
独家 | 为什么在CV(视觉识别)领域,Transformers正在缓慢逐步替代CNN?

作者:Pranoy Radhakrishnan 翻译:wwl
校对:王可汗
本文约3000字,建议阅读10分钟 本文讨论了Transformer模型应用在计算机视觉领域中和CNN的比较。
在认识Transformers之前,思考一下,为什么已经有了MLP、CNN、RNN,研究者还会对Transformers产生研究的兴趣。
Transformers起初是用于语言翻译。相比于循环神经网络(比如LSTM),Transformers支持模拟输入序列元素中的长依赖,并且支持并行处理序列。
Transformers利用同一个处理模块,可以支持处理不同类型的输入(包括图像、视频、文本、语音)。每个人都希望解决不同的问题都能有统一的模型,并且兼顾准确性和速度。和MLPs有通用的函数近似器一样,transfomers模型在sequence-to-sequence问题上,有通用的解决函数。
Transformers应用了注意力机制,首先我们学习注意力机制和自注意力机制。
注意力机制
注意力机制的作用是提高输入数据中关键部分的重要性,降低其余部分的重要性。就像是你理解一个图片的时候,你会聚焦在图像中有意义的相关部分。注意力机制也是这样做的。
但是为什么我们需要注意力机制?毕竟CNNs已经在图像特征提取上表现得很好了,不是吗?
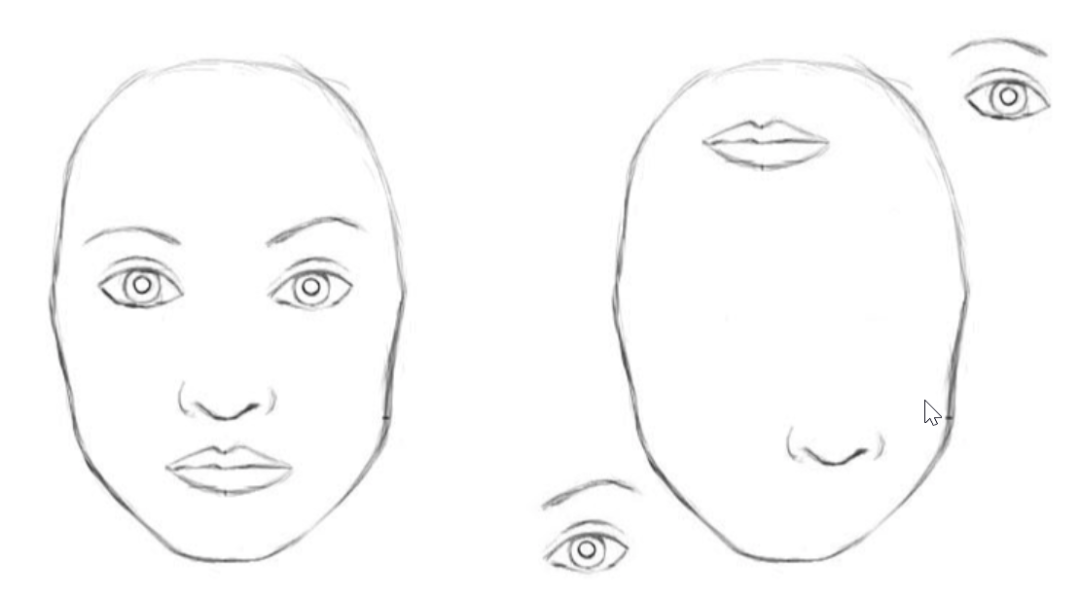
对于一个CNN,输入的每个图片都是一样的操作。CNN不会对不同特征的相对位置进行编码。如果想要对这些特征组合进行编码,则需要大的卷积核。举例来说,编码鼻子和嘴巴上边的眼睛这个信息,需要大的卷积核。
在一个图片里,如果要捕捉较大范围的依赖关系的话,是需要大的感受野。提高卷积核的尺寸可以提高模型的表达能力,但这样做也会失去使用局部卷积结构获得的计算和统计效率。
自注意力机制是注意力机制的一种,和CNN结合可以帮助拟合长距离的依赖关系且不以牺牲计算效率和统计效率为代价。自注意力模块是卷积的补充,有助于在图像区域内拟合远距离、多层次的依赖关系。
你可以看到,自注意力模块替代了卷积层,现在模型中每个位置点可以和远距离的像素点有相关关系。
在最近的一项研究中,研究者执行了一系列ResNets实验,分别用注意力模块替代部分和全部的卷积层,结果显示模型效果最好的实验是在浅层用卷积层,在深层用注意力层。
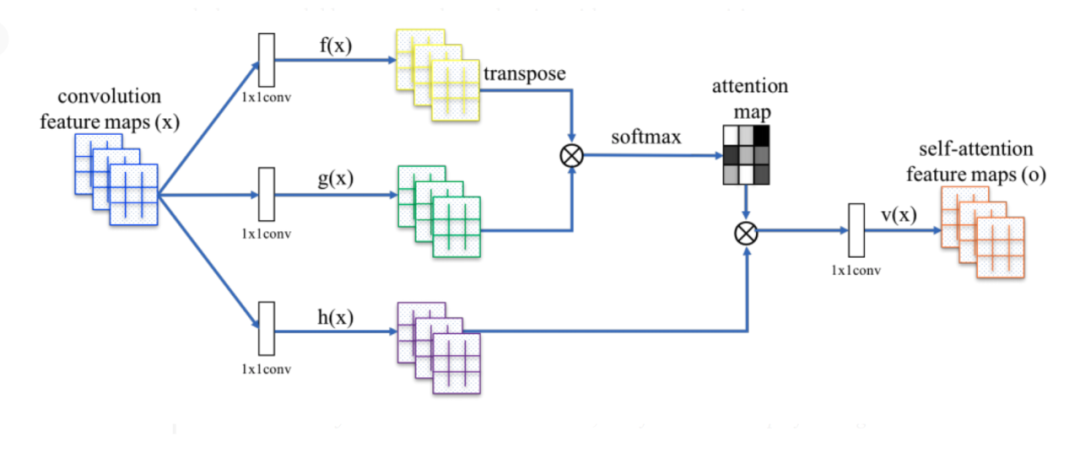
自注意力
自注意力机制是注意力机制的一种,作用是序列中的每个元素和序列中其他元素有交互,并发现应该更关注其他元素中的哪个。
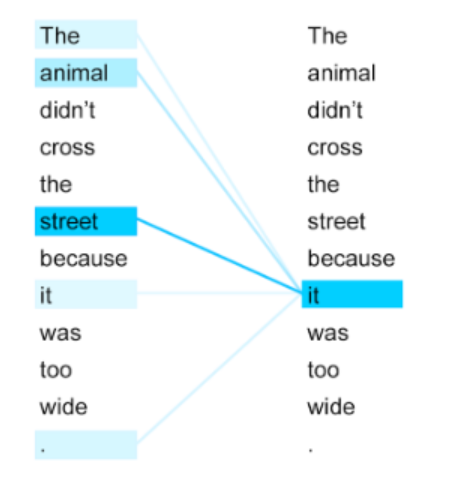
自注意力的目标是捕捉所有实体的关系,是一个所有词向量的带权重的组合,可以捕捉序列中元素之间的长范围的信息和依赖关系。
从上图可以看到,“it”指代的是“street”,而不是“animal”。自注意力是其他词向量的带权重的组合。这里“it”的词向量是其他词向量的加权的组合,其中单词“street”的权重更高。
如果想深入理解权重是如何得到的,参考这个视频:
https://www.youtube.com/watch?v=tIvKXrEDMhk
根本上,一个自注意力层会对输入序列中的每个元素进行更新,更新的方式是对完整的输入序列中的全部信息进行整合。
因此,我们已经了解了像自注意这样的注意力机制如何有效地解决卷积网络的一些局限性。现在是否有可能用像Transformers这样的基于注意力的模型完全取代CNN?
在NLP领域,Transformers已经取代了LSTM。那么在计算机视觉领域,Transfomers可以取代CNN吗?接下来我们深入了解下,在哪些方面,注意力的方法超越了CNN。
Transformer 模型
Transformer模型最初是用来解决自然语言处理中的翻译问题,包含encoder-decoder的模型结构。图片中左边表示编码器,右边表示解码器。编码器和解码器中都包含自注意力机制、线性层和剩余的全连接层。
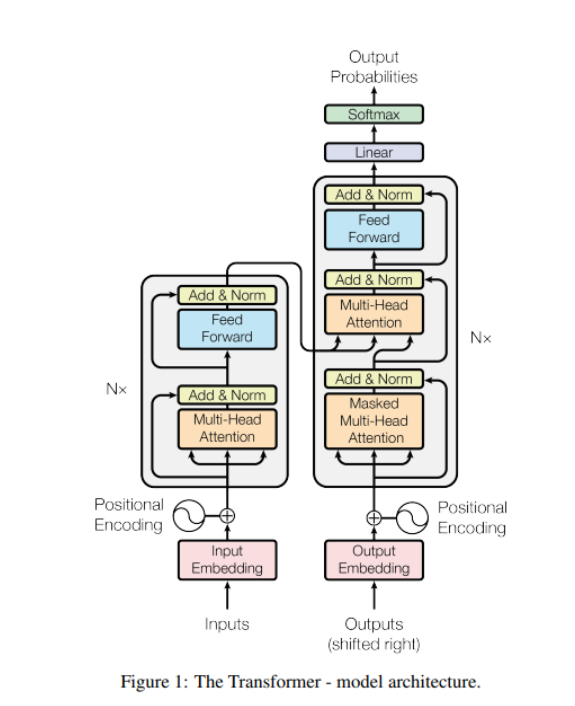
编码器
以翻译为例,编码其中的自注意力是帮助输入序列中的words产生交互,从而对每个word产生一个包含和序列中其他word的语义相似性的特征表示。
解码器
解码器的工作是一次输出一个已翻译的单词,基于到目前为止生成的输入词嵌入和输出。
解码器输出翻译后的单词,是通过对编码器的输出中的特定部分以及对之前解码器的输出。为了确保编码器只用到了已经生成的之前的输出,不包含训练中未来的输出。Mask Self Attention机制用于解码器。它只是掩盖了训练期间解码器输入给出的未来单词。
自注意力并不关心位置。比如说,这个句子“Deepak is the son of Pradeep”,对于单词“son”,自注意力会给单词“Deepak”更多权重。如果我们顺序改变得到,“Pradeep is the son of Deepak”,对单词“son”,自注意力还是会给单词”Deepak”更多权重,但其实这里我们希望如果句子中单词顺序改变,对单词“son”来说,自注意力机制可以给“Pradeep”更多权重。
这是因为,编码单词“son”的时候,自注意力机制是对其他所有单词的词向量进行了加权组合且不考虑位置关系。所以打乱句子中的单词顺序并不会有任何不同。换句话说自注意力机制是位置无关的。除非,在把子向量输入自注意力模块之前,给每个单词增加了位置信息。
Vision Transformer
Vision Transformer是用Transformer替换卷积层。
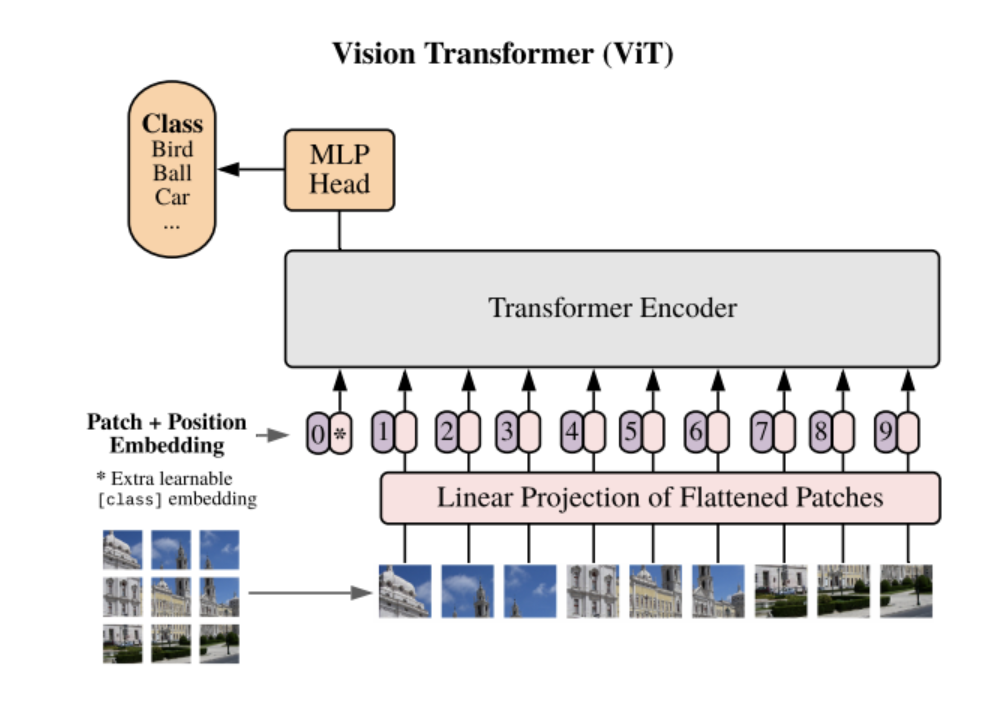
图 Vision Transformer
Transformer一般是应用在序列数据中,因此我们把图片切分成图像块(patches),然后把每个patch展开为一个向量。从现在开始,我会把这个图像块称为一个元素(token),因此我们现在就得到了一个由这样的元素构成的序列。
自注意力机制是位置无关(permutation invariance)的。它对不同注意力向量的加权求和是“泛化的”汇总。
这里permutation Invariance的意思是指,如果输入序列是[A, B, C, D],自注意力网络得到的输出结果和输入序列为[A, C, B, D]是一样的,以及任何其他的序列中元素位置发生改变后的序列,输出结果都是一样的。

图 如果不向patch中添加位置编码,这两个序列对于Transformer来说看起来是一样的
因此,在输入之前增加位置信息,增加位置信息有助于Transformer理解序列中元素的相对位置。在这里,学习位置编码,而不是使用标准编码。如果没有增加位置编码的话,对于Transformer来说这些序列都一样。
最后,Transformer的输出作为后续的MLP分类器的输入。
从零训练Transformers,比CNN需要更多的数据。这是因为CNN可以编码图像的先验知识比如平移不变性(translational equivariance)。但是Transformers需要从给定的数据中获得这个信息。
平移不变性是卷积层的一种特性,如果我们将图像中的对象向右移动,则特征层的激活(提取的特征)也将向右移动。但它们“实际上是相同的表示”。
ConViT
Vision Transformer,通过可以在patch上实现自注意力机制,学习到卷积归纳偏置(例如:等变)。缺点是,它们需要大量数据才能从头开始学习所有内容
.
CNN有强归纳偏置性,所以在小数据集上表现更好。但如果有大量的数据可用,CNN的强归纳偏置性反而会限制模型的能力。
那么,是否有可能既拥有在小数据集上的强归纳偏置性,并且在大数据集上也不受限呢?
方案是引入区域自注意力机制(Positional Self Attention Mechanism(PSA) ),如果需要的话,它支持模型起卷积层的作用。我们只是用PSA替换了一些自注意层。
我们知道,由于自注意力是有位置无关性质的,因此位置的信息通常是会增加到图像块上。我们并不是在嵌入阶段添加的位置信息,而是用PSA替代原始的自注意层。
在PSA中,注意力的权重是用相对位置编码(r)和经过训练的词向量(v)。这里相对位置编码(r)仅仅依赖于像素间的距离。
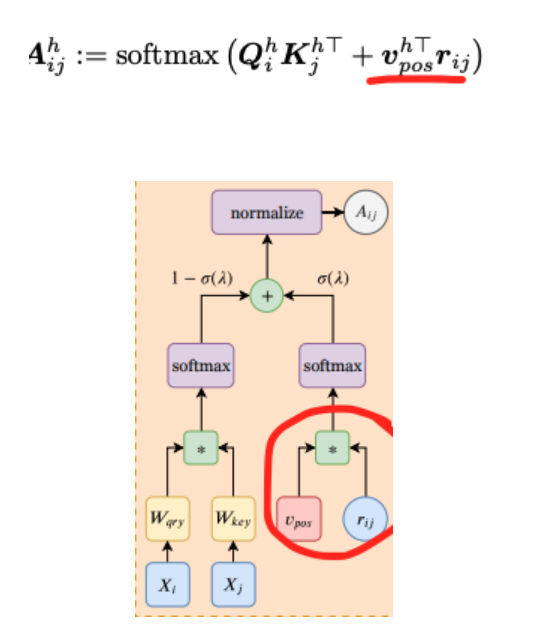
这些具有可学习的相对位置编码的多头 PSA层可以表达任意卷积层。
因此,我们并没有将CNN和注意力机制做整合,而是应用PSA层,通过调整参数可以使得它具有卷积层的效果。在小数据集场景,PSA可以帮助模型更好的推广,而到了大数据集场景,如果需要的话,PSA依然可以保留它的卷积性质。
总结
这里我们展示了,最初用于机器翻译的Transformer在图像领域表现出了很好的效果。在图像分类上,ViTs超过CNN是一个重大的突破。但是,ViTs需要在额外的大数据集上的预训练。在ImageNet数据集上,ConViT超过了ViTs,并且在效率上有所提升。这些都证明了,Transformers具有在图像领域超越CNN的实力。
参考文献
译者简介
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织