
如何从头训练一个一键抠图模型
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
抠图是图像编辑的基础功能之一,在抠图的基础上可以发展出很多有意思的玩法和特效。比如一键更换背景、一键任务卡通化、一键人物素描化等。正是因为这些有意思的玩法,CVPy网站上的一键抠图功能上线以来,从赞数来看,人气之高已经遥遥领先于CV派内其他高手,可见此模型的受欢迎程度。
笔者最近也是对此模型背后的U-2-Net网络很感兴趣,收集数据训练了人脸素描化模型,尽管受限于数据集,只能在人脸图片上转换成功,但自己仍然玩的不亦乐乎。不仅乐于玩模型的有意思的效果,更乐在训练模型过程中,以及遇到问题解决问题过程中,对模型理解的不断加深。
笔者最近对一键扣图模型从头训练了一遍,并在训练过程中持续测试了不同阶段模型的表现,看着模型一点点的收敛,抠图效果慢慢变好。
此处记录下训练过程以及训练的效果。也可以对后来者有一个参考。
提前说一声,模型训练很耗时!
2.1 代码
代码是U-2-Net的开源代码,可以从Github下载:https://github.com/NathanUA/U-2-Net。这个模型本来是做显著性检测的,但是当成一键扣图模型也很好玩。
需要注意的地方是,如果是安装的最新的Pytorch,获取loss值的时候,需要将loss.data[0] 修改为loss.data.item()。
笔者在训练过程中曾尝试修改Loss函数为其他的,比如改成BCE和SSIM的加权(参考U-2-Net作者去年的文章BASNet),未见明显提升。也曾修改输出通道训练其他模型,暂无好玩的结果,就当是积累经验了。
2.2 数据
数据集我们就用论文中提到的DUTS数据集,已经分好了训练集和测试集。网上搜一下直接下载即可。
当然,也可以用自己的数据集,按照DUTS的格式重新组织下数据集即可。
然后在训练代码里面把数据读取部分的路径更换为自己准备的数据的路径。
2.3 机器
群里一土豪赞助了一台4卡的机器,4块 RTX 5000,每张卡16G内存。跑起来确实比单卡爽多了。
然后基于Anaconda安装训练所需的Python环境,创建虚拟环境,安装pytorch, torchvision, skimage, opencv等等,直接pip install或者conda install即可。不多说。
另外多卡的话,代码还需要有一些细微的改动,在构建模型之后,将代码:
if torch.cuda.is_available():
net.cuda()
修改为
if torch.cuda.is_available():
net.cuda()
net = nn.DataParallel(net)
3.1 模型训练
以上代码、数据、机器和运行环境都已经准备好之后,就可以开始训练了。多卡训练的命令大概长下面这样:
CUDA_VISIBLE_DEVICES=0,1,2,3 nohup python3 -u u2net_train.py > log_train.log &
然后tail命令查看日志文件log_train.log,如果看到下面这样的输出,说明跑起来了:
再用命令watch -n 1 nvidia-smi查看GPU的情况,可以看到四张卡都被充分利用起来了。
模型训练将近一周,达到了接近论文的效果。
另外,由于中间保存过多,为了节省空间,笔者删掉了太多前期模型,以下展示的前期效果是另外一次训练的前期模型的效果。
3.2 各阶段模型测试
笔者微调测试代码结构,把测试转移到了Jupyter里,这样画图看效果更加直观。
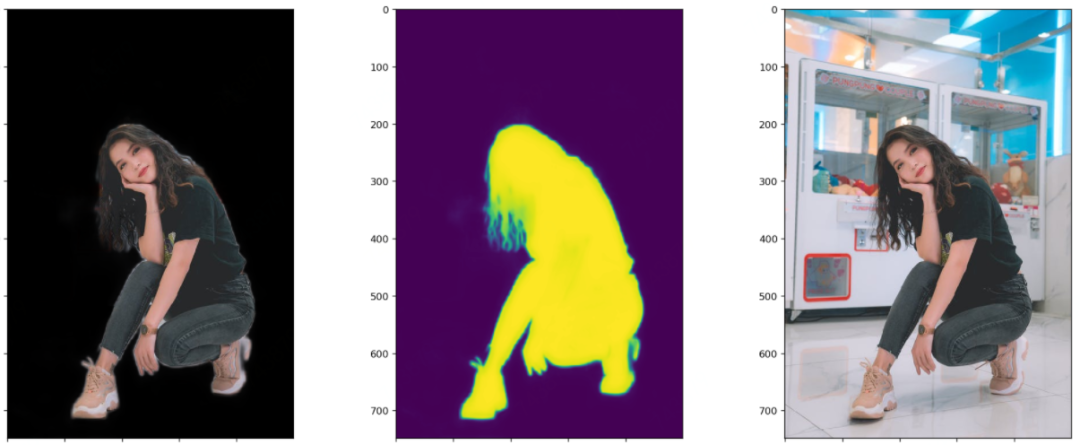
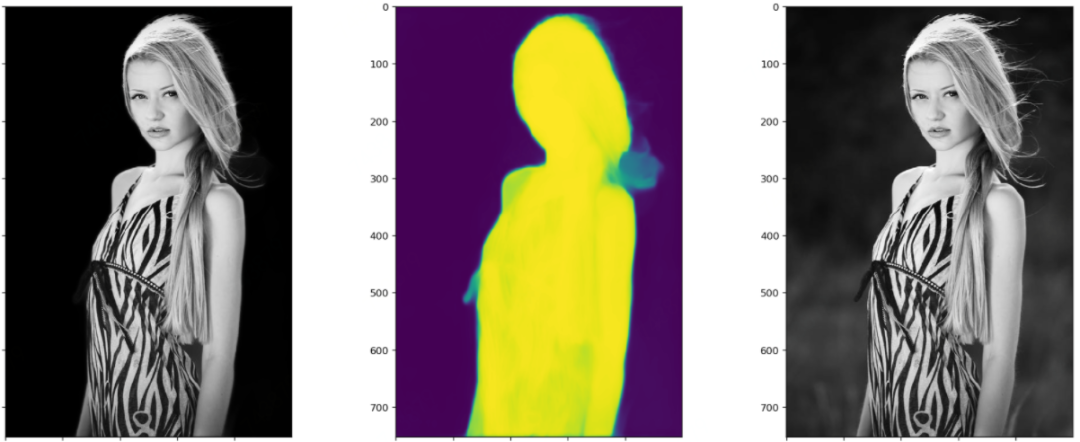
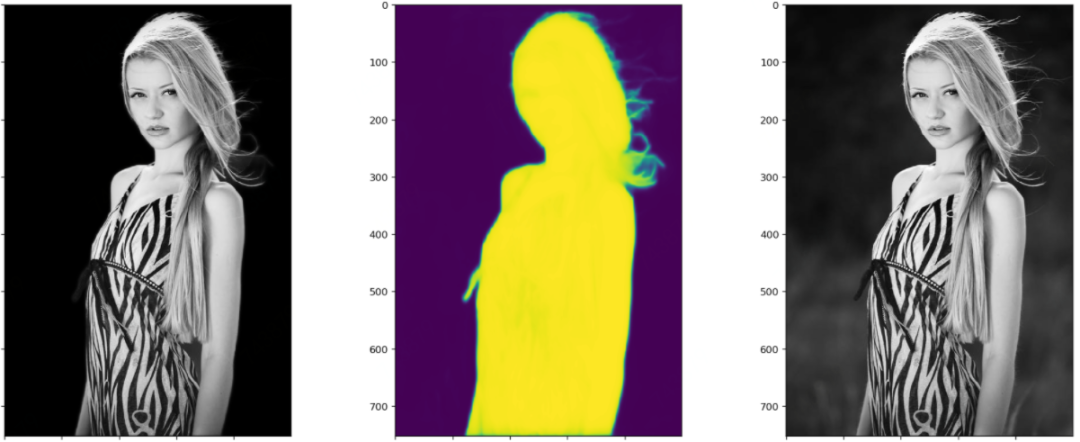
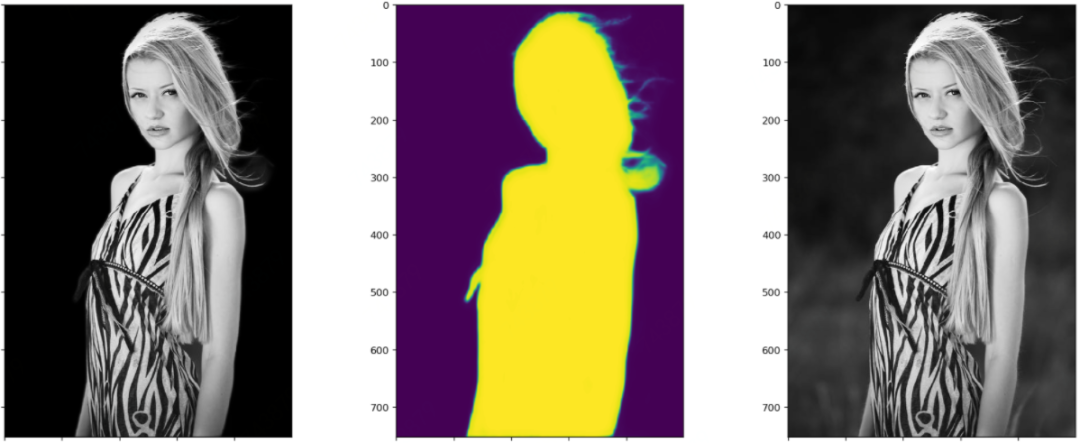
笔者测试模型的时候,每张图都会画出三个图:黑色背景的抠图结果、模型输出的Mask或称Alpha,原图。这样对比来看结果一目了然。这里每张图都展示了四个阶段模型的测试效果。显然,以下图片都不在训练集里面。
四个阶段对比着看,能更加直观地感受到模型的收敛过程。
从以下四个阶段的对比图可以看出,随着训练的进行
前景逐渐变亮,背景逐渐变暗,即前景收敛于1,背景收敛于0。前两幅图之间的对比最为明显。 前景的轮廓从模糊到清晰细锐,轮廓处的不确定区域,越来越少。 注意指缝和发梢部分的Mask的变化,细节越来越清晰。
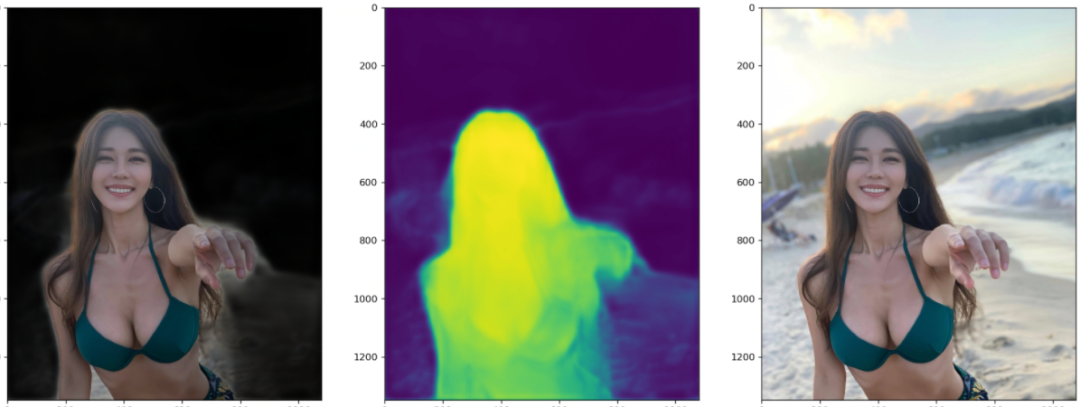
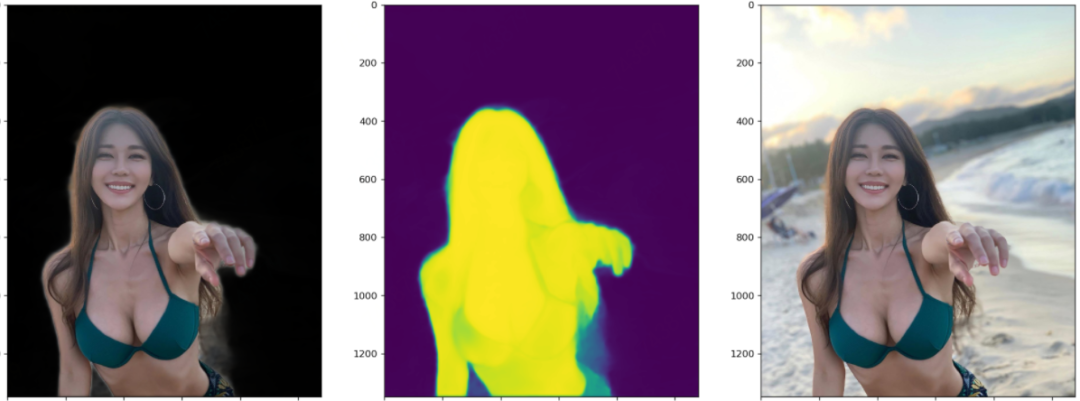
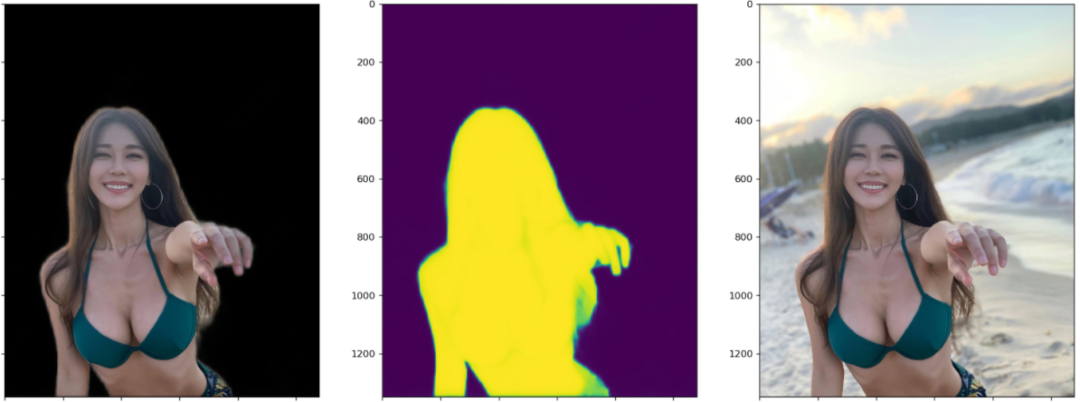
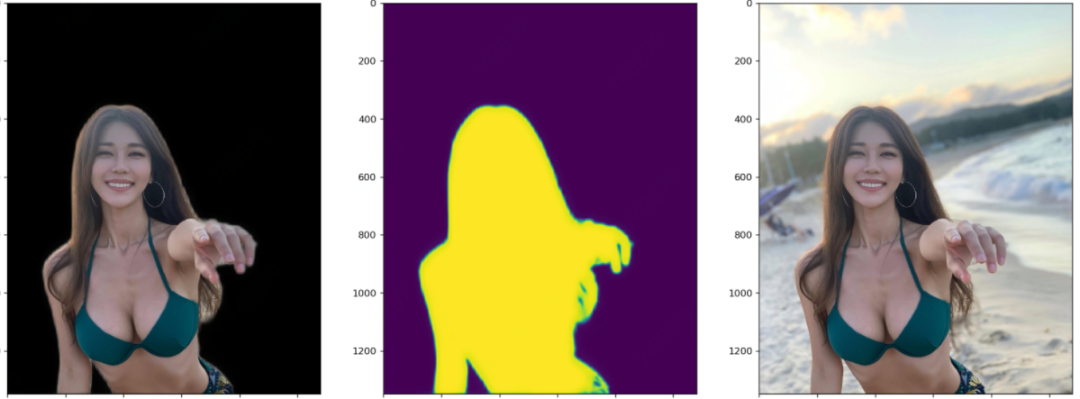
下面这幅图请注意这个卡通人物背后背的那个是蜗牛还是啥的东西的轮廓的细化过程。以及其嘴角的一撮小胡子。这个图美中不足的是两脚之间的背景没有被识别出来。




下面这张图值得关注的应该就是其发梢的抠图细化过程、腰部的亮度变化过程。还有就是其手中的衣服了,对于要不要把一副也给抠出来,模型看起来也很纠结啊。
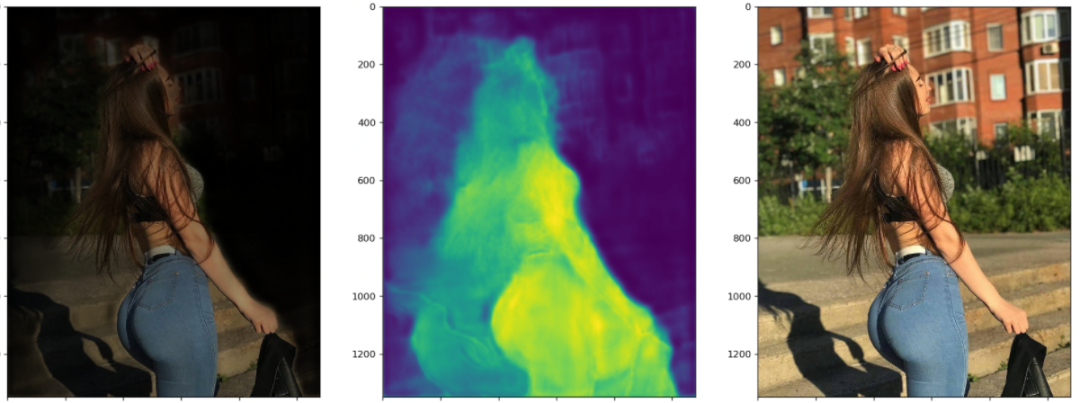
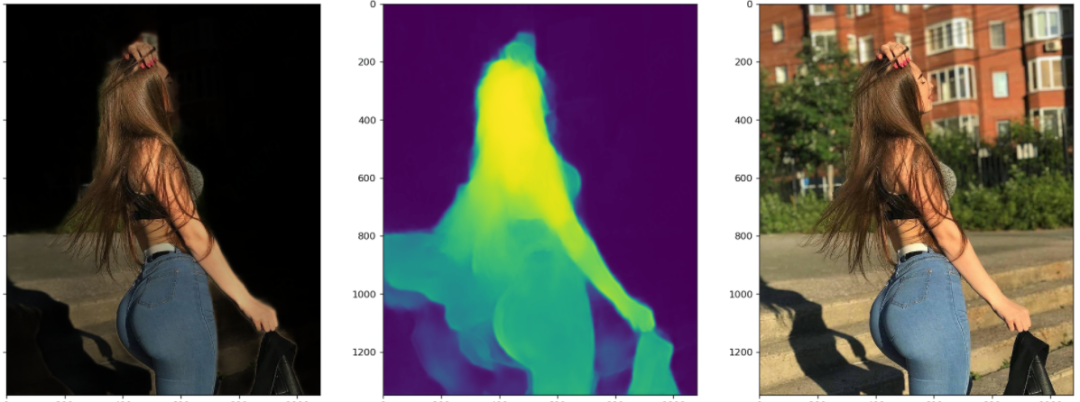
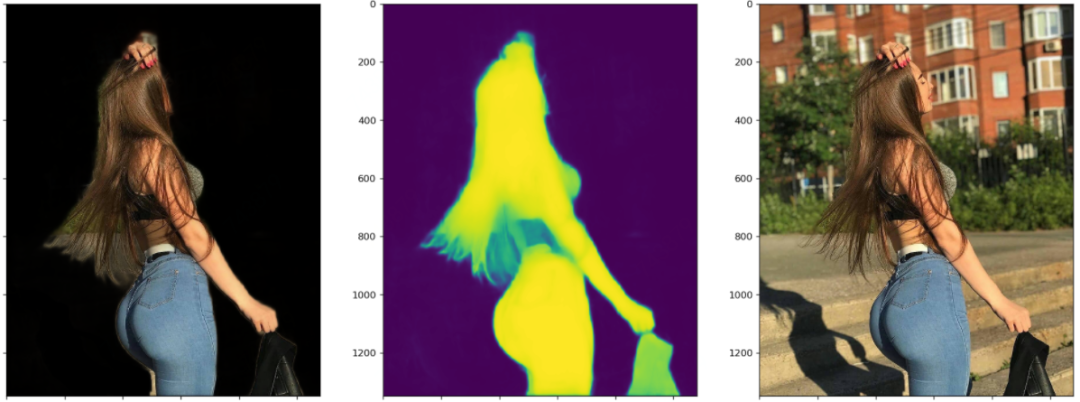
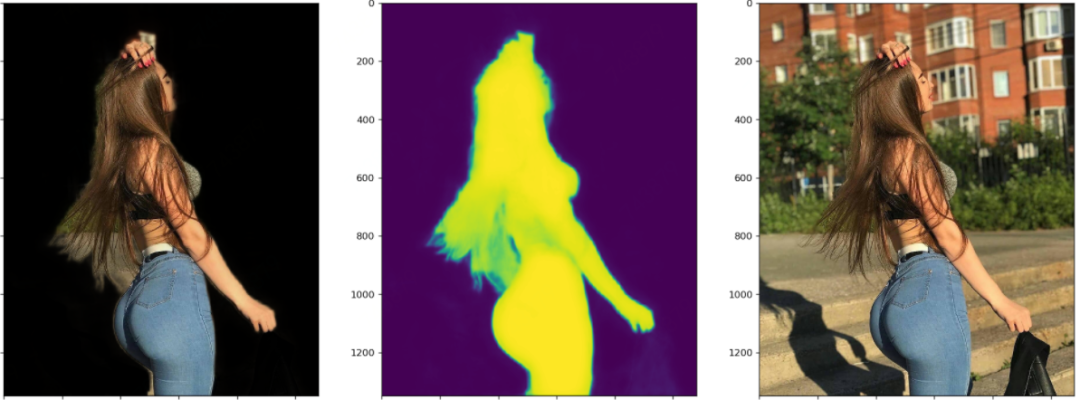
这个图最引人瞩目的莫过于这位美女在风中凌乱的发丝,这不是难为模型吗?说实话,如果不是看到Mask里胸前多出的东西,我都没注意到这个东西,衣服的胸结还是啥。
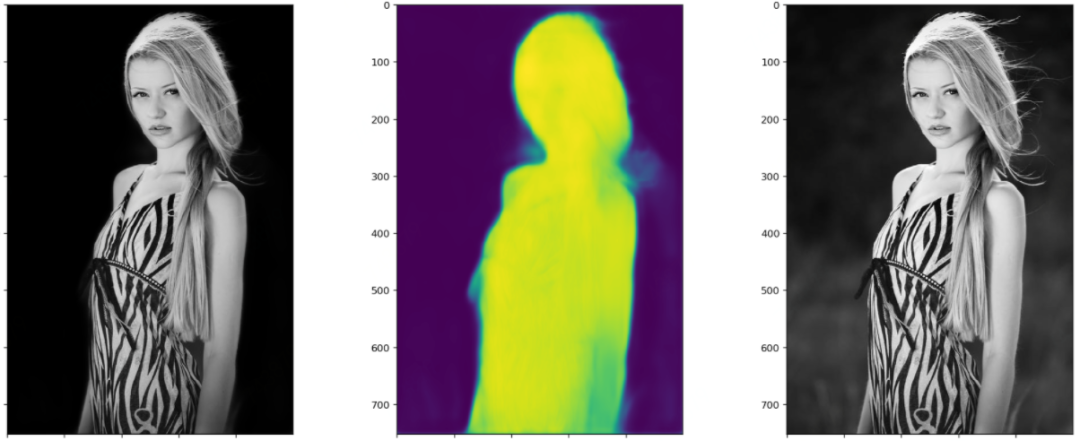
这大概就是训练了五天左右的效果,模型仍然在缓慢的收敛中,故事仍然在继续......
直到我实在是受不了越来越慢的收敛速度,等不及训练其他魔改的模型,终止了训练任务......
本着报喜不报忧的原则,下面再放几张测试效果还不错的图片,效果不怎么样的就不拿出来献丑了。
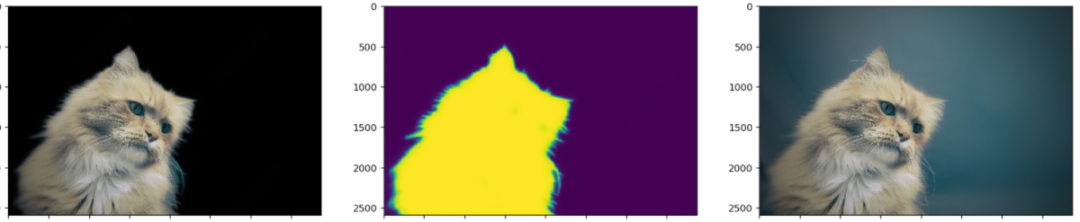
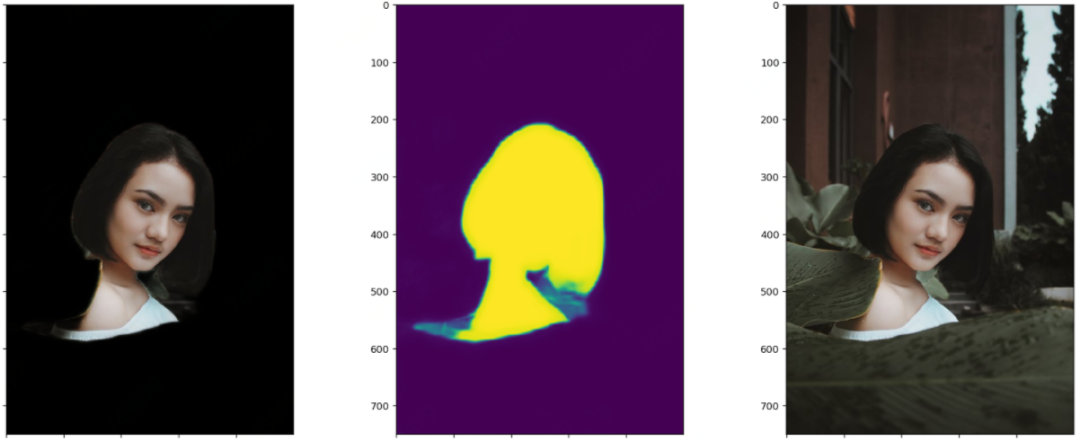
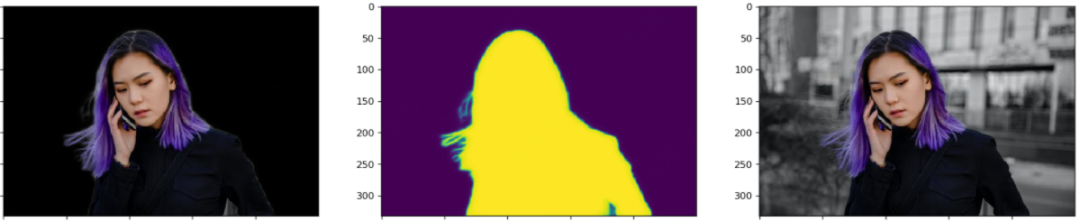
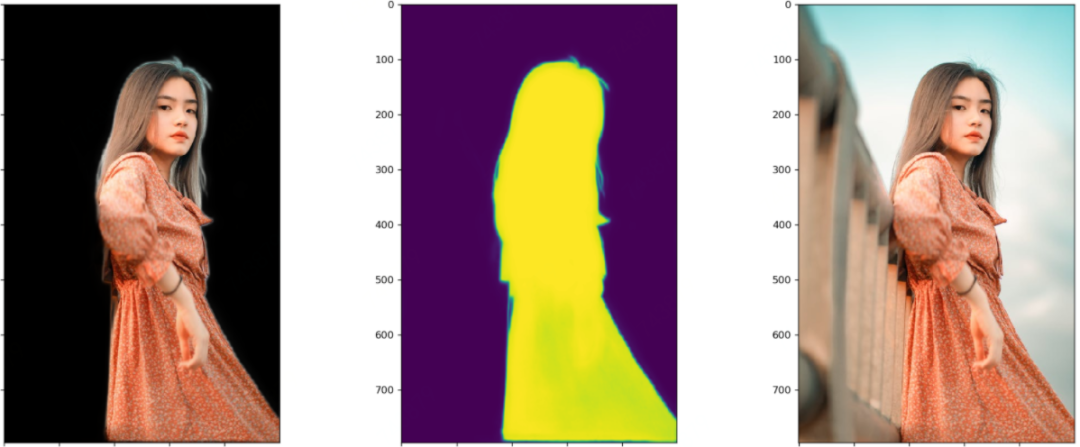
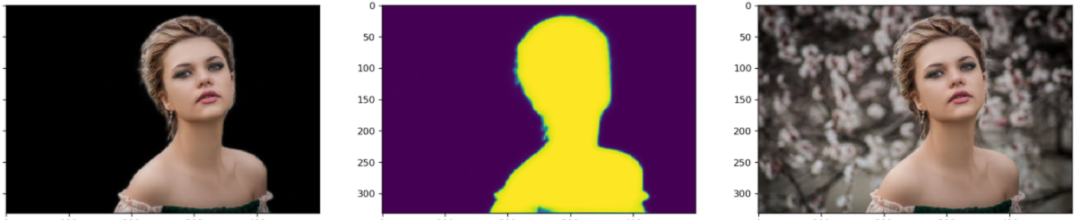
上面的抠图效果还是有待提高,比如头发等边缘处,还是可见部分背景未分离。前几天刚转发了动物抠图的新论文,边缘和毛发的抠图效果很赞。其单开一条支路专门做轮廓边缘处的抠图的思路值得参考。
不过,作者暂时开源了测试代码,并没有训练代码。我昨晚肝到十二点半,终于根据论文实现了一版训练代码,但是貌似收敛的更慢,这个优化还是慢慢来吧。就这训练速度,想快也快不起来啊。反正就是玩,好玩就行。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~