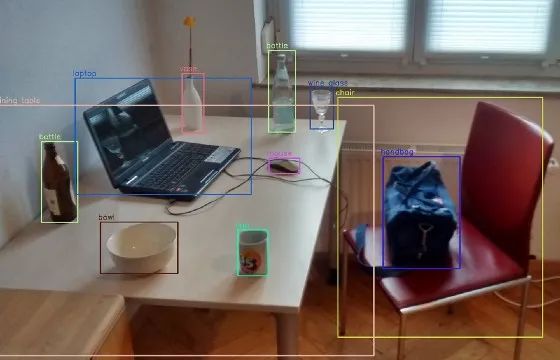
对象分割——模型不仅应该得到对象(实例/“事物”)的边界框,还应该得到分割掩码,即围绕对象的多边形坐标。

实例分割——模型应该做对象分割,但不是在单独的对象(“事物”)上,而是在背景连续模式上,比如草或天空。

在计算机视觉中,这些任务有着巨大的用途,例如用于自动驾驶车辆(检测人和其他车辆)、基于人工智能的安全性(人体检测和/或分割)和对象重新识别(对象分割或实例分割去除背景有助于检查对象身份)。
基本结构和常见元素:COCO 注释使用的文件格式是 JSON,它有字典(大括号内的键值对{…})作为顶部值,它还可以有列表(括号内的有序项目集合,[…])或嵌套在其中的字典。
基本结构如下:
{
"info": {…},
"licenses": […],
"images": […],
"categories": […],
"annotations": […]
}
让我们仔细看看基本结构中的每一个部分。
“info”部分:
该字典包含有关数据集的元数据,对于官方的 COCO 数据集,如下:
{
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
}
如我们所见,它仅包含基本信息,"url"值指向数据集官方网站(例如 UCI 存储库页面或在单独域中),这是机器学习数据集中常见的事情,指向他们的网站以获取更多信息,例如获取数据的方式和时间。
“licenses”部分:
以下是数据集中图像许可的链接,例如知识共享许可,具有以下结构:
[
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nc/2.0/",
"id": 2,
"name": "Attribution-NonCommercial License"
},
…
]
这里要注意的重要一点是"id"字段——"images"字典中的每个图像都应该指定其许可证的“id”。
在使用图像时,请确保没有违反其许可——可以在 URL 下找到全文。
如果我们决定创建自己的数据集,请为每个图像分配适当的许可——如果我们不确定,最好不要使用该图像。
“image”部分:
可以说是第二重要的,这本字典包含有关图像的元数据:
{
"license": 3,
"file_name": "000000391895.jpg",
"coco_url": "http://images.cocodataset.org/train2017/000000391895.jpg",
"height": 360,
"width": 640,
"date_captured": "2013–11–14 11:18:45",
"flickr_url": "http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg",
"id": 391895
}
接下来我们看一下这些字段:
"license":来自该"licenses" 部分的图像许可证的 ID
"file_name": 图像目录中的文件名
"coco_url", "flickr_url": 在线托管图像副本的 URL
"height", "width": 图像的大小,在像 C 这样的低级语言中非常方便,在这种语言中获取矩阵的大小是非常困难的
"date_captured": 拍照的时候
"id"领域是最重要的领域,这是用于"annotations"识别图像的编号,因此如果我们想识别给定图像文件的注释,则必须在"图像"中检查相应图像文档的“id”,然后在“注释”中交叉引用它。
在官方COCO数据集中"id"与"file_name"相同。需要注意的是,自定义 COCO数据集可能不一定是这种情况!这不是强制的规则,例如由私人照片制成的数据集可能具有与没有共同之处的原始照片名称"id"。
"categories"部分:
本部分对于对象检测和分割任务以及对于实例分割任务有点不同。
对象检测/对象分割:
[
{"supercategory": "person", "id": 1, "name": "person"},
{"supercategory": "vehicle", "id": 2, "name": "bicycle"},
{"supercategory": "vehicle", "id": 3, "name": "car"},
…
{"supercategory": "indoor", "id": 90, "name": "toothbrush"}
]
这些是可以在图像上检测到的对象类别("categories"在 COCO 中是类别的另一个名称,我们可以从监督机器学习中了解到)。
每个类别都有一个唯一的"id",它们应该在 [1,number of categories] 范围内。类别也分为“超类别”,我们可以在程序中使用它们,例如,当我们不关心是自行车、汽车还是卡车时,一般检测车辆。
实例分割:
[
{"supercategory": "textile", "id": 92, "name": "banner"},
{"supercategory": "textile", "id": 93, "name": "blanket"},
…
{"supercategory": "other", "id": 183, "name": "other"}
]
类别数从高开始以避免与对象分割冲突,因为有时这些任务可以一起执行。从 92 到 182 的 ID 是实际的背景素材,而 ID 183 代表所有其他没有单独类的背景纹理。
“annotations”部分:
这是数据集最重要的部分,其中包含对特定 COCO 数据集的每个任务至关重要的信息。
{
"segmentation":
[[
239.97,
260.24,
222.04,
…
]],
"area": 2765.1486500000005,
"iscrowd": 0,
"image_id": 558840,
"bbox":
[
199.84,
200.46,
77.71,
70.88
],
"category_id": 58,
"id": 156
}
"segmentation":分割掩码像素列表;这是一个扁平的对列表,因此我们应该采用第一个和第二个值(图片中的 x 和 y),然后是第三个和第四个值,以获取坐标;需要注意的是,这些不是图像索引,因为它们是浮点数——它们是由 COCO-annotator 等工具从原始像素坐标创建和压缩的
"area":分割掩码内的像素数
"iscrowd":注释是针对单个对象(值为 0),还是针对彼此靠近的多个对象(值为 1);对于实例分割,此字段始终为 0 并被忽略
"image_id": 'images' 字典中的 'id' 字段;警告:这个值应该用于将图像与其他字典交叉引用,而不是"id"字段!
"bbox":边界框,即对象周围矩形的坐标(左上x,左上y,宽,高);从图像中提取单个对象非常有用,因为在像 Python 这样的许多语言中,它可以通过访问图像数组来完成,例如cropped_object = image[bbox[0]:bbox[0] + bbox[2], bbox[1]:bbox[1] + bbox[3]]
"category_id":对象的类,对应"类别"中的"id"字段
"id": 注释的唯一标识符;警告:这只是注释ID,这并不指向其他词典中的特定图像!
在处理人群图像 ( "iscrowd": 1) 时,该"segmentation"部分可能会有所不同:
{
"counts": [179,27,392,41,…,55,20],
"size": [426,640]
}
这是因为对于许多像素,明确列出所有像素创建分割掩码将占用大量空间,相反,COCO使用自定义的运行长度编码(RLE)压缩,这是非常有效的,因为分段掩码是二进制的,仅0和1的RLE可能会将大小减小很多倍。
我们探讨了用于最流行任务的COCO数据集格式:对象检测、对象分割和实例分割。COCO官方数据集质量高、规模大,适合初学者项目、生产环境和最新研究。我希望本文能够帮助小伙伴理解如何解释这种格式,并将其用于小伙伴的ML应用程序。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~