
【NLP】让AI读懂法律文书:一种基于多分类的关键句识别方法

法律领域是近年来在 NLP 社区兴起的一个研究场景,许多研究者从不同的角度对其进行了大量研究,例如对当事人的情感分析、提取案件当事人信息,提取侦破案件的关键判决信息,预测案件的结果等等。
近日,来自斯里兰卡莫拉图瓦大学(University of Moratuwa)计算机系的一组研究人员,提出一种使用句子嵌入向量(sentence embedding)和多分类技术(multi-classclassification),分析法律文件中关键句子的方法。
实验结果表明,他们的方法可以有效提高关键句识别性能,帮助降低从法律判例中搜寻重要事实或论点的工作量。
任务背景
判例法
在法律领域,判例法是使用过去的法庭案例来支持或反驳正在进行的法庭案件的论点,而不是使用宪法、法规和其他正式的法律定义。法律专业人士利用过去类似法庭案件中的判决来支持他们的主张。为此,他们会浏览判例文件,从中找到类似的案例和有价值的论点。
庭审中的当事人
法庭案件中的法律当事人可以是一个人或者构成实体的一群人。在任何一个法庭案件中,可以确定两个主要的法律当事人——公诉人、被告。注意,可能存在不属于任何一个主要方的第三方实体或人员。从这里开始,为了便于理解,两个主要当事人将被称为原告和被告。法庭案件中几乎所有的句子、事实和论据都是用来支持或反对两个主要当事人的。
庭审记录中的关键句
法律专业人员花费大量的时间阅读判例法文件,试图提取重要的事实来支持或反驳正在进行的案件,这一过程十分单调乏味。这些文件的语言相对复杂,而且数量每年都在增加。
如果能够通过自然语言处理技术(NLP)来完成这种重复而繁琐的提取重要事实或论据的工作,将会减少律师们工作,节省大量时间和金钱成本。
本研究的主要重点是识别和区分以往案例中的关键事实和论点,以支持或反对法庭案件的主要当事方。
相关基础技术工作
当事人情感分析数据集
法律领域使用自然语言处理技术,一个挑战是缺乏当事人情感分析数据集。这个问题,可以通过对最初从美国最高法院获取的包含近 2000 个句子的数据集进行当事人情感注释得以解决。
情感注释包含三个概念:原告和被告两个当事人、每个当事人在每个句子中表现的情感以及对句子整体情感。
交叉熵损失
平均绝对误差(Mean Absolute Error,MAE)只在少数假设条件下可以正常发挥作用。当数据集的分类标签变得有噪声时,MAE 的性能开始变差,而交叉熵损失(Cross Entropy Loss)的调整对有噪声的数据工作很好。Zhang 和 Sabuncu 对 3 个不同噪声水平的数据集进行了综合添加噪声的改进交叉熵损失函数实验,均优于 MAE。
关键句子识别
Glaser 等人研究了基于 9 种不同语义类别的法律合同句子分类。研究实验是针对德语法律文本进行的。
首先,机器学习模型被训练用于从德国民法典中提取句子,然后用于法律合同中提取合同中相应的关键句子。Jagadeesh 等研究人员提出了一种顺序过程来进行文档摘要,然后提取重要的句子。
为此,在第一部分中,他们使用了带有命名实体识别(NER)和词性标注(PoS)的句法分析,基于命名实体识别(NER)、词性标注(PoS)、词频等的特征提取,根据特征对句子打分,并对句子进行排序。该系统允许根据查询提取句子,生成连贯分数是其中的关键步骤。Hirao 等人利用支持向量机(SVM)研究了句子提取方面的问题。从文档中提取关键句子的方法类似于文本摘要,并根据重要和不重要两类对句子进行分类。在当时,它们还能够击败其他三种文本摘要方法。
研究方法
最初,研究团队对只标注了判决的句子进行探索性分析,发现数据集需要更加详细,以便模型学习。有了这种洞察后,就需要为这项任务准备一个适当的数据集。
本研究的数据集是 Mudalige 等人创建的基于当事人的情感分析(PBSA)数据集的扩展,该数据集可在 OSF1 上公开获得。PBSA 数据集由 Sugathadasa 等人从美国最高法院的 25 份判例法文件中提取的 1822 个精确的句子和有意义的子句组成,以及其中对当事人的看法和整体看法。
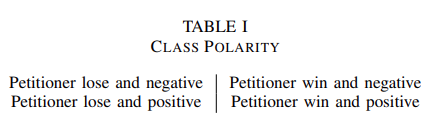
通过为每个判决添加每个法庭案件的判决,研究团队扩展了数据集。根据胜诉方和判决对胜诉方的影响,将判决分为四类。一个句子可以分为以下几类:
1.原告败诉,并对原告产生负面影响
2.原告败诉,但对原告产生正面影响
3.原告胜诉,但对原告产生负面影响
4.原告胜诉,并对原告产生正面影响
根据以上分类,一个句子被认为是关键句,当:
原告胜诉时,对原告有正面影响 原告败诉时,对原告有负面影响
PBSA 数据集对每句提及当事人的话中都进行了情感标签标注。使用这些情绪标签来计算每句话对原告的影响。

原告:Lee——负面(-1) 被告:officials——正面(+1),they——正面(+1)
多分类模型
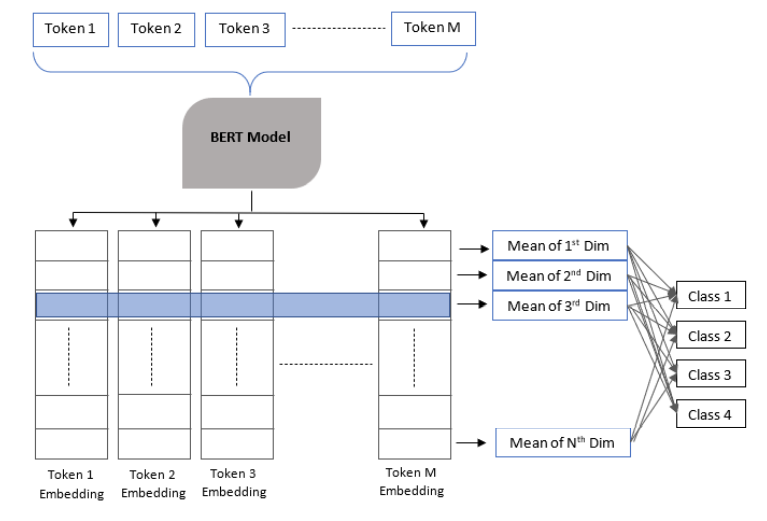
任务相关的损失函数
但研究定义了一个新的损失函数,它考虑了其他类的概率,而不是标记类的概率。本文中讨论的分类任务包含四个类,根据法院案件的判决可以分为两个极性。在算法 1 中定义了损失函数,它考虑了类的极性。

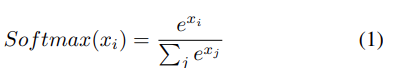
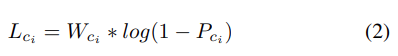
实验分析
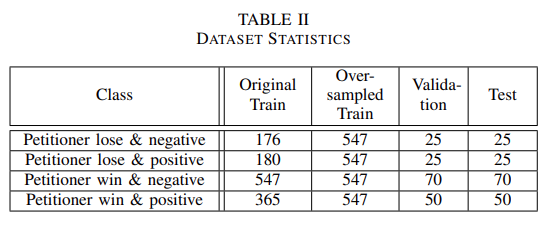
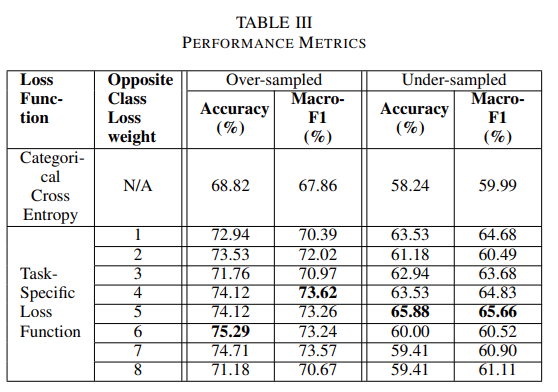
相比之下,欠采样方法减少了 3 个数量较多的类的样本,以匹配样本数量最少的类。使用这两种组合的数据集来训练分类模型,首先使用分类交叉熵损失训练,然后使用任务特定损失函数训练。团队实验了相反的类减重超参数,指标比较如表三所示。
总结与展望
往期精彩回顾 本站qq群955171419,加入微信群请扫码: