
图像分割知识点总结

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
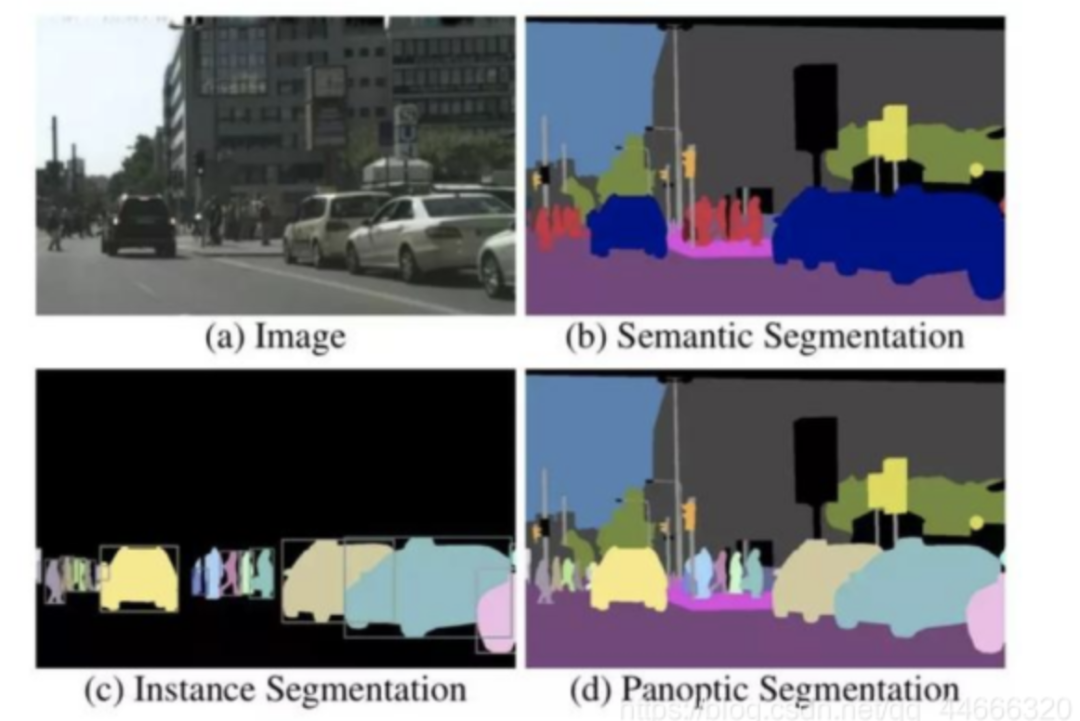
原始图像,(b)语义分割,(c)实例分割和(d)全景分割。
尽管FCN意义重大,在当时来讲效果也相当惊人,但是FCN本身仍然有许多局限。比如:
1)没有考虑全局信息;
2)无法解决实例分割问题;
3)速度远不能达到实时;
4)不能够应对诸如3D点云等不定型数据基于此。
下图给出了部分研究成果与FCN的关系。
2 FCN
目前在图像分割领域比较成功的算法,有很大一部分都来自于同一个先驱:Long等人提出的Fully Convolutional Network(FCN),FCN用卷积层和池化层替代了分类网络中的全连接层,从而使得网络结构可以适应像素级的稠密估计任务。
全连接层转换成卷积层
连接不同尺度下的层
FCN可以与大部分分类网络有效结合,下表中给出了在PASCAL VOC 2011数据库下,FCN与AlexNet、FCN-VGG16和FCN-GoogLeNet结合的结果。
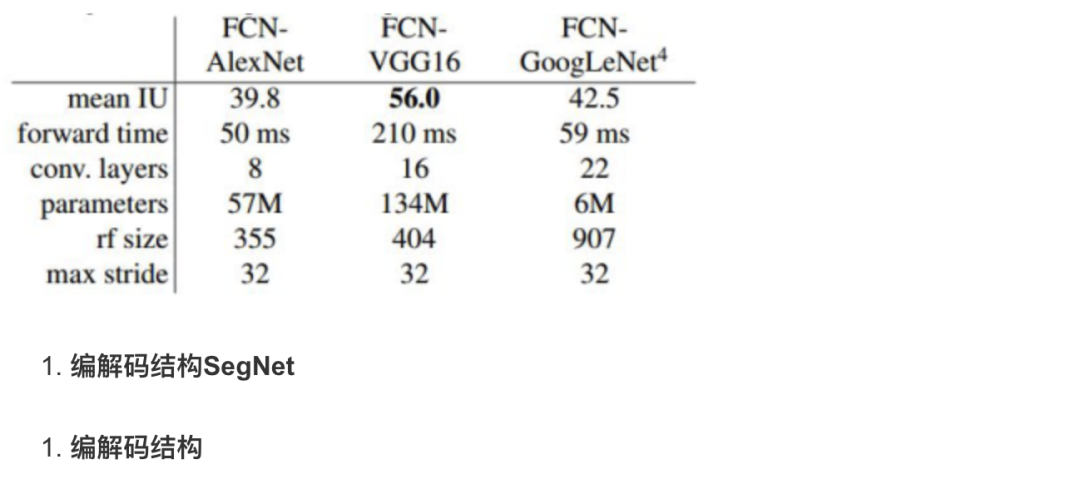
分割任务中的编码器encode与解码器decode;
分割任务中的编码器结构比较类似,大多来源于用于分类任务的网络结构,比如VGG。解码器的不同在很大程度上决定了一个基于编解码结构的分割网络的效果。
2)SegNet
SegNet的编码器结构与解码器结构是一一对应的,即一个decoder具有与其对应的encoder相同的空间尺寸和通道数。对于基础SegNet结构,二者各有13个卷积层,其中编码器的卷积层就对应了VGG16网络结构中的前13个卷积层。SegNet与FCN的对应结构相比,体量要小很多。这主要得益于SegNet中为了权衡计算量而采取的操作:用记录的池化过程的位置信息替代直接的反卷积操作。
3)解码器变体
4、感受野与分辨率的控制术—空洞卷积
1)绪论
分割任务是一个像素级别的任务,因此需要在输入的空间尺寸下对每个像素都有分割的结果。换句话说,如果输入的空间尺寸是HxW,那么输出也需要是HxW的。为了提高网络性能,许多结构采用了池化或striding操作来增加感受野,同时提升远程信息的获取能力。但是这样的结构也带来了空间分辨率的下降。比如之前提到的编解码结构中的编码器。
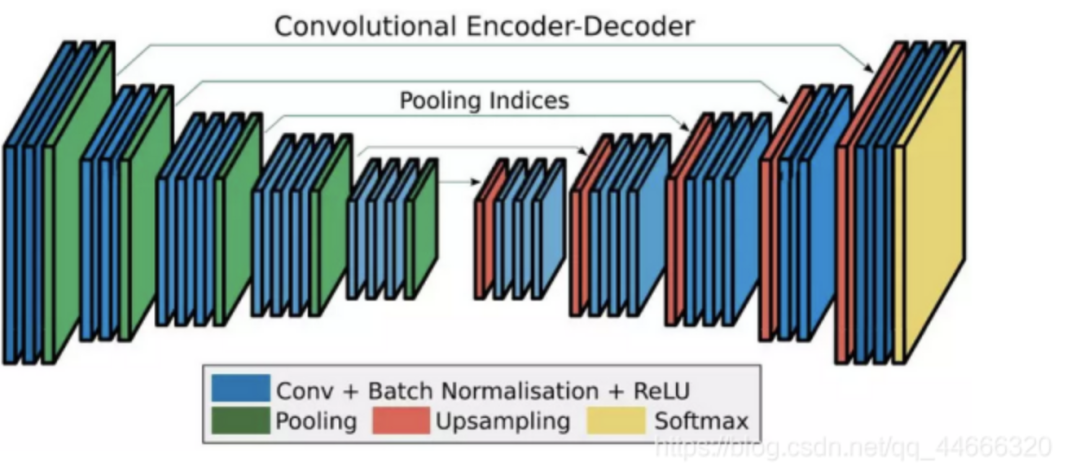
在空洞卷积提出以前,大部分的空间尺寸恢复工作都是由上采样或反卷积实现的。前者通常是通过线性或双线性变换进行插值,虽然计算量小,但是效果有时不能满足要求;后者则是通过卷积实现,虽然精度高,但是参数计算量增加了。
空洞卷积:调整感受野(多尺度信息)的同时控制分辨率的神器。
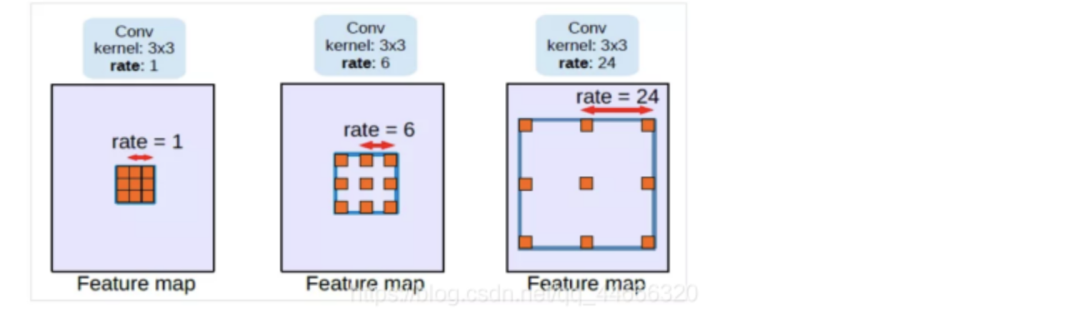
(1) 控制感受野
下图是空洞卷积结构的示意图,从左到右比率(rate)分别为1、6和24,比率可以粗暴理解为卷积核内相邻两个权重之间的距离。从图中可以看出,当比率为1的时候,空洞卷积退化为常见的卷积。
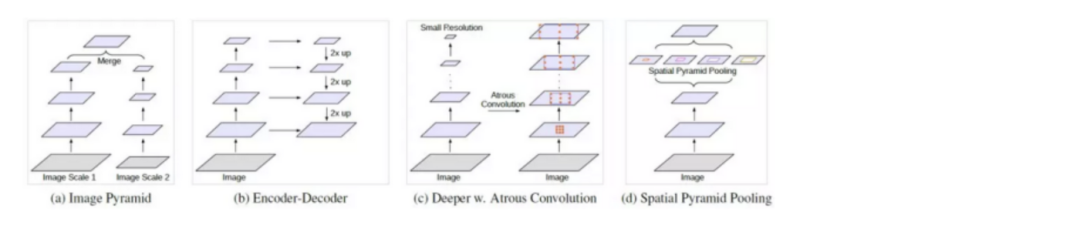
4)实验及分析
(1)卷积核的有效权重
当空洞卷积的区域与特征图实际空间尺寸相近的时候,实际有效的卷积核权重是非常有限的。在极端条件下,当空洞卷积的比率接近特征图空间尺寸时,一个3x3的卷积核就退化成了1x1的卷积核。
为了克服这个问题,DeepLabv3中采用的做法是对最后一层特征图应用全局池化(global pooling),再将其送入一个1x1的卷积层中,最后,通过双线性上采样实现希望的空间分辨率。
(2) 实验总结
DeepLabv3给出了诸多条件下的剥离实验,首先给出整体结论:
输出步长为8时效果比更大的步长要好;
基于ResNet-101的结构比基于ResNet-50的要好;
用变化的比率比1:1:1的比率要好;
加上多尺度输入和左右翻折数据效果更好;
用MS COCO下预训练的模型效果更好。
4、快速道路场景分割—ENet
(1)绪论
虽然深度神经网络在计算机视觉领域的有效性已经是毋容置疑的了,但是大部分神经网络仍然受限于计算量、存储空间、运算速度等因素,无法应用于实际的计算机视觉任务。
以图像分割为例,前面提到的SegNet的速度已经相当快了,但是仍然远不能达到实时分割的目的。比如道路场景分割任务,至少需要达到10fps,而SegNet的速度只能实现1fps左右。
(2) 实时,该考虑什么?
特征图分辨率
为了减小计算量、增大感受野,许多网络都采用缩小特征图分辨率的结构(比如前面提到的SegNet)。但是,过度缩小特征图分辨率则会造成严重的信息丢失,从而造成分割精度的下降。因此,要尽可能约束下采样的比率。目前被广泛接受的下降比率不超过1/8。那么还要继续增大感受野该怎么办呢?没错,就是用到空洞卷积了。
提前下采样
解码器规模
非线性操作
分解卷积层
考虑到卷积层权重其实有相当大的冗余,可以用nx1和1xn的两个卷积层级联(对称卷积)来替代一个nxn的卷积层来缩小计算量。具体地,用n=5的对称卷积的计算量近似于一个3x3的普通卷积,但是由于引入了非线性,这样的操作还能够增加函数的多样性。
(6) 空洞卷积
引入空洞卷积可以减小计算量、增大感受野,同时维护了特征图的分辨率。为了使空洞卷积发挥最大的作用,ENet中穿插地使用了普通卷积、对称卷积和空洞卷积。
(3)网络结构
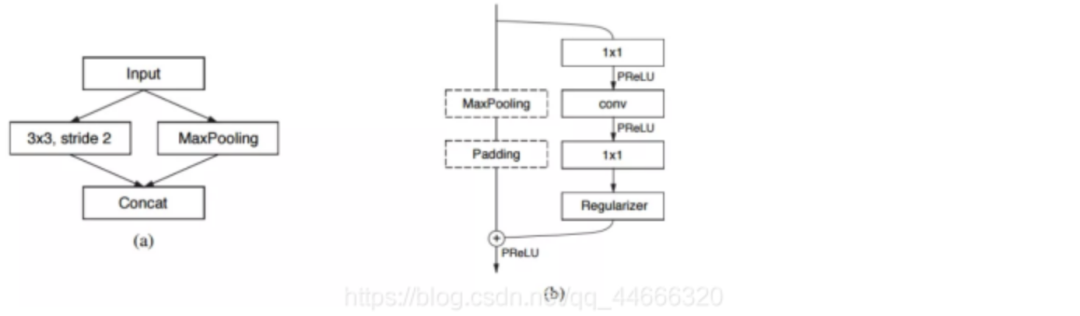
其中,图(a)对应的是ENet的初始模块,也就是前文提到的缩小输入图像分辨率,从而去除视觉冗余、减小计算量的部分;图(b)对应的则是重复使用,从而构建网络主体的bottleneck模块。
5、以RNN形式做CRF后处理—CRFasRNN
(1)条件随机场(CRF或CRFs)与隐马尔科夫模型有着千丝万缕的联系。
马尔科夫链是指具有马尔可夫性质且存在于离散指数集合状态空间内的随机过程,之前走过的每一步之间是条件独立的,即上一步走的方向不会影响这一步的方向。由于存在的选择只有四个(举例:上下左右),即选择离散,所以我们称这个过程为马尔科夫链。当选择连续时,称为马尔科夫过程(Markov Process)。
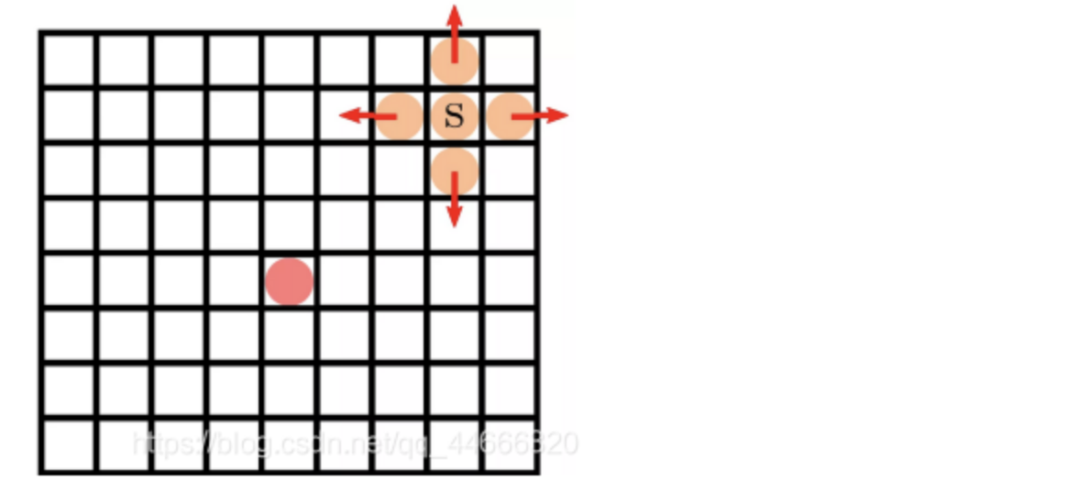
(2)
隐式马尔科夫模型(HMM,Hidden Markov Model)是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成的不可观测的状态随机序列,再由各个状态生成一个观测而产生观测序列的过程。隐藏的部分称为状态序列;生成的观测组成的随机序列称为观测序列。
什么是CRF?
CRF是一种判别式概率模型,是随机场的一种,结合了最大熵模型和隐式马尔科夫模型的特点;CRF是一种无向图模型,图中的顶点代表随机变量,顶点间的连线代表随机变量间的相依关系。其条件概率分布模型可以表述为P(Y|X),即给定一组随机变量的条件下,随机变量Y的马尔科夫随机场(MRF,Markov Random Field)。
(3)网络结构
那么,如果用一个FCN模型完成第一阶段的分割任务,用RNN形式的CRF完成第二阶段的后处理(CRF-RNN),则可以搭建如下形式的端到端分割网络结构模型:
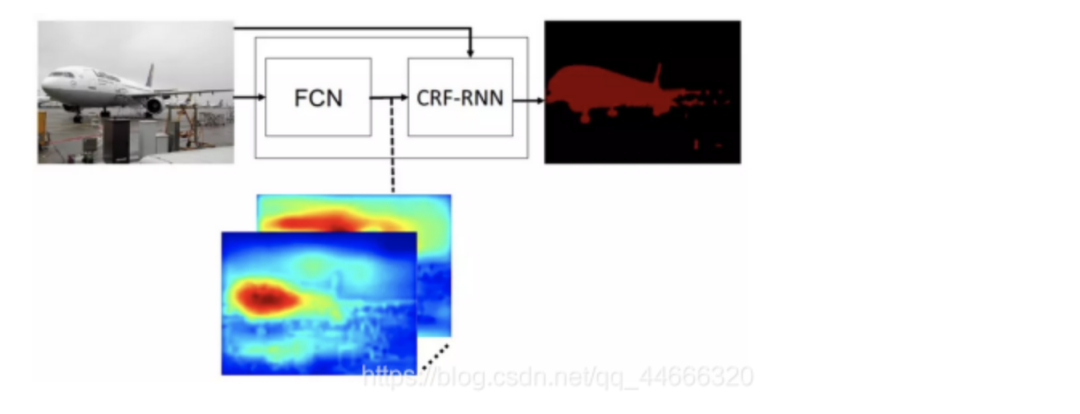
6、多感受野的金字塔结构—PSPNet
(1)为什么要用金字塔结构提取特征
由于金字塔结构并行考虑了多个感受野下的目标特征,从而对于尺寸较大或尺寸过小的目标有更好的识别效果。
(2)金字塔池化模型
下图是论文中提出的基于金字塔池化模型的网络结构。其中,虚线框出来的部分属于金字塔池化模型。
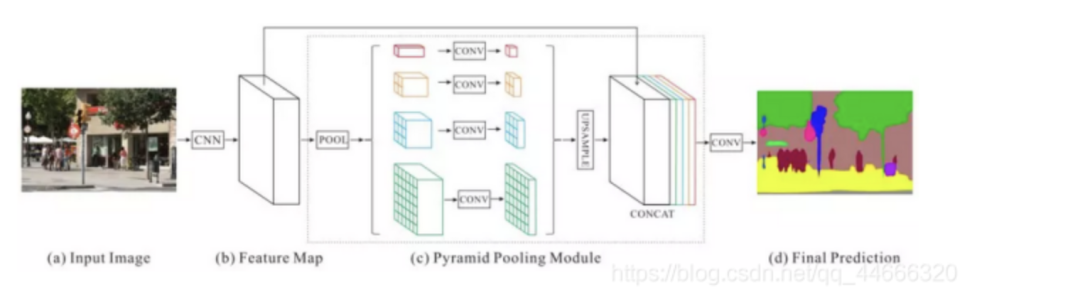
实验中分别用了1x1、2x2、3x3和6x6四个尺寸,最后用1x1的卷积层计算每个金字塔层的权重,再通过双线性恢复成原始尺寸。
最终得到的特征尺寸是原始图像的1/8。最后在通过卷积将池化得到的所有上下文信息整合,生成最终的分割结果。
7、全局特征与局部特征的交响曲—ParseNet
(1)理论感受野是真的吗?
大家已经能够体会到感受野对于分割网络效果的影响有多么巨大了。简单来说,感受野越大,网络所能“看见”的区域就越大,从而能够用于分析的信息就更多。由此,分割的效果也很有可能更好。
基于这种考虑,许多算法尝试通过改变自身网络结构设计来增大网络的理论感受野,认为这样就能够为网络带来更多的信息。尽管理论感受野的增大的确能够增加网络所获取的上下文信息,但是,理论感受野难道真的就代表了算法实际看见的区域吗?
网络实际上能够覆盖的区域也就能达到整图的1/4左右,远远没有达到理论感受野的尺寸。那么究竟该如何利用全部的图像上下文信息呢?ParseNet提出了一种融合全局信息与局部信息的方法,下面来具体介绍一下。
(2)全局特征的提取与融合
如下图所示,ParseNet通过全局池化提取图像的全局特征,并将其与局部特征融合起来。这种融合在过程中需要考虑两个主要问题:融合的时机与尺度的归一化。
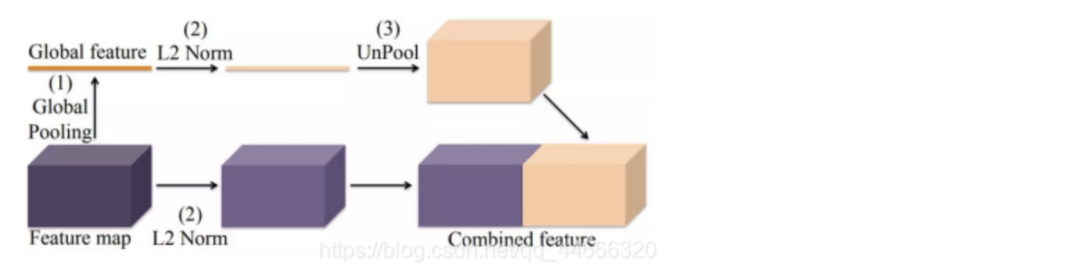
融合时机
全局特征与局部特征的融合可以发生在两个节点:分别是训练分类器之前(early fusion)和训练分类器之后(late fusion)。其中,前者是将两个特征融合后,作为一个整体共同送入分类网络,训练分类器;后者则是以两个特征为输入,分别训练其对应的分类器,最后再将分类的结果整合。
归一化
8、多分辨率特征融合—RefineNet
(1)恢复空间分辨率
在分割任务中,为了提取更复杂的特征、构建更深的神经网络,许多算法往往会以牺牲空间分辨率的方式,在尽量少地增加计算量的前提下,换取特征通道数的增加。虽然这种方式有诸多优点,但是也有一个明显的缺陷——空间分辨率的下降。
下面我们具体聊一下RefineNet的网络结构和设计思想。
(2)全局特征的提取与融合
RefineNet总共包括三大模块:残差卷积模块(RCU,Residual Convolution Unit)、多分辨率融合模块(Multi-Resolution Fusion)和串联残差池化模块(Chained Residual Pooling)。
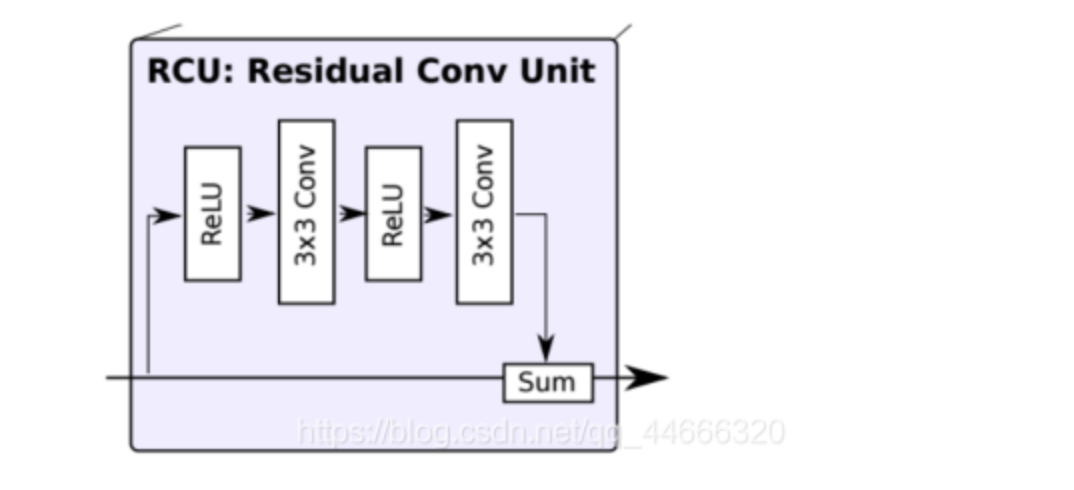
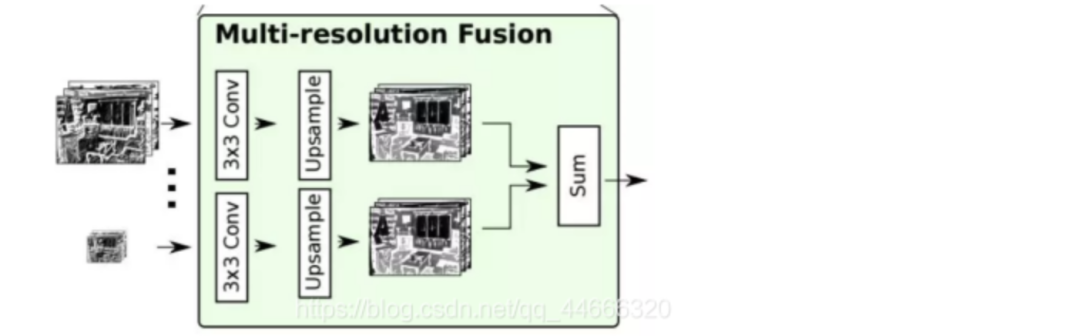
在给定了多分辨率下经过处理的分割结果后,各个结果将依次通过一个卷积层和一个上采样层,形成空间分辨率统一的分割结果图。
具体而言,网络首先通过一个卷积层处理输入进来的不同分辨率下的分割结果,从而学习得到各通道下的适应性权重。随后,应用上采样,统一所有通道下的分割结果,并将各通道结果求和。求和结果送入下一个模块。
串联残差池化
下图是这一模块的结构图:
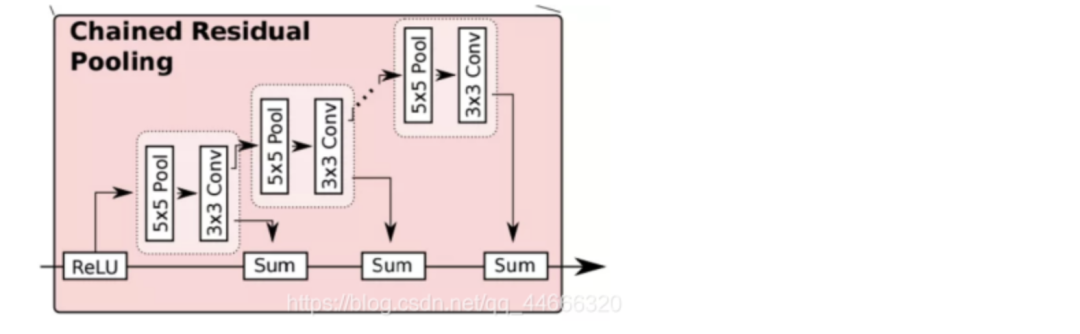
这个模块主要由一个残差结构、一个池化层和一个卷积层组成。其中,池化层加卷积层用来习得用于校正的残差。值得注意的是,RefineNet在这里用了一个比较巧妙的做法:用前一级的残差结果作为下一级的残差学习模块的输入,而非直接从校正后的分割结果上再重新习得一个独立的残差。
这样做的目的,RefineNet的作者是这样解释的:可以使得后面的模块在前面残差的基础上,继续深入学习,得到一个更好的残差校正结果。
最后,网络又经过一个一个RCU模块,平衡所有的权重,最终得到与输入空间尺寸相同的分割结果。
(3)网络结构变种
单个RefineNet
2次级联的RefineNet
4次级联2倍RefineNet
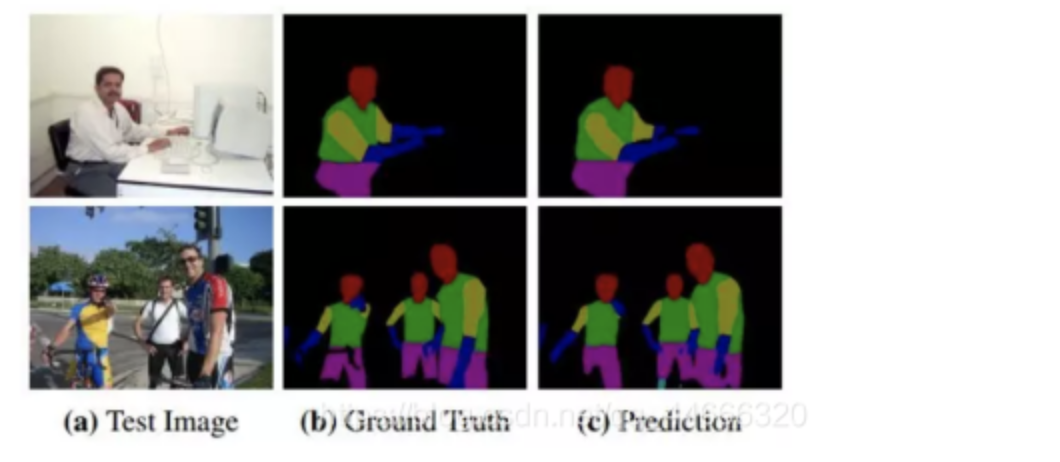
除了语义分割,RefineNet还可以用于目标理解(object parsing)。下图是RefineNet在目标理解上的直观结果:
9、用BRNN做分割—ReSeg
(1)简单说说BRNN
什么是循环神经网络?
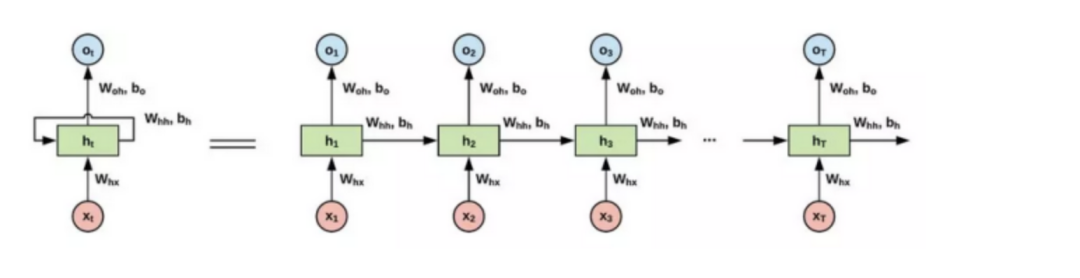
不同于卷积神经网络(CNN,Convolutional Neural Network)通常以图块(patches)为输入,循环神经网络(RNN,Recurrent Neural Network)的输入是序列形式的。即使在处理图像时,通常也需要对图像矩阵进行展开(flatten)操作,再应用RNN。输入序列数据后,RNN在序列的演进方向递归所有节点,并将其定向链式连接。
下图是一个简单的RNN单元示意图:
为什么要用RNN?
什么是BRNN?
BRNN是双向循环神经网络(Bi-directional RNN)的缩写,属于循环神经网络的一种。基础RNN只能依据之前时刻的时序信息来预测下一时刻的输出,但是有些问题中需要联系上之前和未来状态,共同进行预测。BRNN由两个方向不同的RNN堆叠而成,同时处理过去和未来信息。下图是BRNN的示意图:
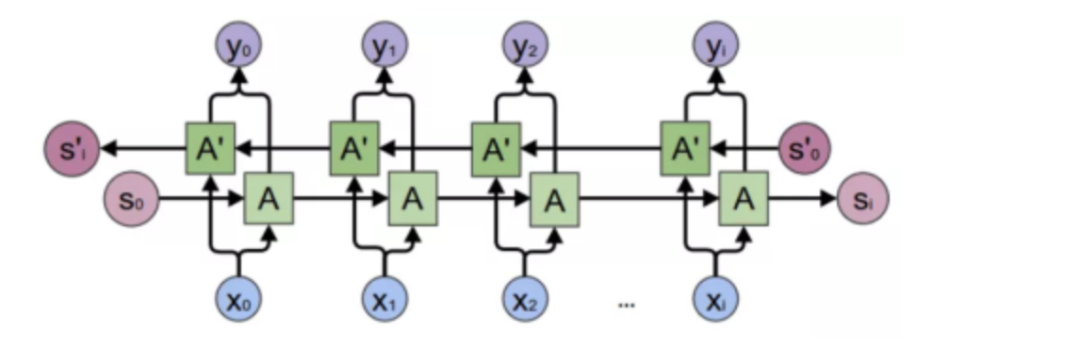
(2)ReSeg:用BRNN做分割
ReSeg是基于图像分割模型ReNet提出的。因此,我们首先来看一下ReNet。
10、BRNN下的RGB-D分割—LSTM-CF
(1)RGB-D分割
RGB-D分割中的D指的是“Depth”,即“深度”,也就是相机到物体在实际空间中的距离。
引入深度信息后,其提供的额外结构信息能够有效辅助复杂和困难场景下的分割。比如,与室外场景相比,由于语义类别繁杂、遮挡严重、目标外观差异较大等原因,室内场景的分割任务要更难实现。此时,在结合深度信息的情况下,能够有效降低分割的难度。
11、实例分割模型—DeepMask
(1)实例分割
实例分割任务有其自己的任务需求与度量矩阵。简单来讲,语义分割只分割视野内目标的类型,而实例分割则不仅分割类型,同时还需要分割同类型的目标是否为同一个实例。
(2)DeepMask
DeepMask网络其实实现了三个任务:前背景分割、前景语义分割与前景实例分割。这三个任务是基于同一个网络结构进行的,只是各自有单独的分支。下图是DeepMask的网络模型概况:
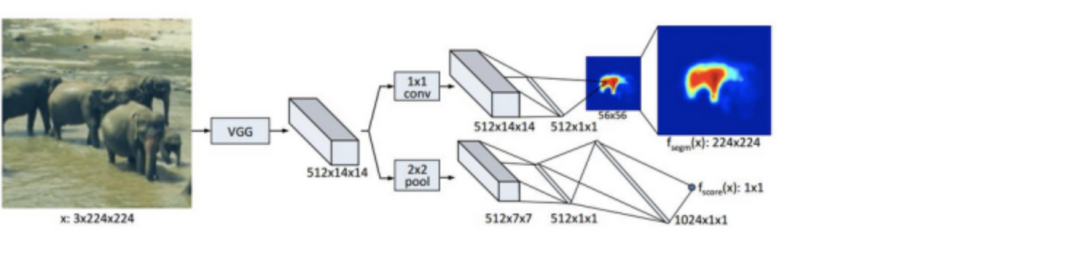
与大部分分割网络相同,DeepMask同样应用了VGG模型作为特征提取的主要模块,在训练中也用了ImageNet下训练得到的VGG参数初始化这一部分模型。DeepMask用两条分支来分别实现分割任务和前景目标识别任务。
分割部分
分割部分要实现的是对图块内场景的类别的识别,由一个1x1卷积层后接分类层实现。这里的分类是稠密的,也就是对每一个像素都有其对应的标注。
前景Score部分
网络的第二个分支要完成的任务是,判断一个图块是否满足下面两个要求:
目标位于图块的正中心附近
目标完整存在于图块中(在某一尺度范围内)
12、全景分割是什么?
(1)全景分割
与之前介绍的语义分割与实例分割不同,全景分割任务(Panoptic Segmentation)要求图像中的每个像素点都必须被分配给一个语义标签和一个实例id。其中,语义标签指的是物体的类别,而实例id则对应同类物体的不同编号。
全景分割的实现也面临着其他难题。比如,与语义分割相比,全景分割的困难在于要优化全连接网络的设计,使其网络结构能够区分不同类别的实例;而与实例分割相比,由于全景分割要求每个像素只能有一个类别和id标注,因此不能出现实例分割中的重叠现象。

全景分割的具体分割形式有以下两点要求:
图像中的每个像素点都有一个对应的语义类别和一个实例id,如果无法确定可以给予空标注。
所有语义类别要么属于stuff,要么属于things,不能同时属于二者;且stuff类别没有实例id(即id统一为一个)。
全景分割与语义分割的关系:
如果所有的类别都是stuff,那么全景分割除了度量与语义分割不同外,其它相同。
全景分割与实例分割的关系:
全景分割中不允许重叠,但实例分割可以;此外,实例分割需要每个分割的置信概率,但全景分割不需要。尽管如此,全景分割内为了辅助机器的辨识,也是可以引入置信概率的概念的。
(2)度量矩阵
为了将stuff类别和things类别统一在一个分割任务下,全景分割的度量应当具有以下三个性质:
完整性:对stuff和things类别一视同仁,包含任务中的所有方面。
可解释性:度量需要具有能够可定义、可理解、可交流的性质。
简单:有效的度量应当简洁、可复现。
基于此,全景分割的度量被分为了分割匹配(segment matching)和全景质量计算(panoptic quality computation)两个部分。
分割匹配:要求IoU(Intersection over Union)严格大于0.5才算匹配,且不可以有重叠区域,限制一个像素只能对应一个标签。
全景质量计算:对每个类别的全景分割质量的单独计算结果取平均,从而保证分割结果对类别不敏感。
原文地址
https://blog.csdn.net/qq_44666320/article/details/106620594
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx