
如何使用多类型数据预训练多模态模型?
在训练过程中使用更多数据一直是深度学习提效的重要方法之一,在多模态场景也不例外。比如经典的CLIP模型,使用了大规模的网络图文匹配数据进行预训练,在图文匹配等任务上取得非常好的效果。
在此之后对CLIP多模态模型的优化中,一个很重要的分支是如何使用更多其他类型的数据(例如图像分类数据、看图说话数据等),特别是CVPR 2022、谷歌等近期发表的工作,都集中在这个方面。想使用多种类型的数据,核心是在数据或模型结构上实现多任务的统一。本文梳理了这个方向4篇近期最典型的工作,包括2篇CVPR 2022的文章和2篇谷歌的文章。其中涉及的方法包括:多模态模型结构上的统一、多模态数据格式上的统一、单模态数据引入、多类型数据分布差异问题优化4种类型。
论文题目:CoCa: Contrastive Captioners are Image-Text Foundation Models
下载地址:https://arxiv.org/pdf/2205.01917.pdf
CoCa将解决图像或多模态问题的模型概括成3种经典结构,分别是single-encoder model、dual-encoder model、encoder-decoder model。Single-encoder model指的是基础的图像分类模型,dual-encoder model指的是类似CLIP的双塔图文匹配模型,encoder-decoder model指的是用于看图说话任务的生成式模型。三种类型的模型结构对比如下图。
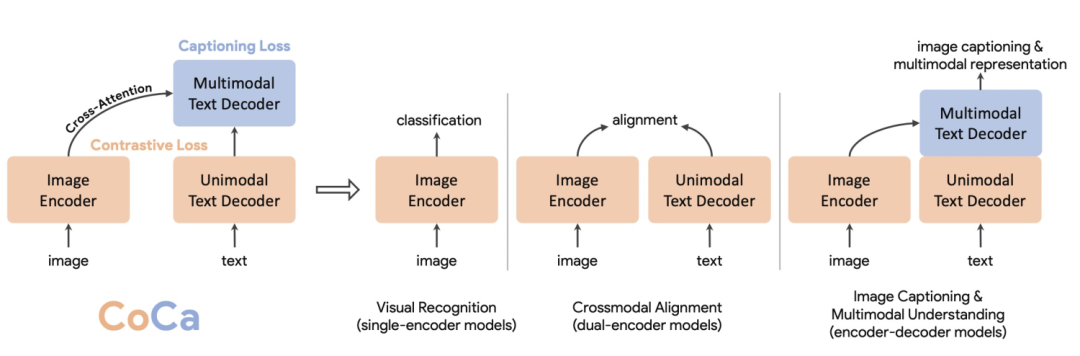
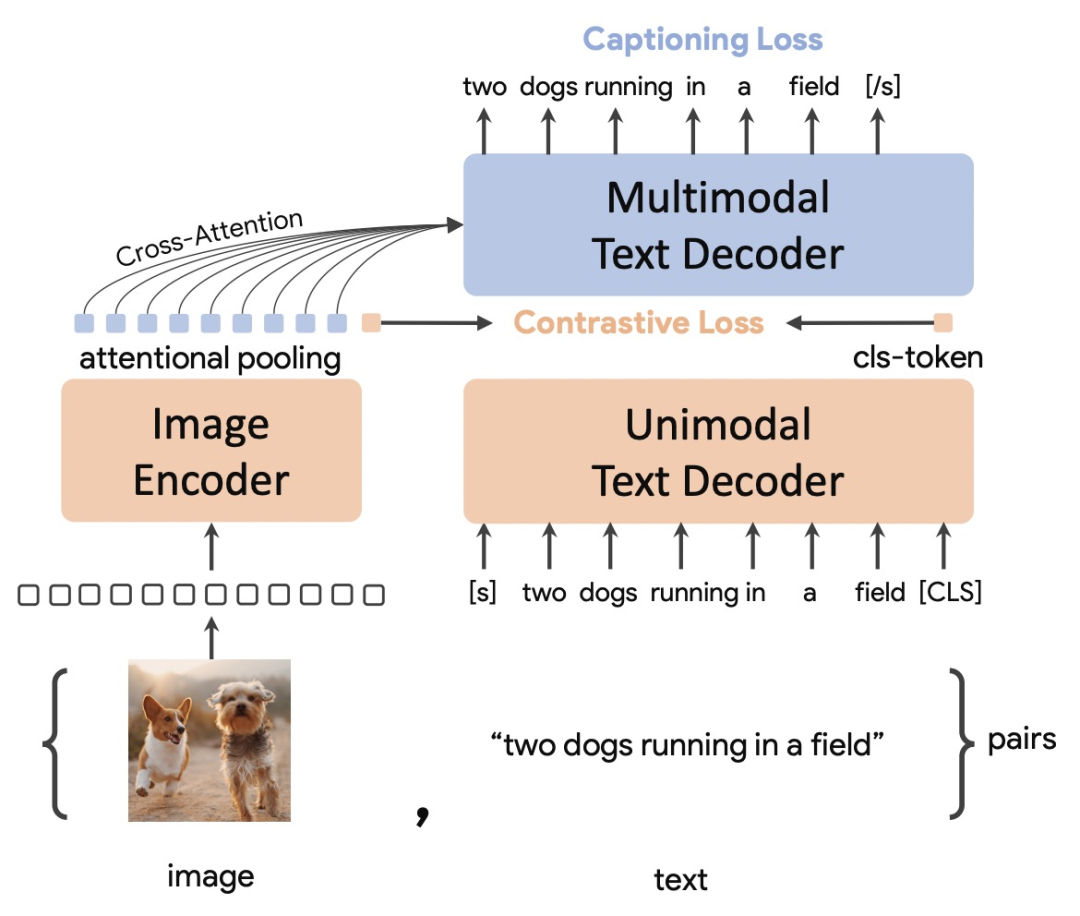
CoCa希望将三种类型的模型结构进行统一,这样模型可以同时使用3种类型的数据训练,获取更多维度的信息,也可以实现3种类型模型结构的优势互补。CoCa的整体结构包括3个部分:一个encoder(Image Encoder)和两个decoder(Unimodal Text Decoder、Multimodal Text Decoder)。Image Encoder采用一个图像模型,例如ViT等。Unimodal Text Decoder在这里起到CLIP中text encoder的作用,是一个不和图像侧信息交互的文本解码器。Unimodal Text Decoder和Image Encoder之间没有cross attention,实际上是一个单向语言模型。最后,Multimodal Text Decoder在单模态文本decoder之上,和图像encoder进行交互,生成图像和文本交互信息,并解码还原对应文本。注意两个文本decoder都是单向的,防止信息泄露。
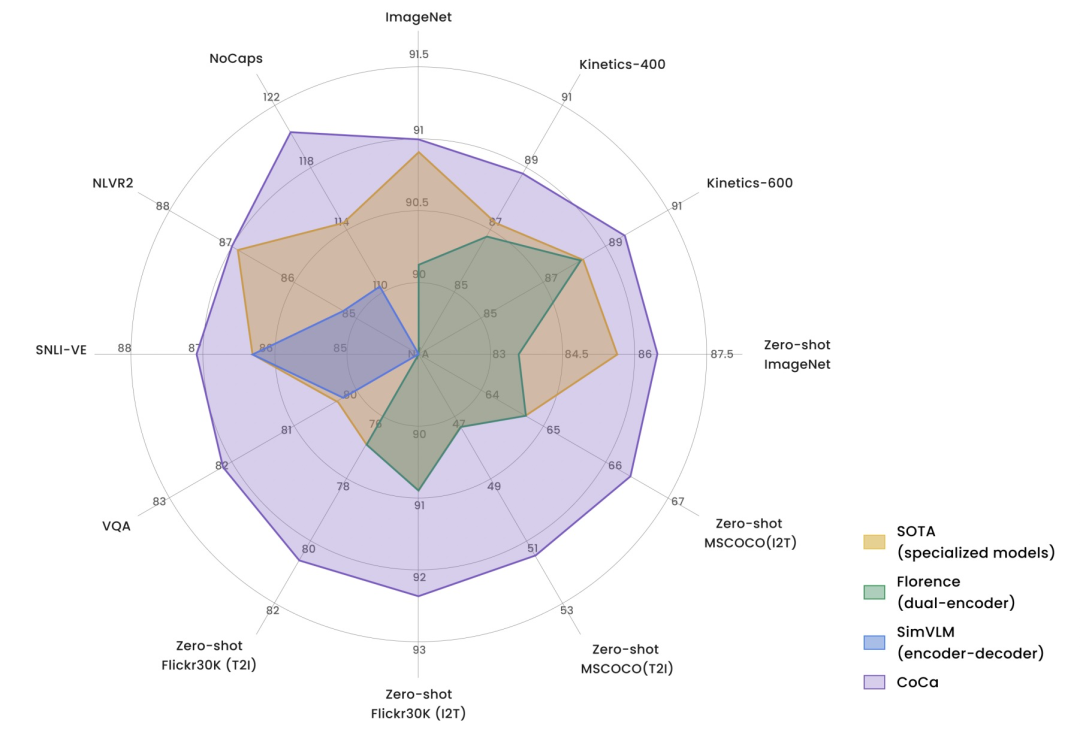
CoCa在多个任务上取得非常亮眼的效果。下图是CoCa和3种类型图文模型在多个任务上的效果对比,CoCa的优势非常明显。多个任务和数据集上达到SOTA,在ImageNet上达到91%的效果。
论文题目:Unified Contrastive Learning in Image-Text-Label Space
下载地址:https://arxiv.org/pdf/2204.03610.pdf
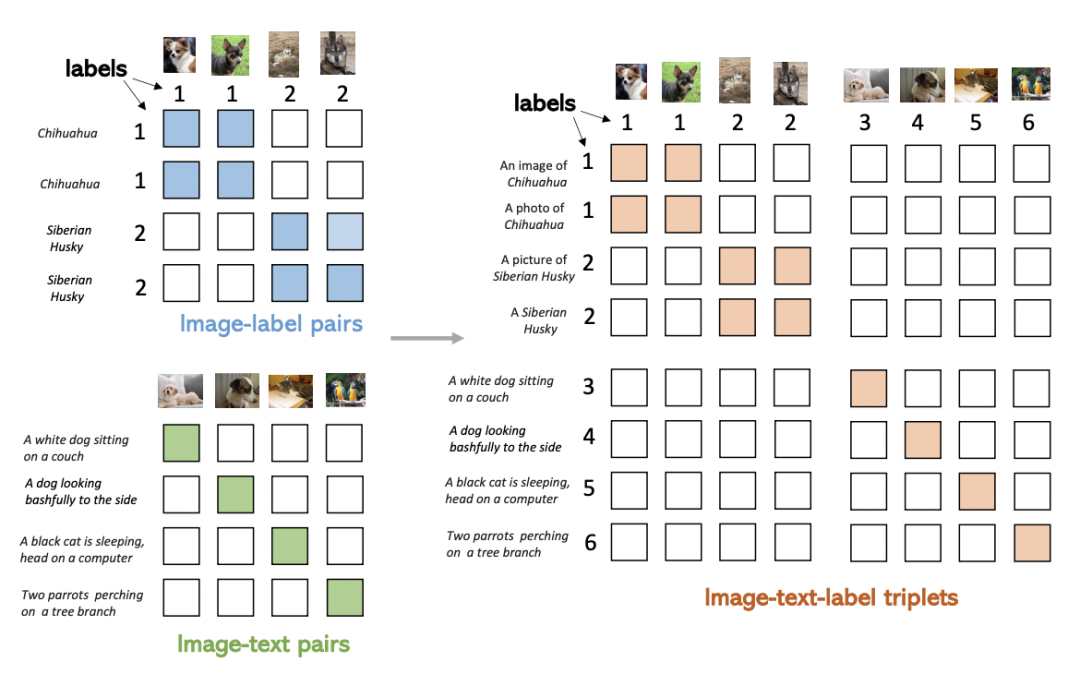
本文提出的方法希望同时利用图像、文本、label三者的信息,构建一个统一的对比学习框架,同时利用两种训练模式的优势。下图反映了两种训练模式的差异,Image-Label以离散label为目标,将相同概念的图像视为一组,完全忽视文本信息;而Image-Text以图文对匹配为目标,每一对图文可以视作一个单独的label,文本侧引入丰富的语义信息。

本文的核心方法是在数据格式上进行统一,以此实现同时使用Image-Text和Image-Label数据的目标。这两种类型的数据可以表示成一个统一的形式:(图像,文本,label)三元组。其中,对于Image-Lable数据,文本是每个label对应的类别名称,label对应的每个类别的离散标签;对于Image-Text数据,文本是每个图像的文本描述,label对于每对匹配的图文对都是不同的。将两种数据融合到一起,如下图右侧所示,可以形成一个矩阵,填充部分为正样本,其他为负样本。Image-Label数据中,对应类别的图文为正样本;Image-Text中对角线为正样本。通过这种方式统一格式后的数据,可以直接使用原来CLIP中的对比学习方式进行训练,实现了同时使用多种类型数据的目的。
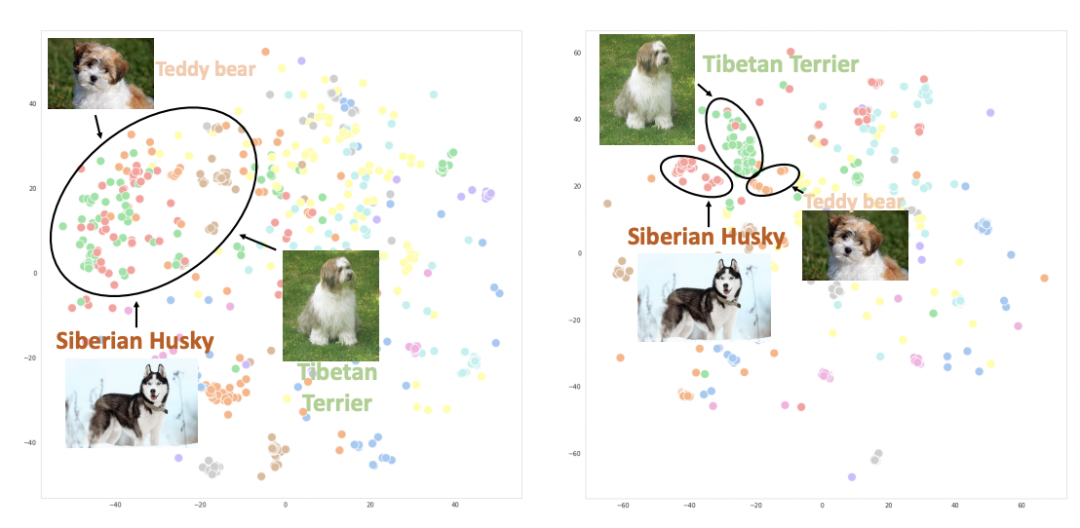
下图绘制了使用CLIP(左)和UniCL(右)两种方法训练的图像embedding的t-sne图。可以看到,使用CLIP训练的模型,不同类别的图像表示混在一起;而使用UniCL训练的模型,不同类别的图像表示能够比较好的得到区分。
论文题目:FLAVA: A Foundational Language And Vision Alignment Model
下载地址:https://arxiv.org/pdf/2112.04482.pdf
FLAVA方法的出发点是,一个训练的比较好的多模态模型,不仅在图文跨模态任务上效果好,同时也能在图片或文本的单模态任务上效果好。因此,FLAVA提出,在训练多模态模型时,同时引入图像领域和NLP领域的单模态任务,提升单模态模型的效果,这有助于多模态模型后续的训练。
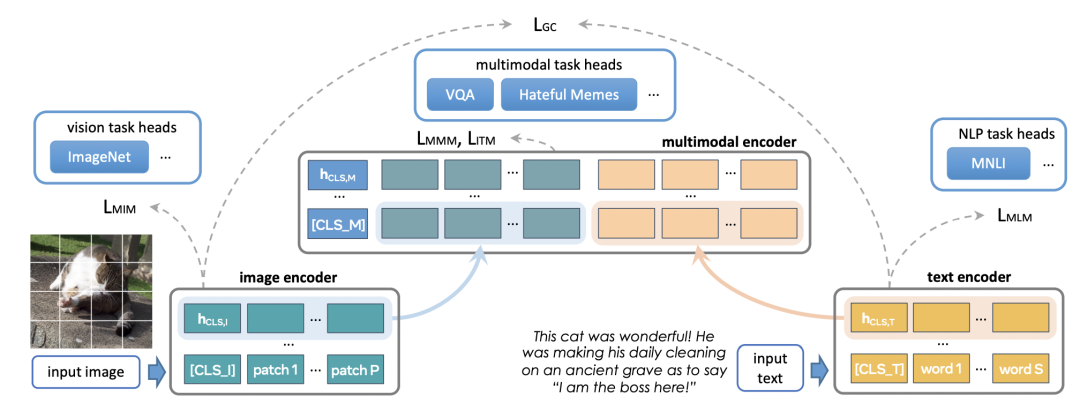
FLAVA的具体模型结构如下图所示,底层是两个独立的Image Encoder和Text Encoder,上层使用一个跨模态的Multimodal Encoder,实现图像侧和文本侧信息的交叉。Multimodal Encoder的输入是Image Encoder和Text Encoder各自的输出拼接到一起。预训练任务除了CLIP中的图文对比学习外,新增了下面3种loss:
Masked multimodal modeling (MMM):对文本中的部分token和图像中的部分patch进行mask,让模型进行预测,可以视为mask单模态token的一种扩展。
Masked image modeling (MIM):MIM是图像Encoder内部的单模态优化目标,对图像中部分patch进行mask,然后使用图像Encoder进行预测。
Masked language modeling (MLM):MLM则是BERT中的基础方法,mask部分token后进行还原。
Image-text matching (ITM):图像和文本的匹配loss,和对比学习loss类似,用于学习样本全局的表示。
在训练过程中,首先使用单模态任务(MIM、MLM)进行单模态模型的预训练,然后再同时使用单模态和多模态任务继续训练。
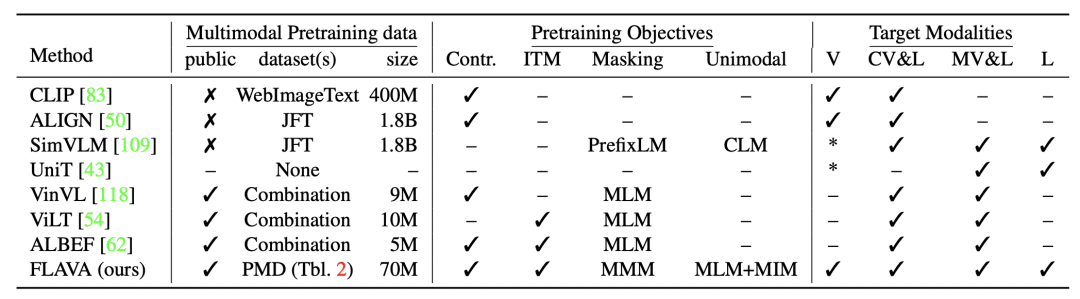
下表对比了FLAVA和其他多模态模型在训练数据、预训练任务和可解决的模态上的差异。FLAVA使用了多种单模态数据,让模型能够同时处理单模态和多模态任务。
论文题目:Prefix Conditioning Unifies Language and Label Supervision
下载地址:https://arxiv.org/pdf/2206.01125.pdf
本文也是希望同时引入图像-文本pair数据,以及图像的label数据。与Unified Contrastive Learning in Image-Text-Label Space这篇文章的思路不同,本文的主要问题点是如何解决两种类型数据在分布上的差异,主要是文本侧的分布差异。对于图像的文本描述,一般都是比较长且内容比较多的。而通过Image-Label转换而来的图像-文本对,文本侧都是比较干净的类目信息,例如A photo of a cat。两种数据的差异导致多模态匹配时,需要关注的信息、图文两侧交互的方法也会有不同。
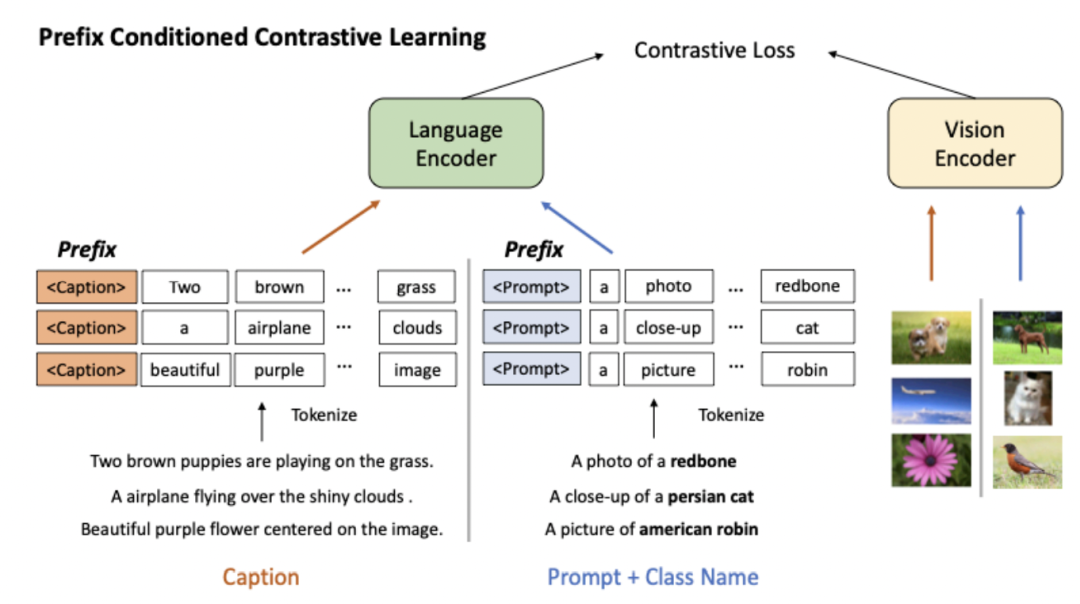
这篇文章采用了prefix prompt的思路解决两种类型数据文本侧数据分布差异大的问题。Prefix prompt原本是用于轻量级finetune的,在finetune大模型的时候,加上任务特定的prompt前缀向量,只finetune这个前缀向量,原理是利用prompt的思路作为上下文信息影响其他位置元素的表示生成过程。对prefix prompt感兴趣的同学可以参考这篇文章:NLP Prompt系列——Prompt Engineering方法详细梳理。本文在两种类型的数据前面拼接了两个不同的prefix向量,分别对应文本描述数据和Image-label转换而来的数据。在预训练阶段就引入prefix prompt,让模型在预训练过程中就能区分两种类型的数据。
从下面的Attention Map可以看到,对于不同的prefix prompt和数据类型,模型在文本侧的Attention分布有比较明显的差异,即使其他文本是完全相同的。文本描述(Caption)的prefix prompt对应的attention map,呈现出相对均匀的分布,对多个token都比较关注;而Image-Label的prefix prompt对应的attention map,则更关注类目相关的关键性的几个字。这表明模型学到了如何区分不同类型的数据,并将其存储到prefix prompt的向量中,用来影响整个句子的表示生成。

本文介绍了多模态模型优化中的引入多种类型数据的研究方向。近期的论文中,这类工作表多,是目前业内研究的热点,也是能够显著提高多模态模型效果的方法。