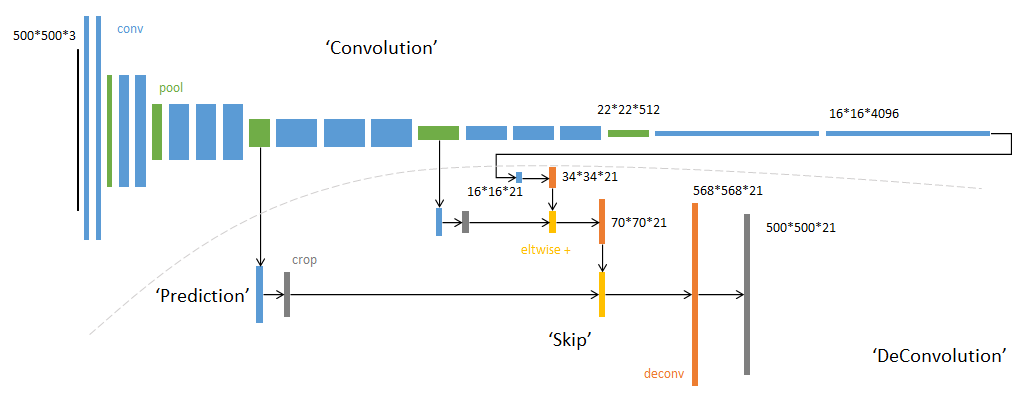
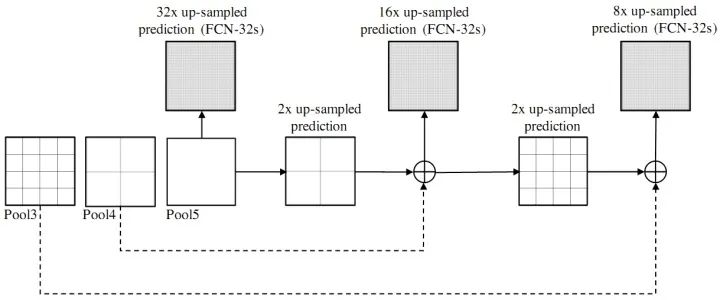
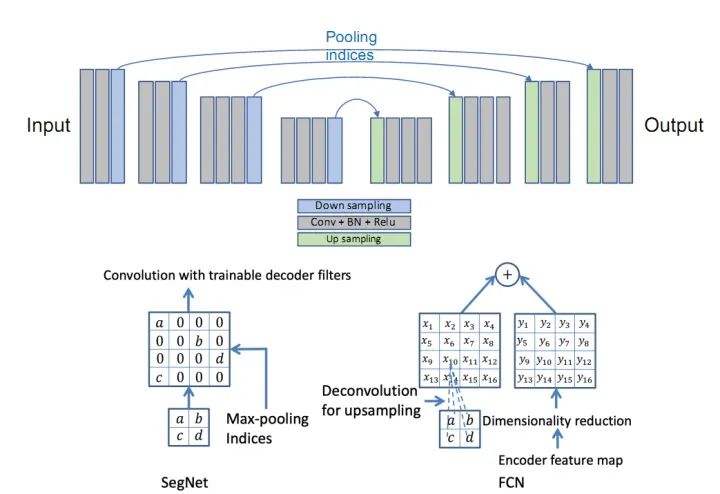
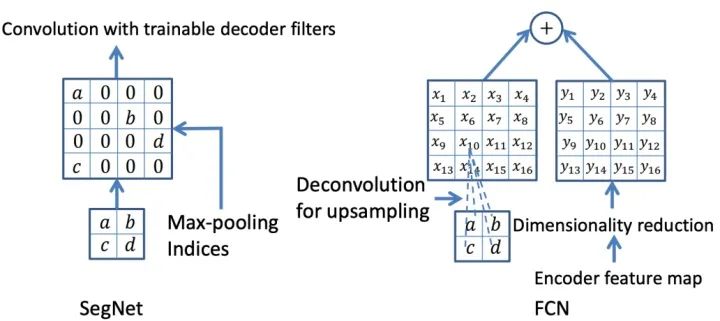
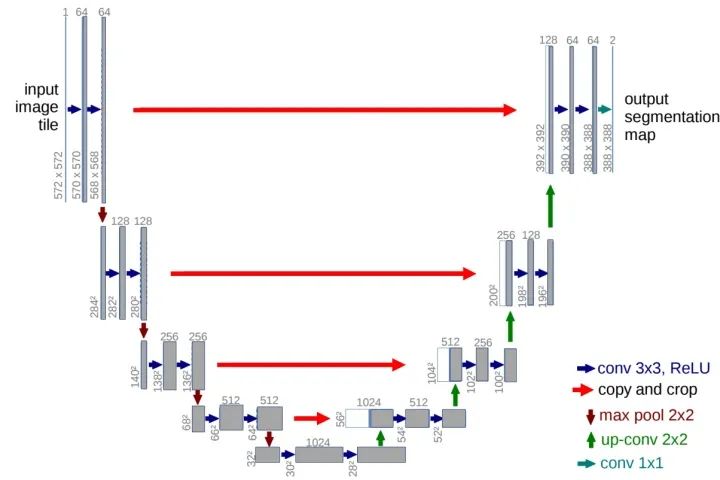
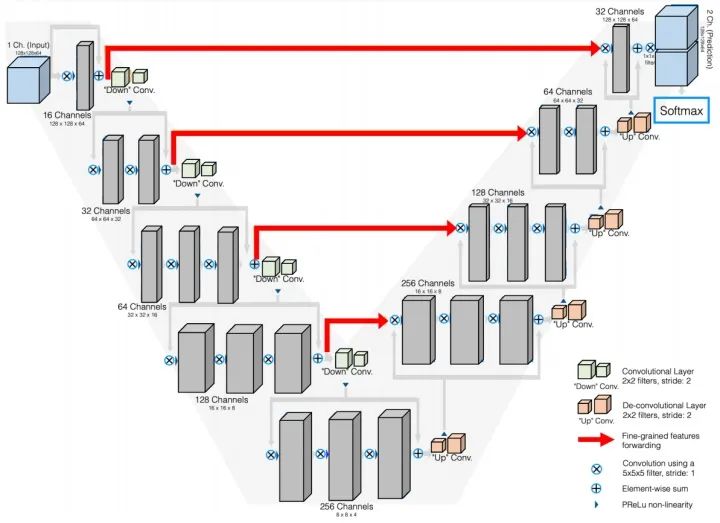
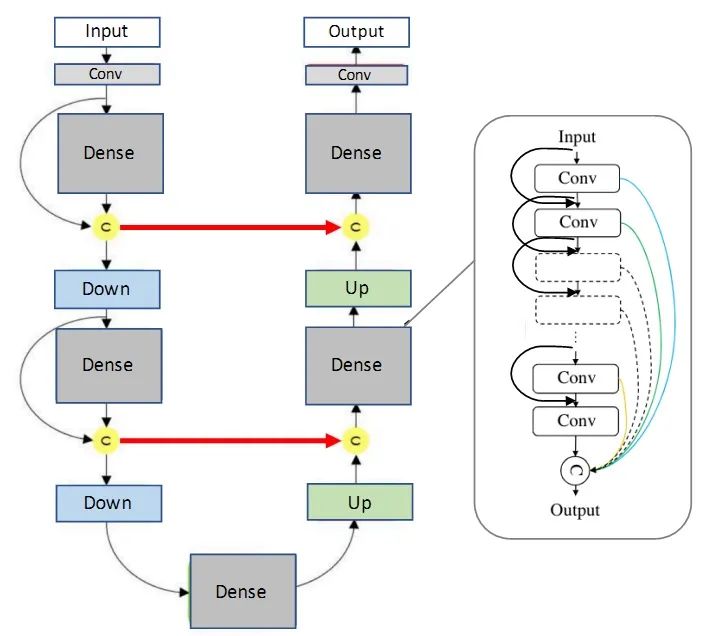
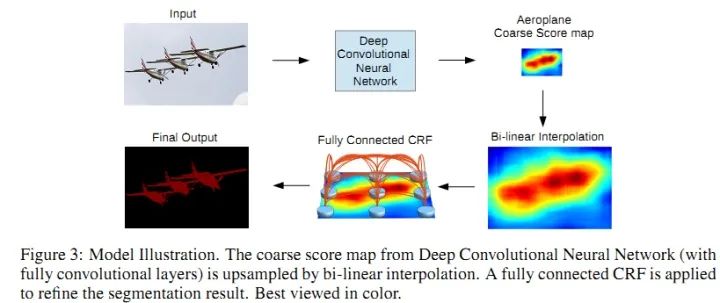
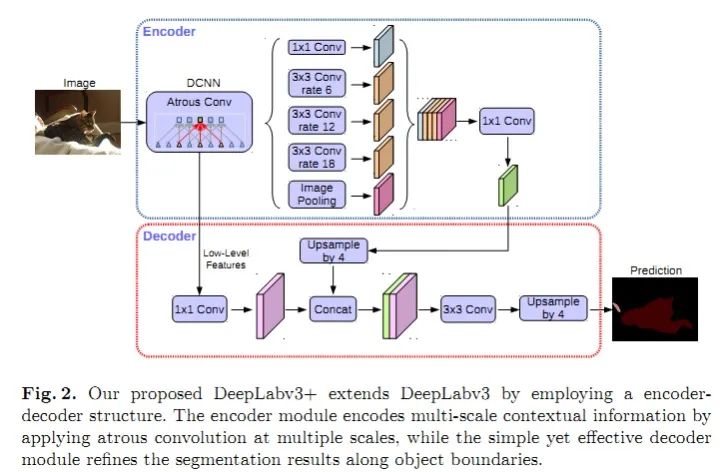
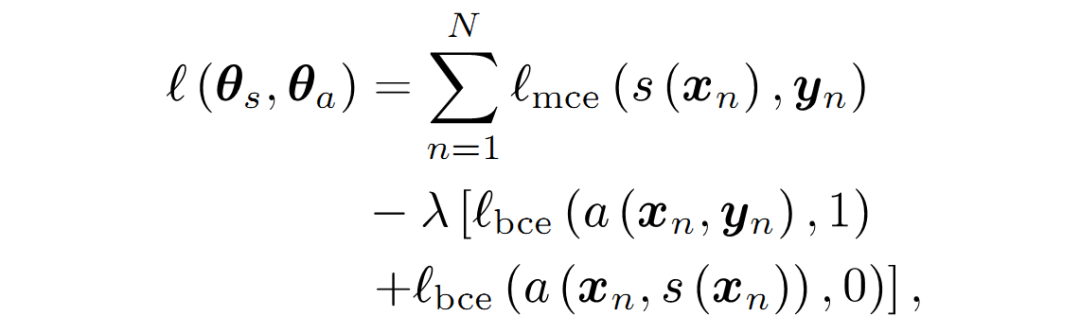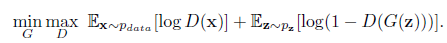SegNet和FCN网络的思路基本一致。编码器部分使用VGG16的前13层卷积,不同点在于Decoder部分Upsampling的方式。FCN通过将特征图deconv得到的结果与编码器对应大小的特征图相加得到上采样结果;而SegNet用Encoder部分maxpool的索引进行Decoder部分的上采样(原文描述:the decoder upsamples the lower resolution input feature maps. Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling.)。
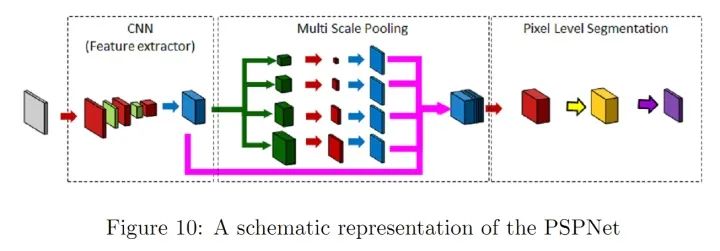
PSPNet(pyramid scene parsing network)通过对不同区域的上下文信息进行聚合,提升了网络利用全局上下文信息的能力。在SPPNet,金字塔池化生成的不同层次的特征图最终被flatten并concate起来,再送入全连接层以进行分类,消除了CNN要求图像分类输入大小固定的限制。而在PSPNet中,使用的策略是:poolling-conv-upsample,然后拼接得到特征图,然后进行标签预测。
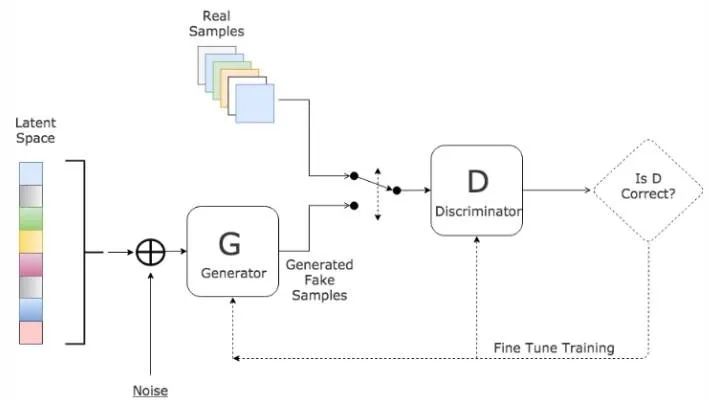
这部分介绍一些网络结构创新在2D/3D医学图像分割中的应用研究成果。2.1 基于模型压缩的分割方法为了实现实时处理高分辨率的2D/3D医学图像(例如CT、MRI和组织病理学图像等),研究人员提出了多种压缩模型的方法。weng等人利用NAS技术应用于U-Net网络,得到了在CT,MRI和超声图像上具有更好的器官/肿瘤分割性能的小型网络。Brugger通过利用组归一化(group normalization )和Leaky-ReLU(leaky ReLU function),重新设计了U-Net架构,以使网络对3D医学图像分割的存储效率更高。也有人设计了参数量更少的扩张卷积module。其他一些模型压缩的方法还有权重量化(十六位、八位、二值量化)、蒸馏、剪枝等等。2.2 编码-解码结构的分割方法Drozdal提出了一种在将图像送入分割网络之前应用简单的CNN来对原始输入图像进行归一化的方法,提高了单子显微镜图像分割、肝脏CT、前列腺MRI的分割精度。Gu提出了在主干网络利用扩张卷积来保留上下文信息的方法。Vorontsov提出了一种图到图的网络框架,将具有ROI的图像转换为没有ROI的图像(例如存在肿瘤的图像转换为没有肿瘤的健康图像),然后将模型去除的肿瘤添加到新的健康图像中,从而获得对象的详细结构。Zhou等人提出了一种对U-Net网络的跳跃连接重新布线的方法,并在胸部低剂量CT扫描中的结节分割,显微镜图像中的核分割,腹部CT扫描中的肝脏分割以及结肠镜检查视频中的息肉分割任务中测试了性能。Goyal将DeepLabV3应用到皮肤镜彩色图像分割中,以提取皮肤病变区域。2.3 基于注意力机制的分割方法Nie提出了一种注意力模型,相比于baseline模型(V-Net和FCN),可以更准确地分割前列腺。SinHa提出了一种基于多层注意力机制的网络,用于MRI图像腹部器官分割。Qin等人提出了一个扩张卷积模块,以保留3D医学图像的更多细节。其他基于注意力机制的啼血图像分割论文还有很多。2.4 基于对抗学习的分割网络Khosravan提出了从CT扫描中进行胰腺分割的对抗训练网络。Son用生成对抗网络进行视网膜图像分割。Xue使用全卷积网络作为生成对抗框架中的分割网络,实现了从MRI图像分割脑肿瘤。还有其他一些成功应用GANs到医学图像分割问题的论文,不再一一列举。2.5 基于RNN的分割模型递归神经网络(RNN)主要用于处理序列数据,长短期记忆网络(LSTM)是RNN的一个改进版本,LSTM通过引入自环(self-loops)使得梯度流能长期保持。在医学图像分析领域,RNN用于对图像序列中的时间依赖性进行建模。Bin等人提出了一种将全卷积神经网络与RNN融合的图像序列分割算法,将时间维度上的信息纳入了分割任务。Gao等人利用CNN和LSTM拉对脑MRI切片序列中的时间关系进行建模,以提高4D图像中的分割性能。Li等人先用U-Net获得初始分割概率图,后用LSTM从3D CT图像中进行胰腺分割,改善了分割性能。其他利用RNN进行医学图像分割的论文还有很多,不再一一介绍。2.6 小结这部分内容主要是分割算法在医学图像分割中的应用,所以创新点并不多,主要还是对不同格式(CT还是RGB,像素范围,图像分辨率等等)的数据和不同部位数据的特点(噪声、对象形态等等),经典网络需要针对不同数据进行改进,以适应输入数据格式和特征,这样能更好的完成分割任务。虽然说深度学习是个黑盒,但整体上模型的设计还是有章可循的,什么策略解决什么问题、造成什么问题,可以根据具体分割问题进行取舍,以达到最优的分割性能。部分参考文献:1 Deep Semantic Segmentation of Natural and Medical Images: A Review2 NAS-Unet: Neural architecture search for medical image segmentation. IEEE Access, 7:44247–44257, 2019.3 Boosting segmentation with weak supervision from image-to-image translation. arXiv preprint arXiv:1904.01636, 20194 Multi-scale guided attention for medical image segmentation. arXiv preprint arXiv:1906.02849,2019.5 SegAN: Adversarial network with multi-scale L1 loss for medical image segmentation.6 Fully convolutional structured LSTM networks for joint 4D medical image segmentation. In 2018 IEEE7 https://www.cnblogs.com/walter-xh/p/10051634.html