
图解!逐步理解Transformers的数学原理
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

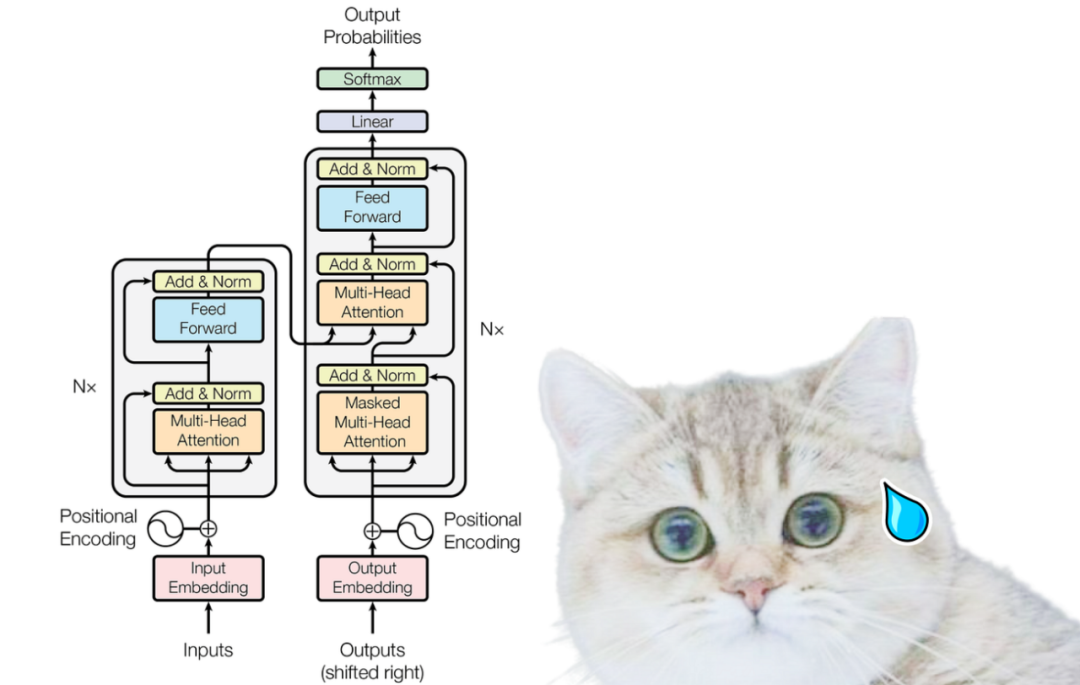
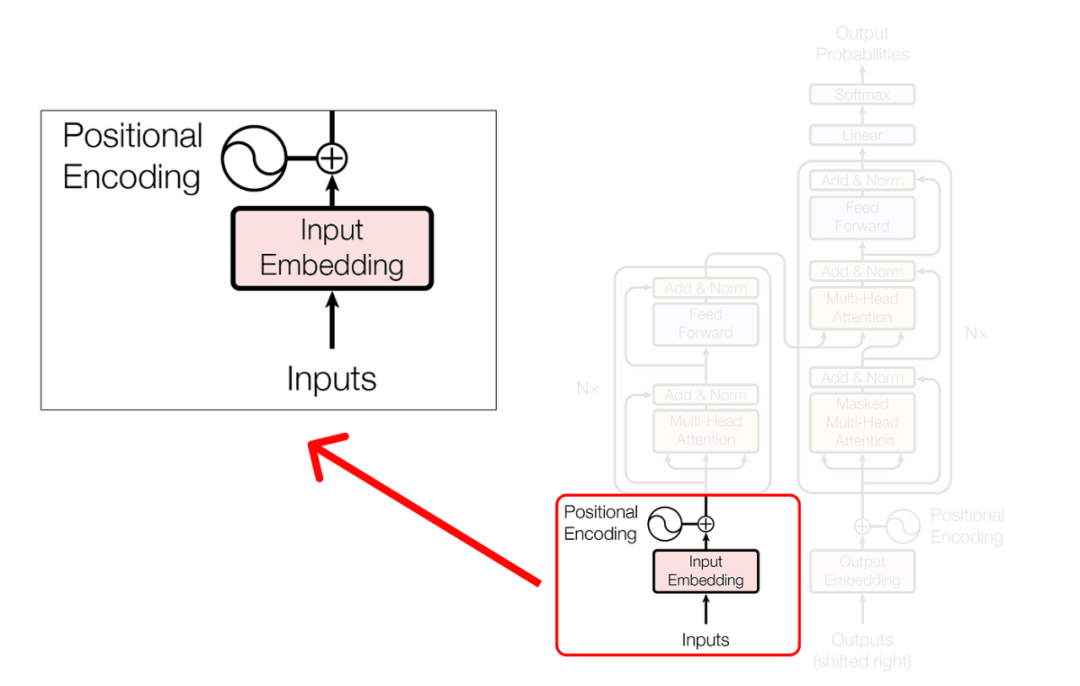
Inputs and Positional Encoding
Step 1 (Defining the data)

Step 2 (Finding the Vocab Size)

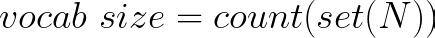


Step 3 (Encoding and Embedding)
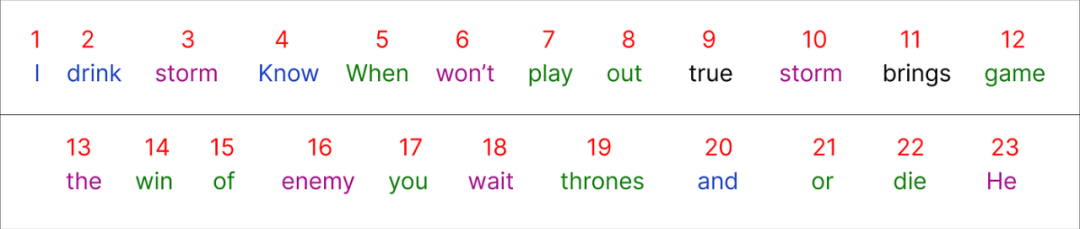
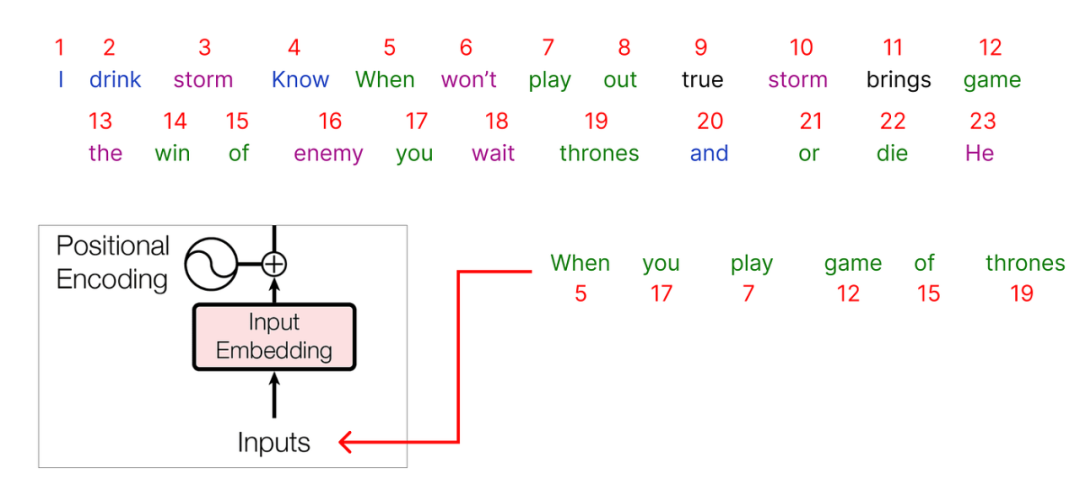
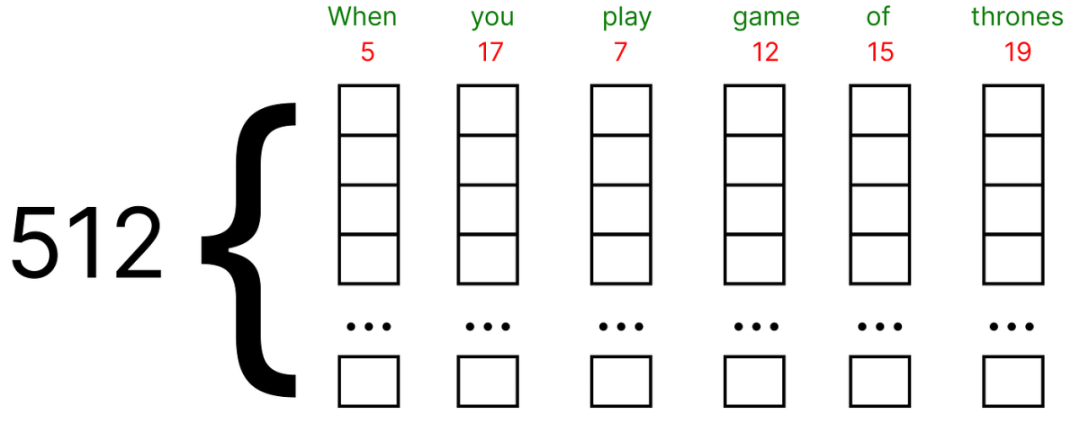
这些embedding可以使用谷歌Word2vec (单词的矢量表示) 找到。在我们的数值示例中,我们将假设每个单词的embedding向量填充有 (0和1) 之间的随机值。
此外,原始论文使用embedding向量的512维度,我们将考虑一个非常小的维度,即5作为数值示例。
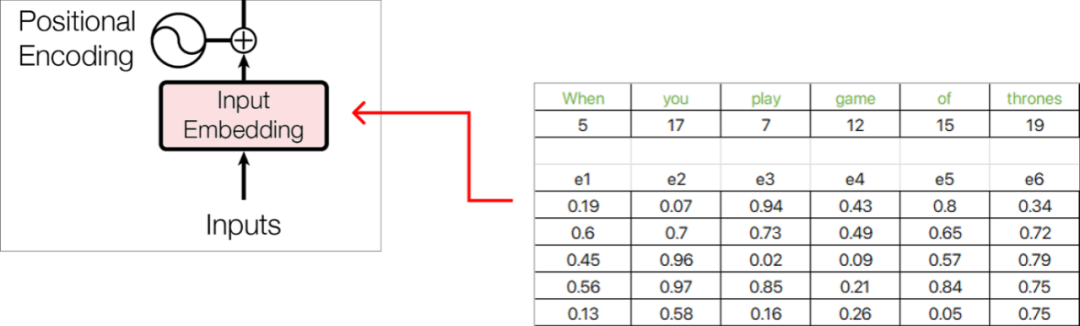
Step 4 (Positional Embedding)
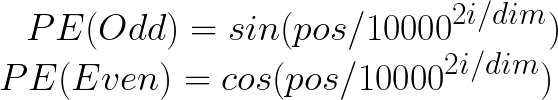
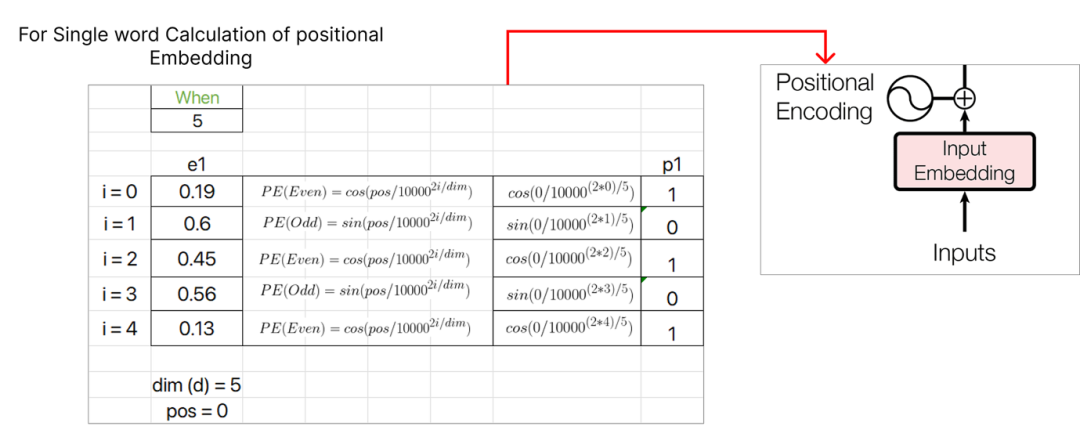
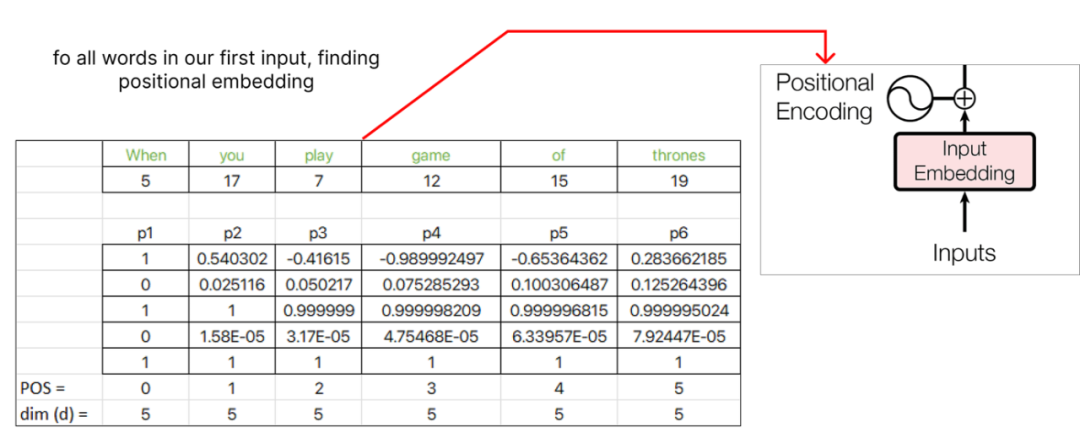
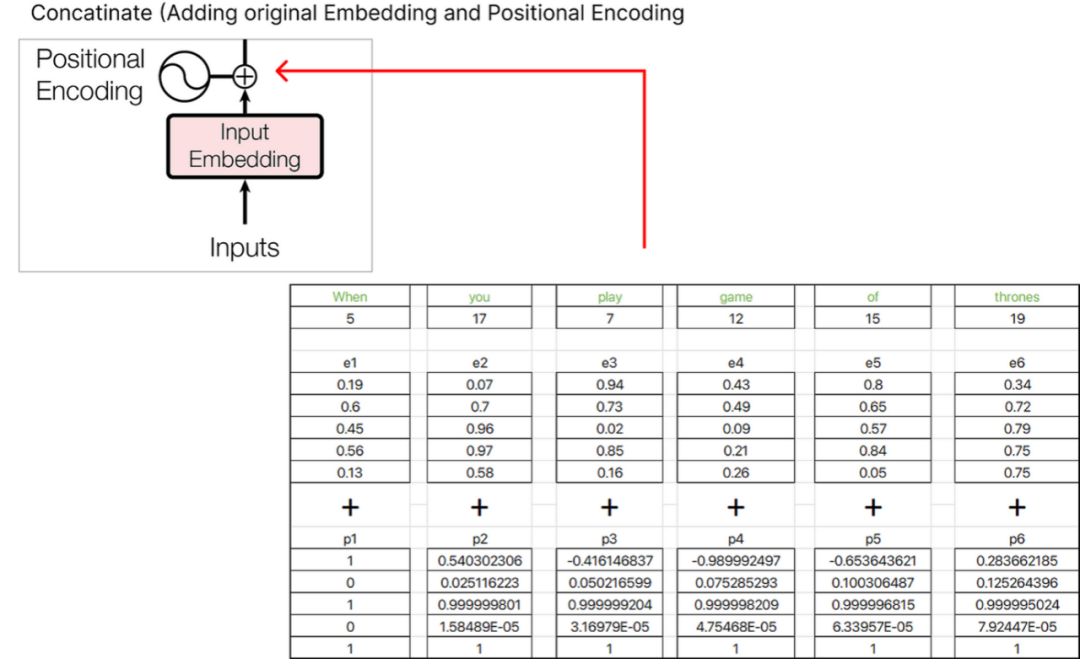
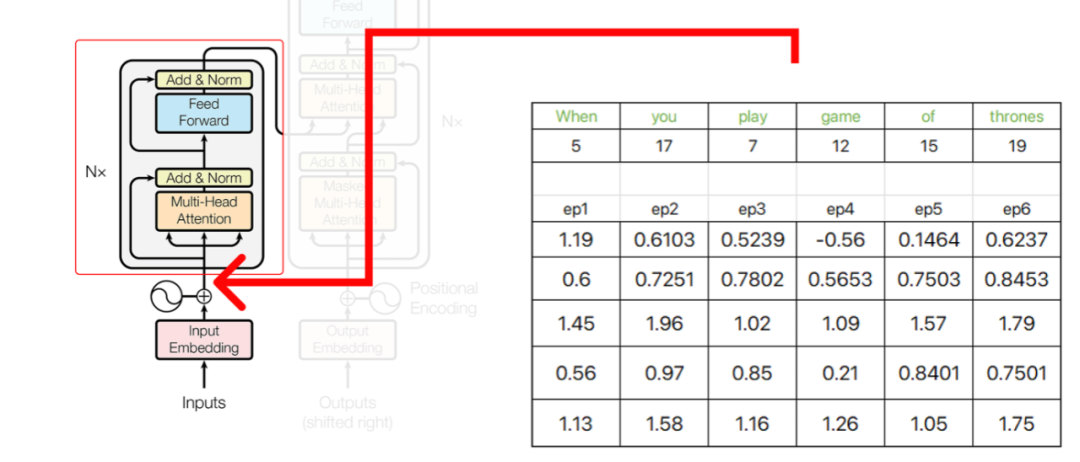
编码器
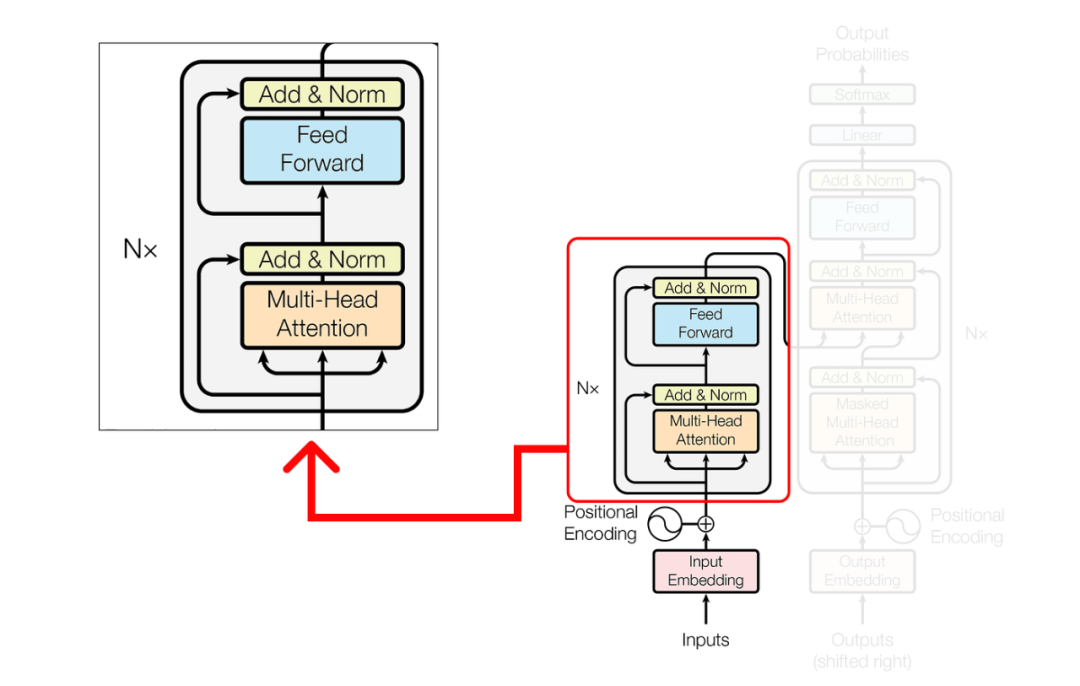
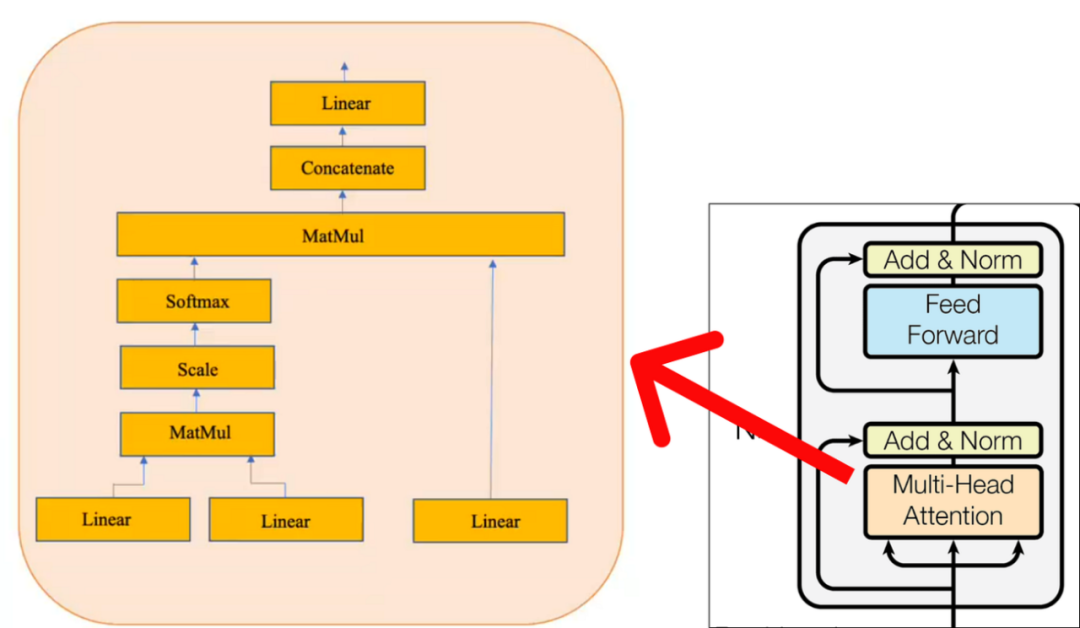
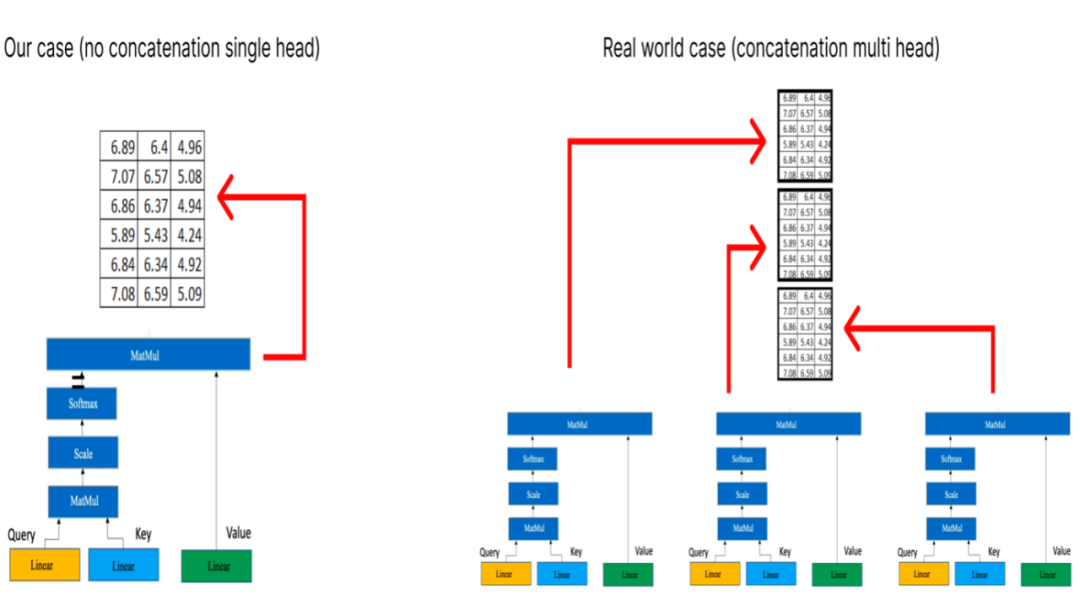
Step 1 (Performing Single Head Attention)
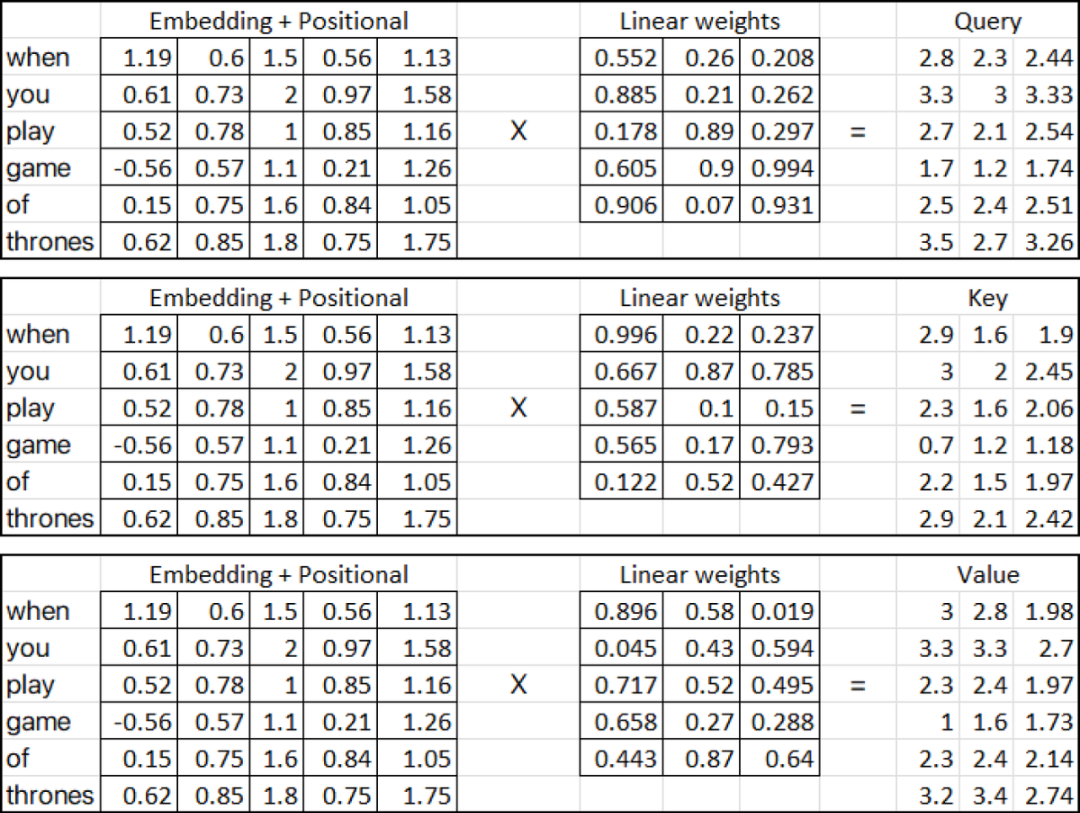
Query
Key
Value

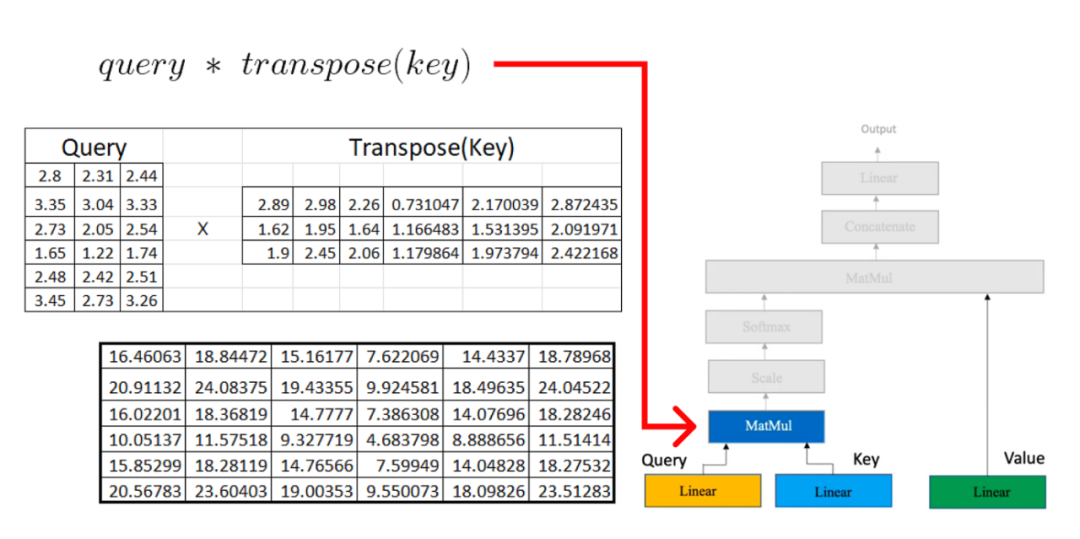
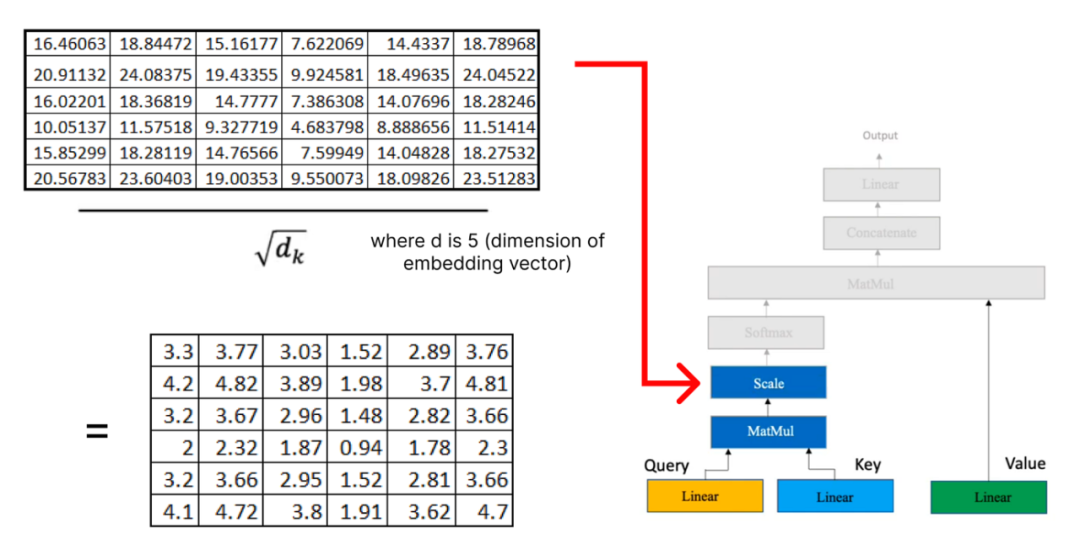
 现在,我们将结果矩阵与我们之前计算的值矩阵相乘:
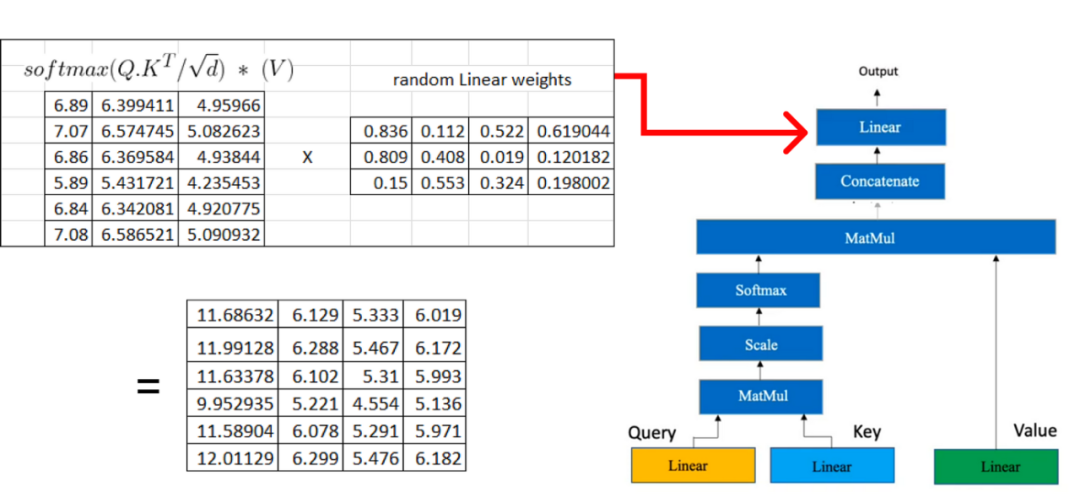
现在,我们将结果矩阵与我们之前计算的值矩阵相乘: 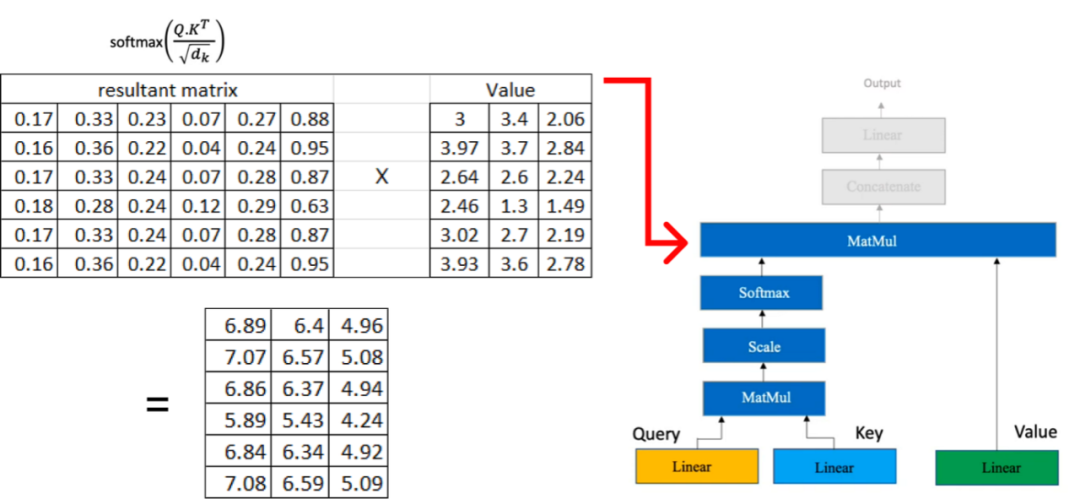
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论