
深度学习中图像分割经典算法和必备知识点整理
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
1
很多关注的朋友一直会问“计算机视觉研究院“有基础性的内容吗?”,今天我和大家说一次,我们平台之前有推送很多基础的知识,有兴趣的或者是刚刚接触CV&DL的你,可以去历史消息阅读,在这也感谢所有一直关注和支持我们的小伙伴!接下来就和大家说说目标分割的事吧~
分割其实在很多领域是非常重要的研究对象,现在也有很多研究者在该领域大展身手,比如何大神,一直在该方面的做的最优秀之一,今天就基于他CVPR 2018的一篇优秀Paper说起。
2
概述
大多数目标实例分割的方法都要求所有的训练样本带有segmentation masks。这种要求就使得注释新类别的开销很大,并且将实例分段模型限制为∼100注释良好的类。
本次技术目的是提出一种新的部分监督的训练模式,该模式具有一种新的权重传递函数,结合一种新的权重传递函数,可以在一大组类别上进行训练实例分割模型,所有这些类别都有框注释,但只有一小部分有mask注释。这些设计允许我们训练MASK R-CNN,使用VisualGenome数据集的框注释和COCO数据集中80个类的mask注释来检测和分割3000种视觉概念。
最终,在COCO数据集的对照研究中评估了提出的方法。这项工作是迈向对视觉世界有广泛理解的实例分割模型的第一步。
在正式细说本次分割技术之前,还是简单说下分割的事,有一个简单的引言和大家分享下,没有兴趣的您可以直接跳过,阅读关键技术部分,谢谢!
目标检测器已经变得更加精确,并获得了重要的新功能。最令人兴奋的是能够预测每个检测到的目标前景分割mask,这是一个称为instance segmentation的任务。在实践中,典型的instance segmentation系统仅限于仅包含大约100个目标类别的广阔视觉世界的一小部分。
会有很多人问:什么是语义分割?
比较流行经典的几种方法
第一种是编码-译码架构。编码过程通过池化层逐渐减少位置信息、抽取抽象特征;译码过程逐渐恢复位置信息。一般译码与编码间有直接的连接。该类架构中U-net 是最流行的。
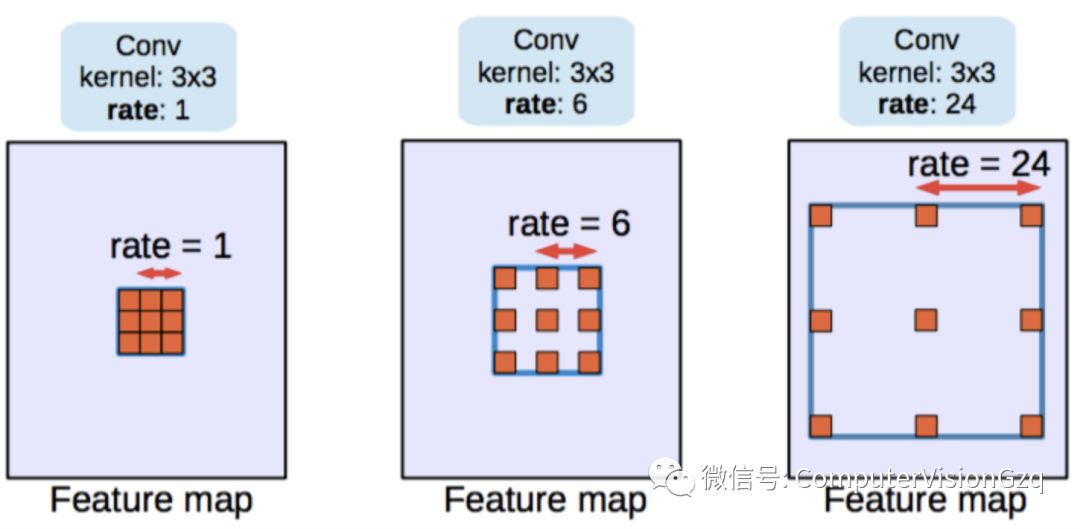
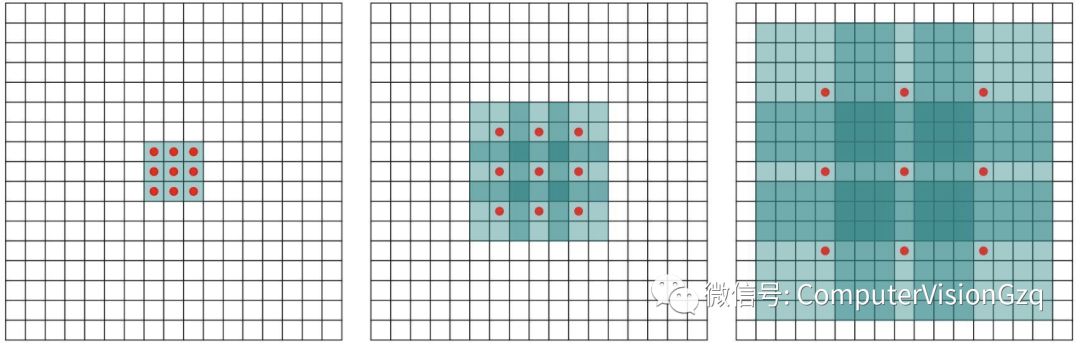
第二种是膨胀卷积 (dilated convolutions) 【这个核心技术值得去阅读学习】,抛弃了池化层。使用的卷积核如下图所示:
居然都说到这里,那我继续来简单说一些相关的文献吧。
参考文章:(“计算机视觉战队”微信公众平台推送)
1)FCN 2014年
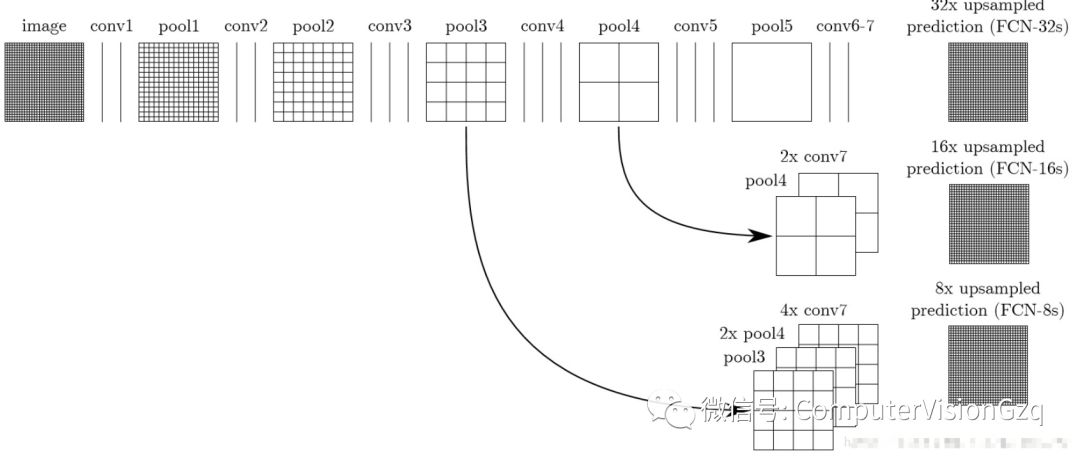
主要的贡献:
为语义分割引入了 端到端 的全卷积网络,并流行开来
重新利用 ImageNet 的预训练网络用于语义分割
使用 反卷积层 进行上采样
引入跳跃连接来改善上采样粗糙的像素定位
比较重要的发现是,分类网络中的全连接层可以看作对输入的全域卷积操作,这种转换能使计算更为高效,并且能重新利用ImageNet的预训练网络。经过多层卷积及池化操作后,需要进行上采样,FCN使用反卷积(可学习)取代简单的线性插值算法进行上采样。
2)SegNet 2015年
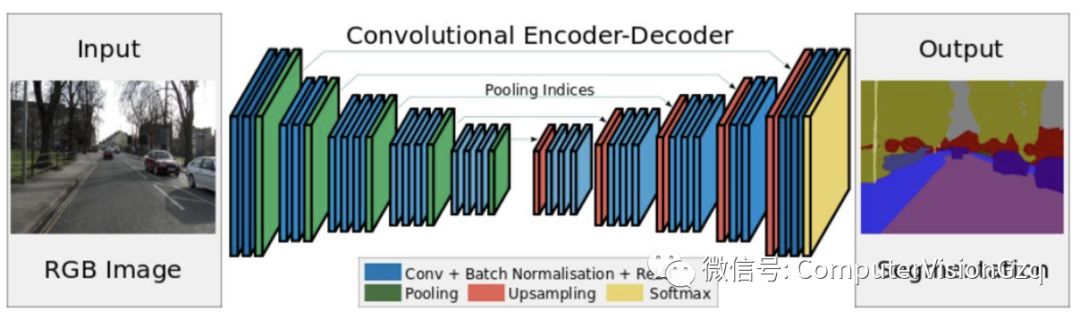
编码-译码架构
主要贡献:将池化层结果应用到译码过程。引入了更多的编码信息。使用的是pooling indices而不是直接复制特征,只是将编码过程中 pool 的位置记下来,在 uppooling 是使用该信息进行 pooling 。
3)U-Net 2015
4)Dilated Convolutions 2015年
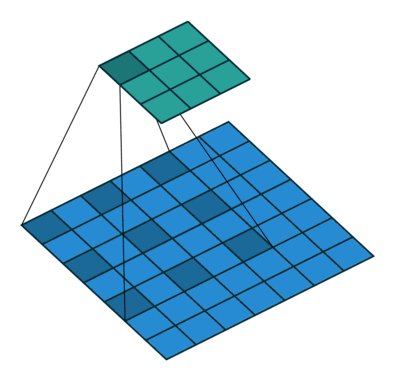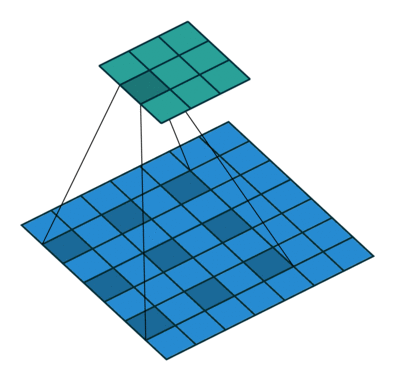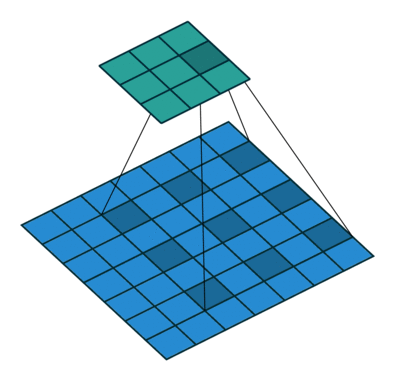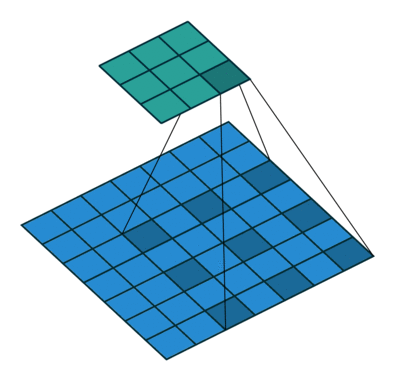
主要贡献:
使用膨胀卷积
提出 ’context module‘ ,用来聚合多尺度的信息
池化在分类网络中能够扩大感知域,同样降低了分辨率,所以提出了膨胀卷积层。
5)DeepLab (v1 & v2) 2014 & 2016
“计算机视觉战队”微信公众平台推送过,可以查阅:
6)RefineNet 2016年
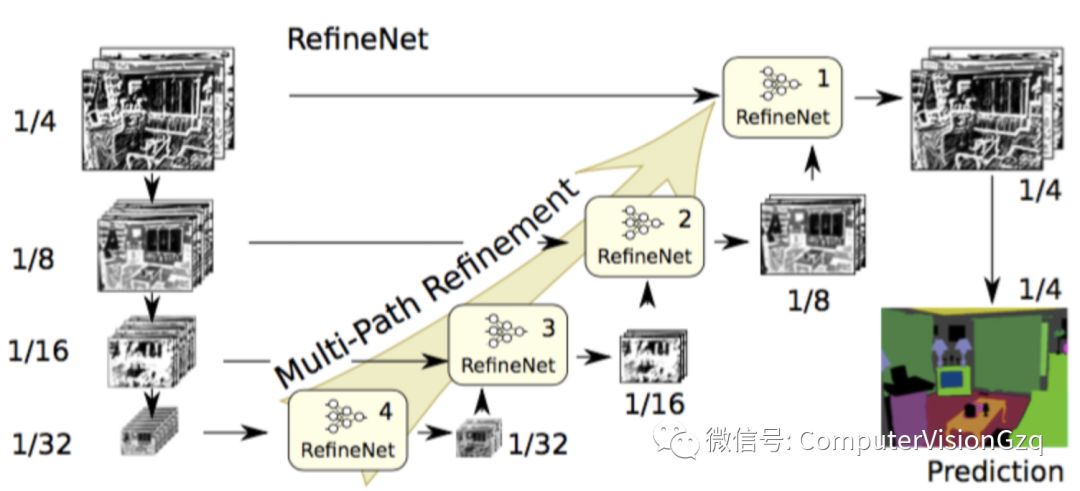
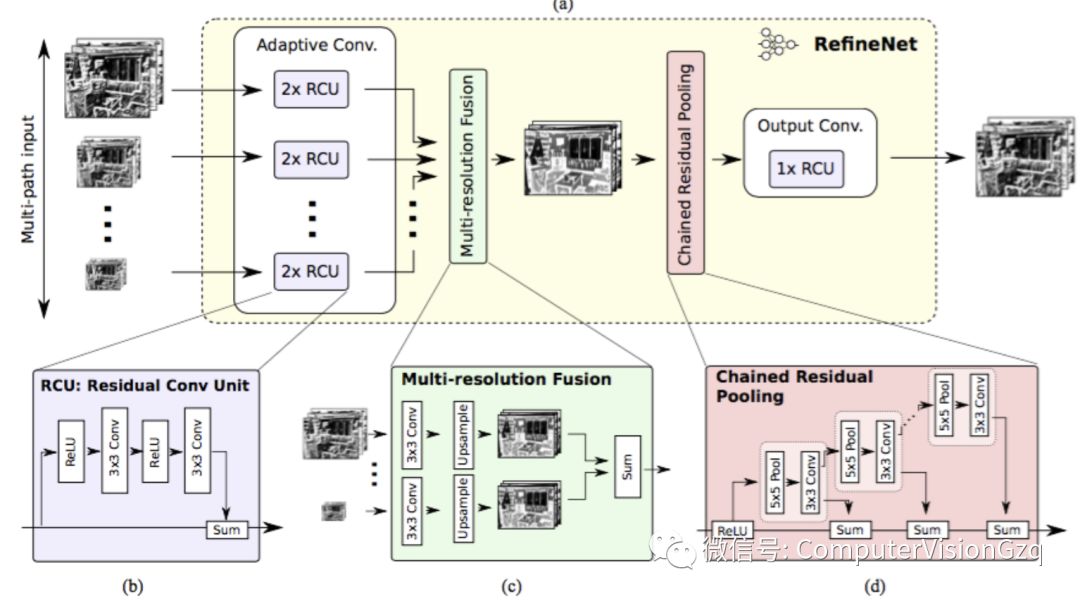
主要贡献:
精心设计的译码模块
所有模块遵循残余连接设计
膨胀卷积有几个缺点,如计算量大、需要大量内存。这篇文章采用编码-译码架构。编码部分是ResNet-101模块。译码采用RefineNet模块,该模块融合了编码模块的高分辨率特征和前一个RefineNet模块的抽象特征。每个RefineNet模块接收多个不同分辨率特征,并融合。
7)PSPNet 2016年
Pyramid Scene Parsing Network 金字塔场景解析网络
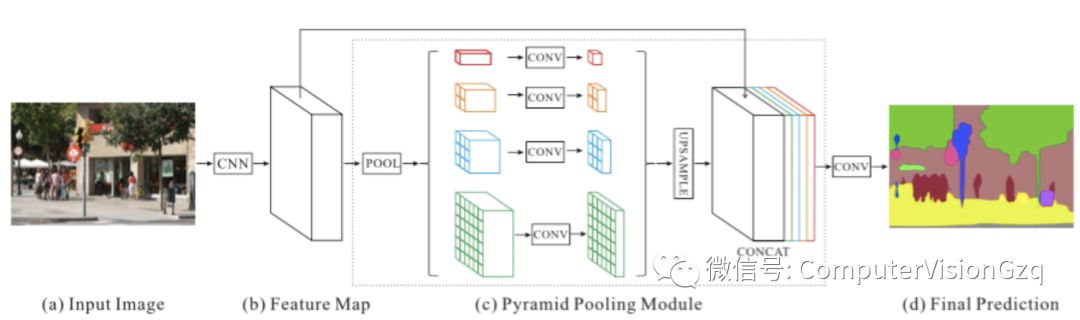
主要贡献:
提出了金字塔池化模块来聚合图片信息
使用附加的损失函数
金字塔池化模块通过应用大核心池化层来提高感知域。使用膨胀卷积来修改ResNet网,并增加了金字塔池化模块。金字塔池化模块对ResNet输出的特征进行不同规模的池化操作,并作上采样后,拼接起来,最后得到结果。
8)Large Kernel Matters 2017
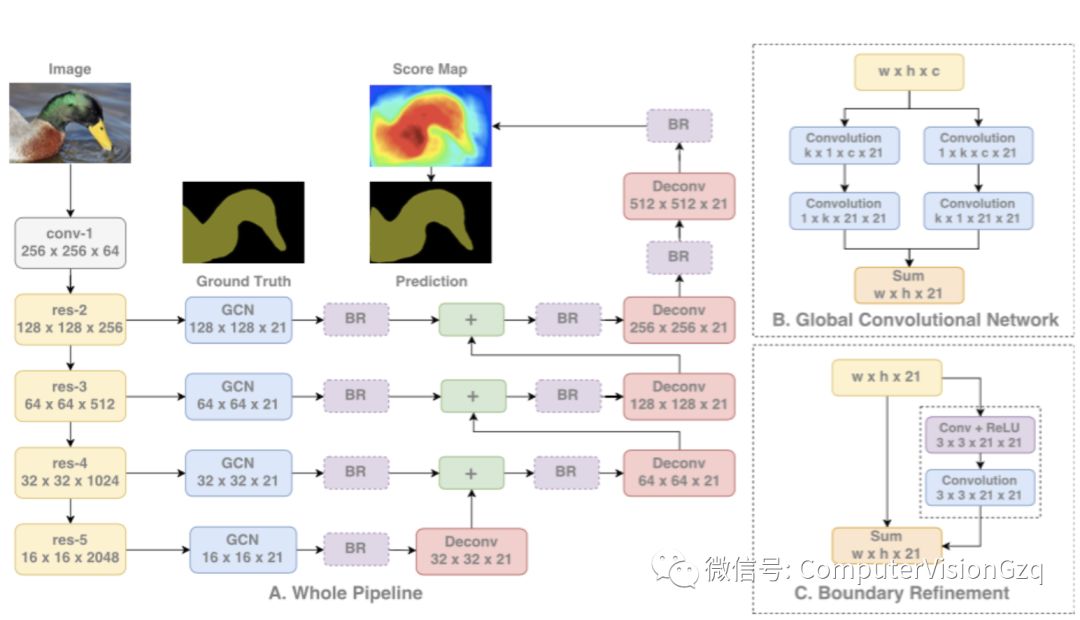
主要贡献:
提出了使用大卷积核的编码-译码架构
理论上更深的ResNet能有很大的感知域,但研究表明实际上提取的信息来自很小的范围,因此使用大核来扩大感知域。但是核越大,计算量越大,因此将k x k的卷积近似转换为1 x k + k x 1和k x 1 + 1 x k卷积的和,称为GCN。
9)DeepLab v3 2017(这个我们即将给大家接着上次系列继续分享)
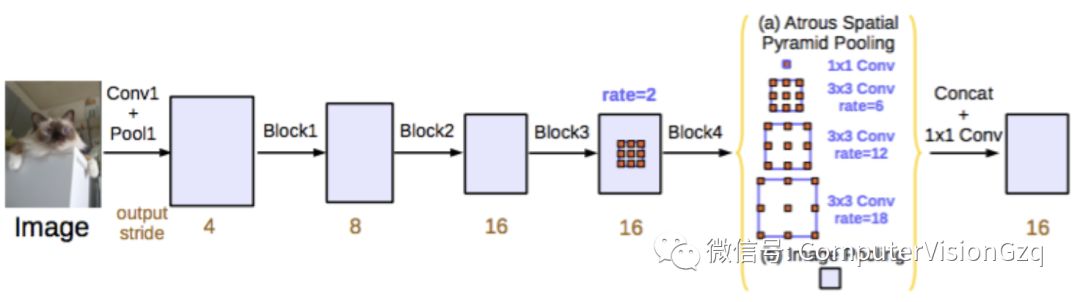
主要贡献:
改进 ASPP
串行部署 ASPP 的模块
小总结:
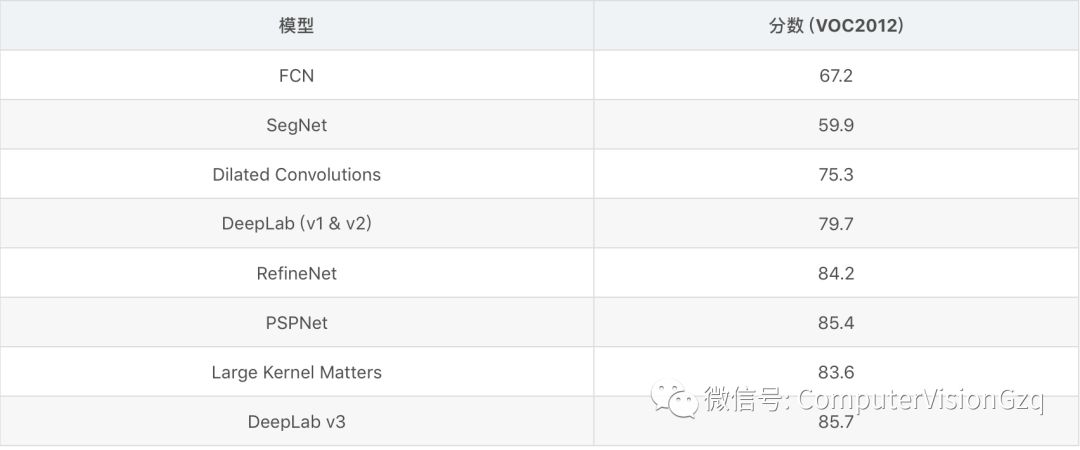
现在把之前较为典型的简单介绍了一遍,现在接下来我们继续说今天这个分割技术。
3
学习分割Everything
权重传递来Mask预测
本方法是建立在Mask R-CNN,因为它是一个简单的instance segmentation模型,也取得了最先进的结果。简单地说,MASK R-CNN可以被看作是一个更快的R-CNN边界框检测模型,它有一个附加的mask分支,即一个小的全卷积网络(FCN)。
在推理时,将mask分支应用于每个检测到的对象,以预测instance-level的前景分割mask。在训练过程中,mask分支与Faster R-CNN中的标准边界框head并行训练。在Mask R-CNN中,边界框分支中的最后一层和mask分支中的最后一层都包含特定类别的参数,这些参数分别用于对每个类别执行边界框分类和instance mask预测。与独立学习类别特定的包围框参数和mask参数不同,我们建议使用一个通用的、与类别无关的权重传递函数来预测一个类别的mask参数,该函数可以作为整个模型的一部分进行联合训练。
具体如下如所示:
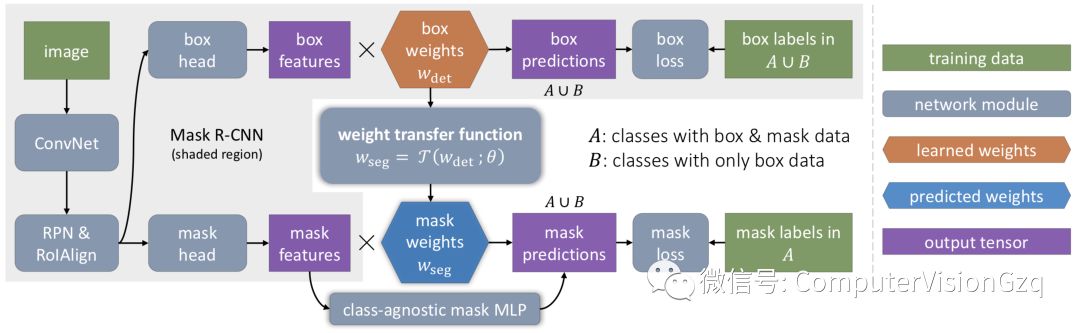
Training
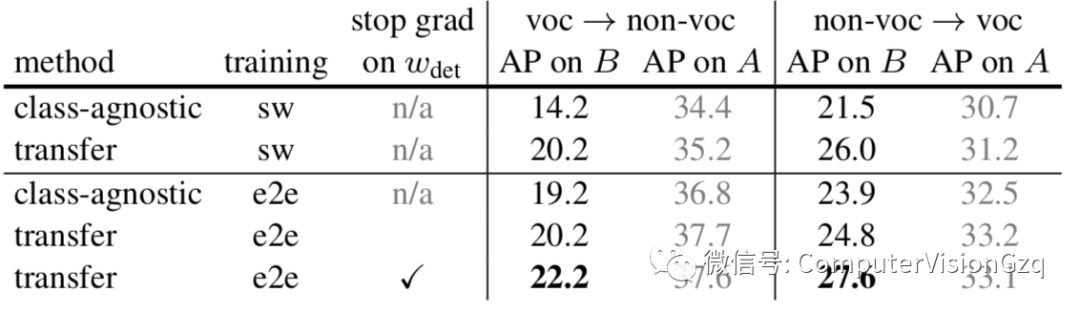
在训练期间,假设对于A和B两组类,instance mask注释仅适用于A中的类,而不适用于B中的类,而A和B中的所有类都有可用的边界框注释。如上图所示,我们使用A∪B中所有类的标准框检测损失来训练边界框head,但只训练mask head和权重传递函数T(·),在A类中使用mask loss,考虑到这些损失,我们探索了两种不同的训练过程:分阶段训练和端到端训练。
分阶段训练
由于Mask R-CNN可以被看作是用mask head增强Faster R-CNN,一种可能的训练策略是将训练过程分为检测训练(第一阶段)和分割训练(第二阶段)。
在第一阶段,只使用A∪B中类的边界框注释来训练一个Faster R-cnn,然后在第二阶段训练附加的mask head,同时保持卷积特征和边界框head的固定。这样,每个c类的类特定检测权重wc可以被看作是在训练第二阶段时不需要更新的固定类emdet层叠向量。
该方法具有很好的实用价值,使我们可以对边界框检测模型进行一次训练,然后对权重传递函数的设计方案进行快速评估。它也有缺点,这是我们接下来要讨论的。
端到端联合训练
结果表明,对于MASK R-CNN来说,多任务训练比单独训练更能提高训练效果。上述分阶段训练机制将检测训练和分割训练分开,可能导致性能低下。
因此,我们也希望以一种端到端的方式,联合训练边界框head和mask head。原则上,可以直接使用A∪B中类的box损失和A中类的mask loss来进行反向传播训练,但是,这可能导致A组和B组之间的类特定检测权重Wc的差异,因为只有c∈A的Wc会通过权重传递函数T(·)从mask loss得到梯度。
我们希望Wc在A和B之间是均匀的,这样在A上训练的预测Wc=T(Wc;θ)可以更好地推广到B。
4
实验
表1 Ablation on input to T
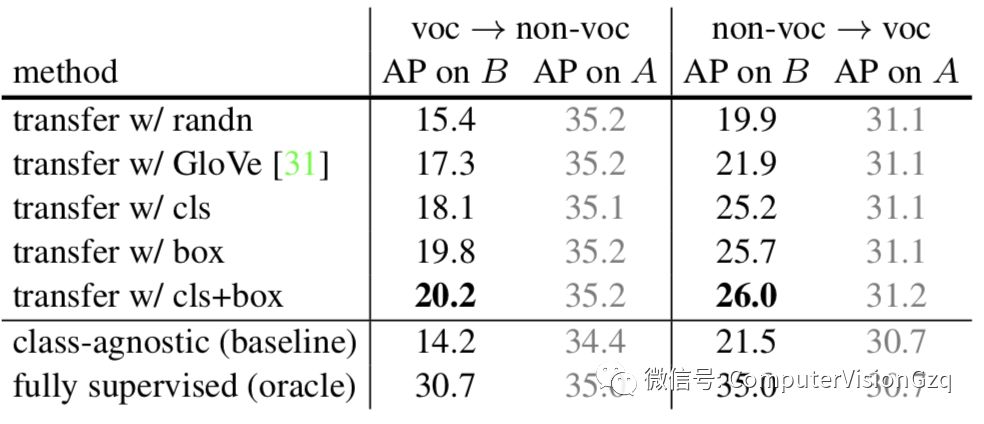
表2 Ablation on the structure of T

表3 Impact of the MLP mask branch

表4 Ablation on the training strategy
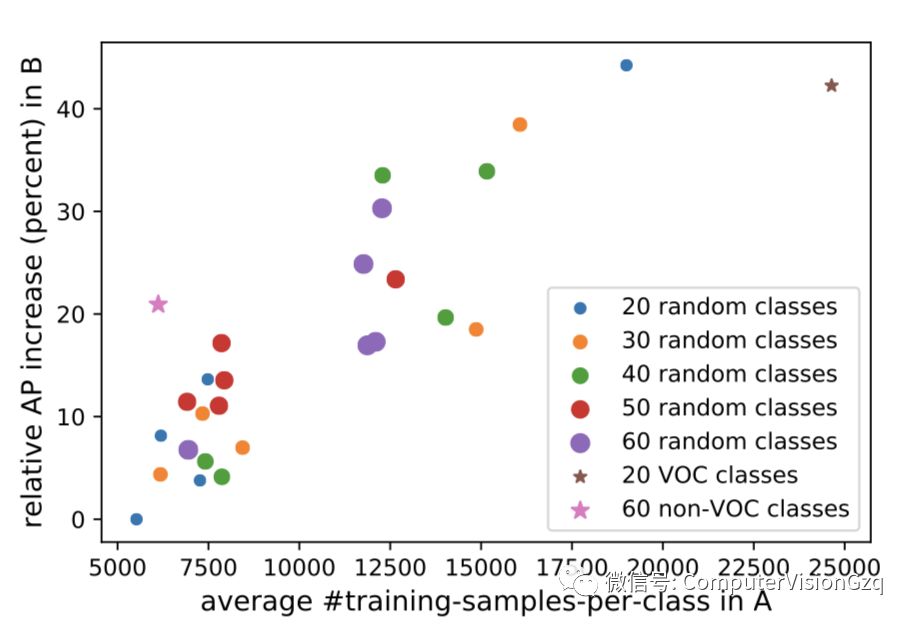
Each point corresponds to our method on a random A/Bsplit of COCO classes.
效果图

Mask predictions from the class-agnostic baseline (top row) vs. our MaskX R-CNN approach (bottom row). Green boxes are classes in set A while the red boxes are classes in set B. The left 2 columns are A = {voc} and the right 2 columns are A = {non-voc}.


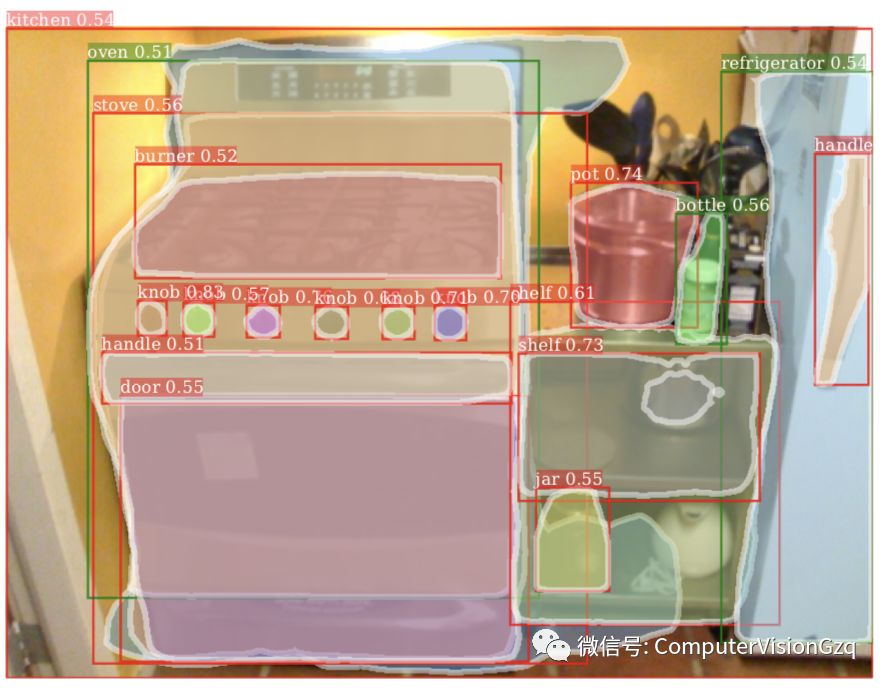
Example mask predictions from our MaskX R-CNN on 3000 classes in Visual Genome. The green boxes are the 80 classes that overlap with COCO (set A with mask training data) while the red boxes are the remaining 2920 classes not in COCO (set B without mask training data). It can be seen that our model generates reasonable mask predictions on many classes in set B. See §5 for details.
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
