
Transformer在计算机视觉领域走到哪了?

极市导读
未来,Transformer 会不会如同在 NLP 领域的应用一样革新 CV 领域?今后的研究思路又有哪些?微软亚洲研究院多媒体搜索与挖掘组的研究员们基于 Vision Transformer 模型在图像和视频理解领域的最新工作,可能会带给你一些新的理解。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Transformer 模型在自然语言处理(NLP)领域已然成为一个新范式,如今越来越多的研究在尝试将 Transformer 模型强大的建模能力应用到计算机视觉(CV)领域。那么未来,Transformer 会不会如同在 NLP 领域的应用一样革新 CV 领域?今后的研究思路又有哪些?微软亚洲研究院多媒体搜索与挖掘组的研究员们基于 Vision Transformer 模型在图像和视频理解领域的最新工作,可能会带给你一些新的理解。
作为一个由自注意力机制组成的网络结构,Transformer一“出场”就以强大的缩放性、学习长距离的依赖等优势,替代卷积神经网络(CNN)、循环神经网络(RNN)等网络结构,“席卷”了自然语言处理(NLP)领域的理解、生成任务。
然而,Transformer 并未止步于此,2020年,Transformer 模型首次被应用到了图像分类任务中并得到了比 CNN 模型更好的结果。此后,不少研究都开始尝试将 Transformer 模型强大的建模能力应用到计算机视觉领域。目前,Transformer 已经在三大图像问题上——分类、检测和分割,都取得了不错的效果。视觉与语言预训练、图像超分、视频修复和视频目标追踪等任务也正在成为 Transformer “跨界”的热门方向,在 Transformer 结构基础上进行应用和设计,也都取得了不错的成绩。
Transformer“跨界”图像任务
最近几年,随着基于 Transformer 的预训练模型在 NLP 领域不断展现出惊人的能力,越来越多的工作将 Transformer 引入到了图像以及相关的跨模态领域,Transformer 的自注意力机制以其领域无关性和高效的计算,极大地推动了图像相关任务的发展。
端到端的视觉和语言跨模态预训练模型
视觉-语言预训练任务属于图像领域,其目标是利用大规模图片和语言对应的数据集,通过设计预训练任务学习更加鲁棒且具有代表性的跨模态特征,从而提高下游视觉-语言任务的性能。
现有的视觉-语言预训练工作大都沿用传统视觉-语言任务的视觉特征表示,即基于目标检测网络离线抽取的区域视觉特征,将研究重点放到了视觉-语言(vision-language,VL)的特征融合以及预训练上,却忽略了视觉特征的优化对于跨模态模型的重要性。这种传统的视觉特征对于 VL 任务的学习主要有两点问题:
1)视觉特征受限于原本视觉检测任务的目标类别
2)忽略了非目标区域中对于上下文理解的重要信息
为了在VL模型中优化视觉特征,微软亚洲研究院多媒体搜索与挖掘组的研究员们提出了一种端到端的 VL 预训练网络 SOHO,为 VL 训练模型提供了一条全新的探索路径。 该工作的相关论文“Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning”已收录于CVPR 2021 Oral。
论文链接:https://arxiv.org/abs/2104.03135
GitHub地址:https://github.com/researchmm/soho

SOHO 模型的主要思路是:将视觉编码器整合到 VL 的训练网络中,依靠 VL 预训练任务优化整个网络,从而简化训练流程,缓解依赖人工标注数据的问题,同时使得视觉编码器能够在 VL 预训练任务的指导下在线更新,提供更好的视觉表征。
经验证,SOHO 模型不仅降低了对人工标注数据的需求,而且在下游多个视觉-语言任务(包括视觉问答、图片语言检索、自然语言图像推理等)的公平比较下,都取得了 SOTA 的成绩。
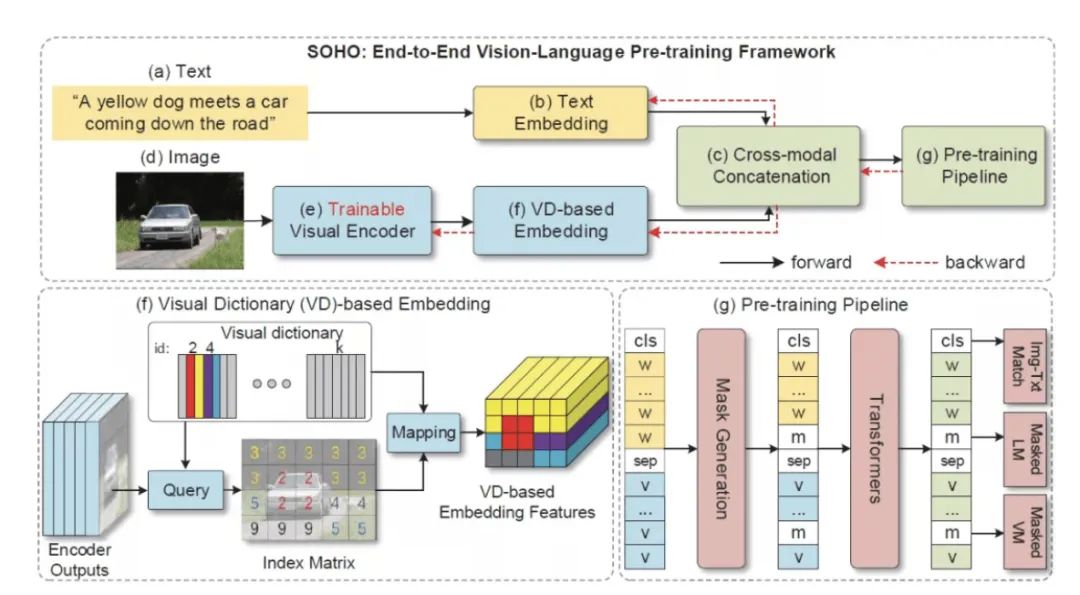 图1:端到端的视觉语言预训练网络 SOHO
图1:端到端的视觉语言预训练网络 SOHO
如图1所示,SOHO 由三部分组成:1)基于卷积网络的视觉编码器(可在线更新);2)基于视觉字典(Visual Dictionary)的视觉嵌入层;3)由多层 Transformer 组成的 VL 融合网络。三个部分“各司其职”,卷积网络负责将一张图像表征为一组向量,然后利用视觉字典对图像中相近的特征向量进行表征,最后利用 Transformer 组成的网络将基于字典嵌入的视觉特征与文本特征融合到一起。
对于视觉编码器,研究员们采用了 ResNet-101 作为基础网络结构对输入图像进行编码,与基于目标检测模型的图像编码器相比,这种方式的好处是:可以简化操作。为了将图像中相近的特征用统一的特征表征,同时为 MVM(Masked vision Modeling)提供类别标签,研究员们利用了视觉字典。整个字典在网络学习的过程中都采用了动量更新的方式进行学习。基于 Transform 的特征融合网络则采用了和 BERT 相同的网络结构。
为了优化整个网络,研究员们利用 MVM、MLM(Masked Language Modeling) 以及 ITM(Image-Text Matching) 三个预训练任务进行了模型训练,并将得到的参数应用到了四个相关的 VL 下游任务上,均取得了较好的结果(如表格1-4所示)。
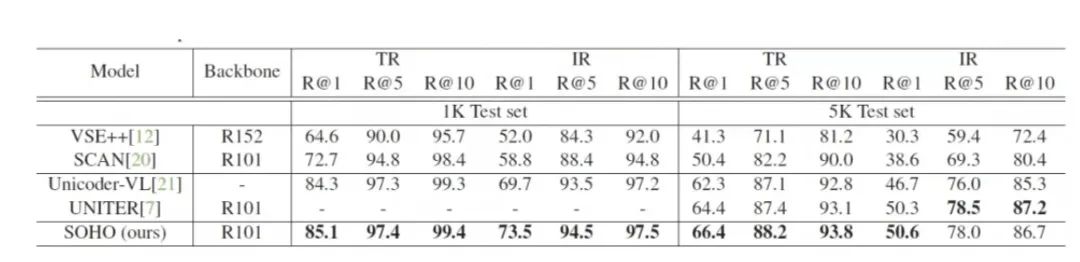
表格1:SOHO 在 MSCOCO 数据集上与其他方法的 text retrieval(TR)和 image retrieval(IR)的性能比较
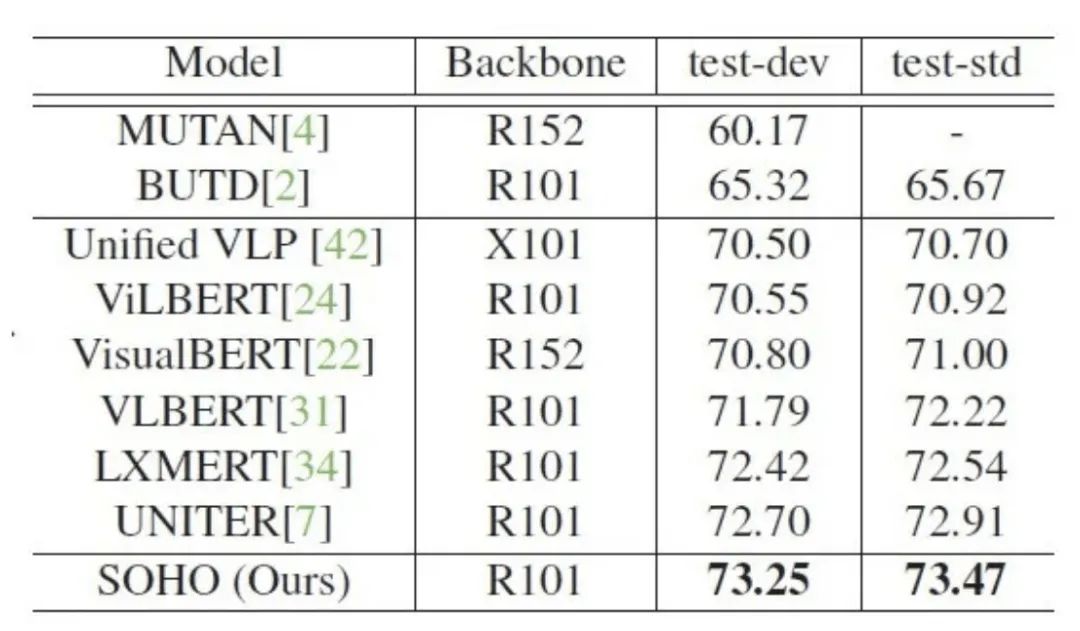
表格2:SOHO 在 VQA 2.0 数据集上的 VQA 性能表现
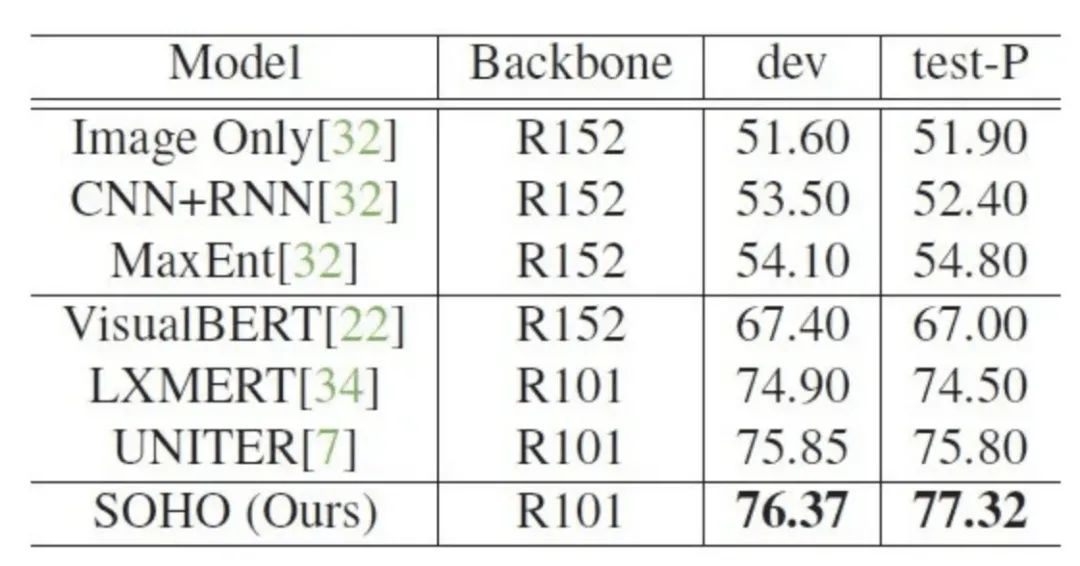
表格3:SOHO 在 NLVR2 数据集上的 Visual Reasoning 性能表现
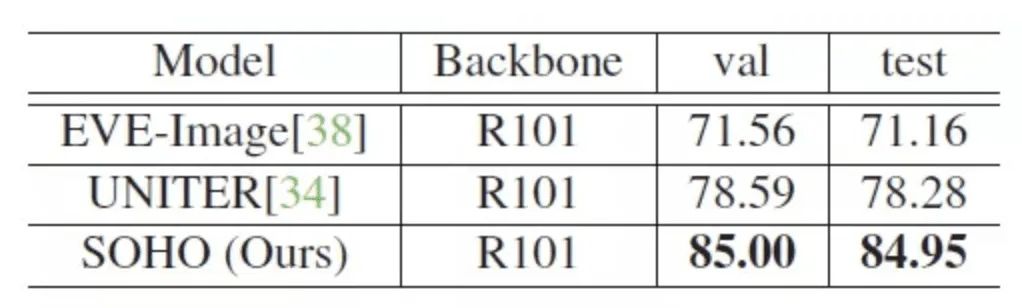
表格4:SOHO 在 SNLI-VE 数据集上的 Visual Entailment 性能表现
最后,通过对视觉字典中部分 ID 对应的图片内容进行可视化(如图2所示),研究员们发现即使没有强监督的视觉类别标注,SOHO 也可以将具有相似语义的视觉内容聚类到同一个字典项中。相对于使用基于目标检测的视觉语言模型,SOHO 摆脱了图片框的回归需求,推理时间(inference time)也加快了10倍,在真实场景应用中更加实际和便捷。

图2:Visual Dictionary 部分 ID 对应图片内容的可视化
基于纹理 Transformer 模型的图像超分辩率技术
从古老的胶片照相机到今天的数码时代,人类拍摄和保存了大量的图片信息,但这些图片不可避免地存在各种不同程度的瑕疵。将图片变得更清晰、更鲜活,一直是计算机视觉领域的重要话题。针对于图像超分辨率的问题,微软亚洲研究院的研究员们创新性地将 Transformer 结构应用在了图像生成领域,提出了一种基于纹理 Transformer 模型的图像超分辩率方法 TTSR。
该模型可以有效地搜索与迁移高清的纹理信息,最大程度地利用参考图像的信息,并可以正确地将高清纹理迁移到生成的超分辨率结果当中,从而解决了纹理模糊和纹理失真的问题。 该工作“Learning Texture Transformer Network for Image Super-Resolution”发表在 CVPR 2020。
论文链接:https://arxiv.org/pdf/2006.04139.pdf
GitHub地址:https://github.com/researchmm/TTSR

与先前盲猜图片细节的方法不同,研究员们通过引入一张高分辨率参考图像来指引整个超分辨率过程。高分辨率参考图像的引入,将图像超分辨率问题由较为困难的纹理恢复/生成转化为了相对简单的纹理搜索与迁移,使得超分辨率结果在指标以及视觉效果上有了显著的提升。如图3所示,TTSR 模型包括:可学习的纹理提取器模块(Learnable Texture Extractor)、相关性嵌入模块(Relevance Embedding)、硬注意力模块(Hard Attention)、软注意力模块(Soft Attention)。
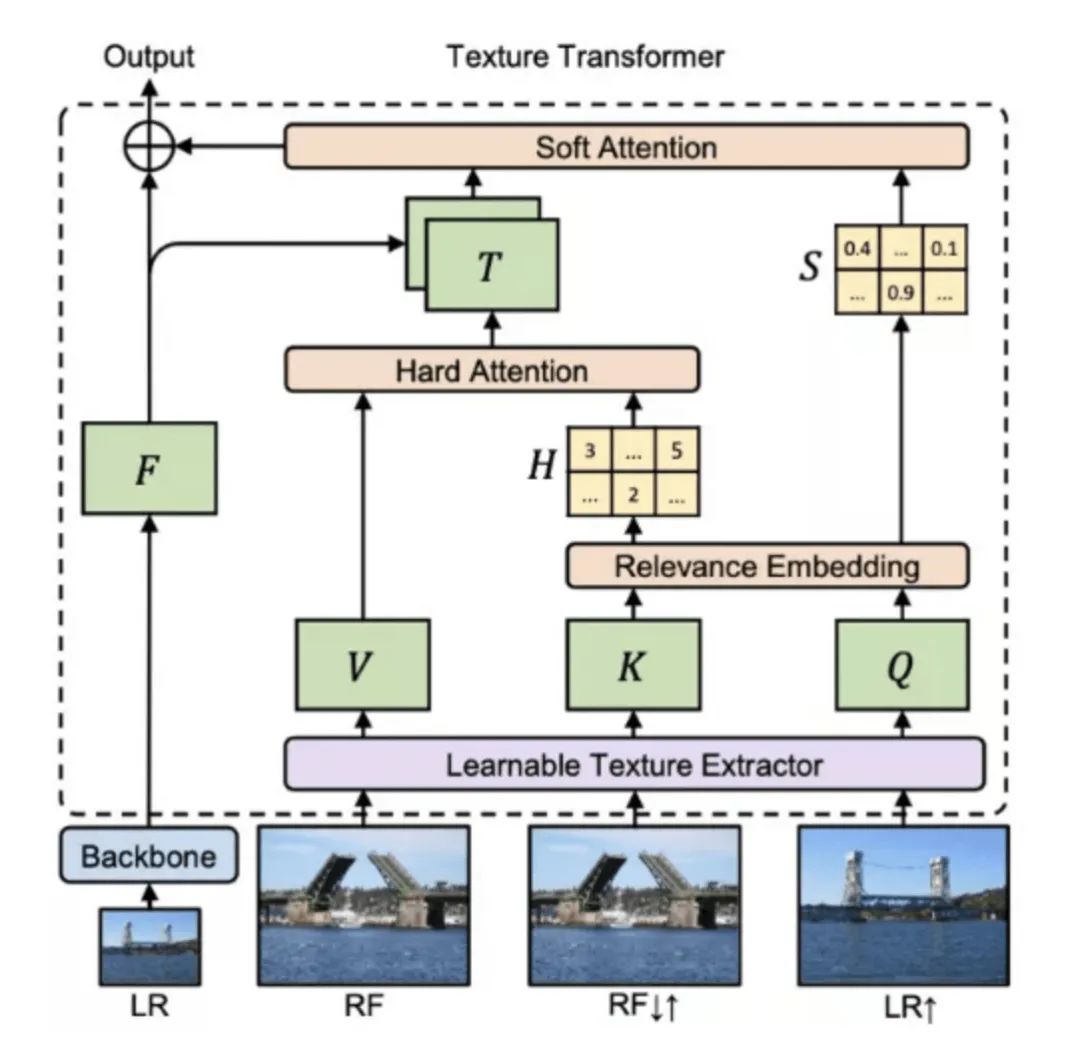
图3:纹理 Transformer 模型
传统 Transformer 通过堆叠使得模型具有更强的表达能力,然而在图像生成问题中,简单的堆叠很难产生很好的效果。为了进一步提升模型对参考图像信息的提取和利用,研究员们提出了跨层级的特征融合机制——将所提出的纹理 Transformer 应用于 x1、x2、x4 三个不同的层级,并将不同层级间的特征通过上采样或带步长的卷积进行交叉融合。因此,不同粒度的参考图像信息会渗透到不同的层级,使得网络的特征表达能力增强,提高生成图像的质量。
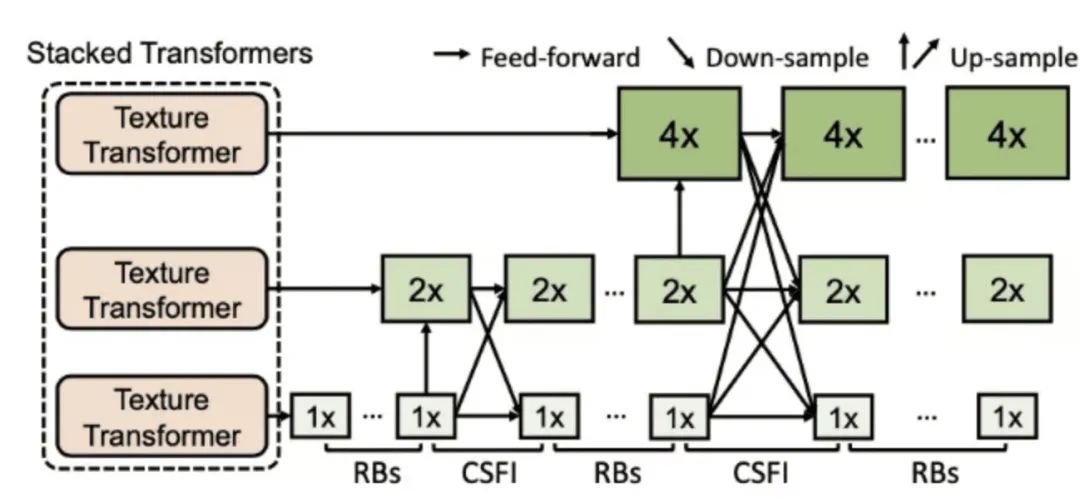
图4:多个纹理 Transformer 跨层级堆叠模型
研究员们在 CUFED5、Sun80、Urban100、Manga109 数据集上针对 TTSR 方法进行了量化比较,具体如表格5所示。图5展示了 TTSR 与现有的方法在不同数据集上的视觉比较结果,可以发现 TTSR 显著领先于其他方法的结果。
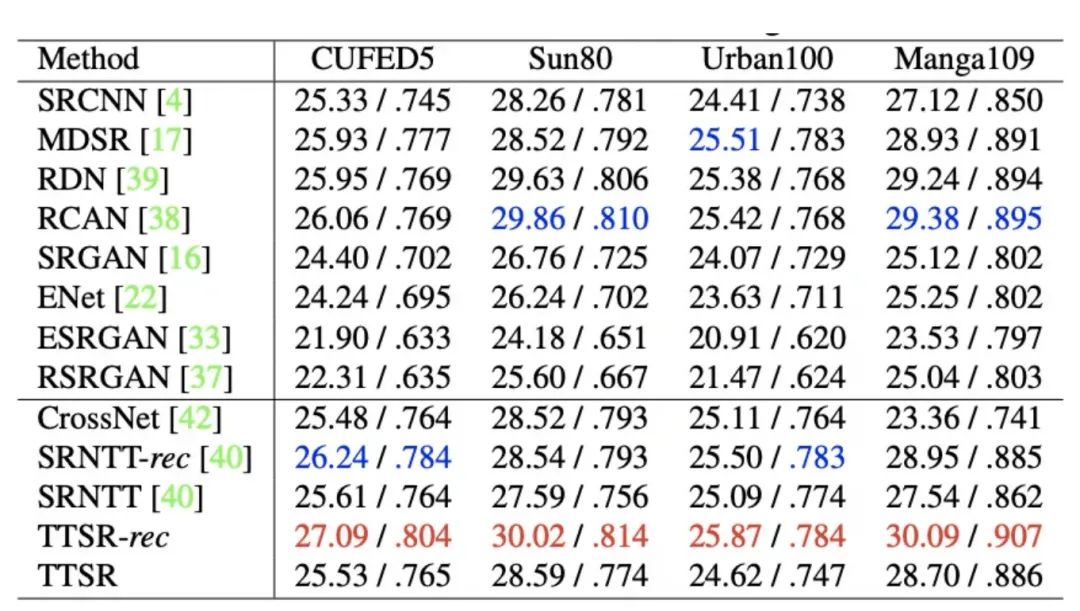
表格5:TTSR 与现有方法在不同数据集上的量化比较结果

图5:TTSR 与现有方法在不同数据集上的视觉比较结果
Transformer“跨界”视频任务
相对于图像的空间信息,视频还增加了时序维度的信息。Transformer 可以很好地在空间-时序维度上进行建模,进而更好地学习图像与特征中的长距离依赖关系,有利于视频相关任务的增强与提高。
视频修复:Transformer 初尝试
视频修复(video inpainting)是一个旨在通过视频中已知内容来推断并填补缺失内容的经典任务。它在老旧视频恢复、去除水印等视频编辑中有着广泛应用。尽管视频修复技术有很大的应用价值,然而在复杂变化的多个视频帧中找到相关信息,并生成在图像空间和时序上看起来和谐、一致的内容,仍然面临着巨大的挑战。
为了解决这样的问题,微软亚洲研究院的研究员们利用并重新设计了Transformer结构,提出了 Spatial-Temporal Transformer Network (STTN)。 相关论文“Learning Joint Spatial-Temporal Transformations for Video Inpainting”发表在了 ECCV 2020。
论文链接:https://arxiv.org/abs/2007.10247
GitHub地址:https://github.com/researchmm/STTN

STTN 模型的输入是带有缺失内容的视频帧以及每一帧的掩码,输出则是对应的修复好的视频帧。如图6所示,STTN 模型的输入是带有缺失内容的视频帧以及每一帧的掩码,输出则是对应的修复好的视频帧。如图6所示,STTN 模型采用了 CNN-Transformer 的混合结构。其中,frame-level encoder 以及 frame-level decoder 采用了 CNN,分别将每个视频帧从像素编码成特征以及将特征解码成视频帧。Transformer 则作为模型的主干,它将输入的视频帧特征切成块,并对块的序列进行建模,再通过多层时空 Transformer 层挖掘输入帧中的已知信息来推断缺失内容。
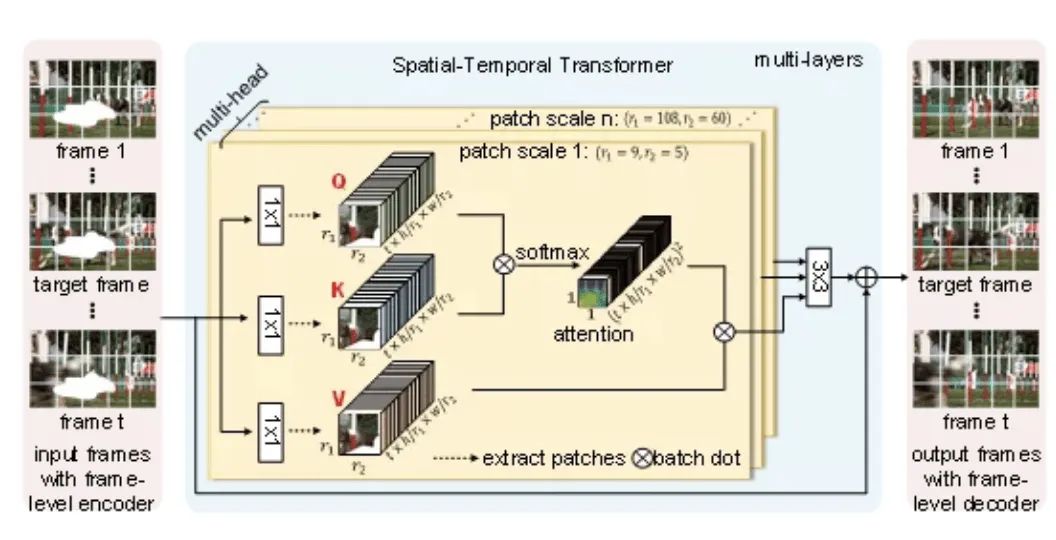
图6: Spatial-Temporal Transformer Network (STTN) 模型结构示意图
时空 Transformer 层继承了经典 Transformer 层强大的注意力机制,能聚焦于与缺失内容相关的信息上,通过多层的堆叠不断更新优化预测的内容。同时,不同于经典 Transformer 层中每个头部的是模型采用了固定的块大小,STTN 为了捕捉到尽可能多的上下文信息,在不同的头部上采用了不同大小的块切取方式。因此,当缺失区域的特征不够丰富时,基于大的块的注意力机制可以有效利用较多的已知信息;当缺失区域的特征丰富之后,基于小的块的注意力机制有助于模型聚焦更细微的变化。如图7所示,通过可视化 STTN 最后一层 Transformer 的注意力图,可以发现 STTN 为了填补目标帧中狗身上的缺失区域,能够 “精准追踪” 到其他帧里的信息,来修复缺失区域。

图7:Attention map 的可视化(attention 的部分用黄色高亮)。尽管视频里狗由于奔跑,在不同的帧里形态和位置差异较大,但为了填补目标帧(target frame)中狗身上缺失的部分,STTN 可以 “精准追踪” 到相关的帧里这只跑动的狗。
除了 STTN 模型,该论文还提出了用动态和静态两种不同的视频掩码来模拟实际应用。动态掩码指视频每一帧的掩码是连续变化的,用来模拟移除运动物体的应用;而静态掩码不会随着视频变化,用来模拟水印移除。论文通过在 DAVIS 和 Youtube-VOS 数据集上定性和定量的分析,验证了 STTN 在视频修复任务上的优越性。STTN 能够生成视觉上更真实的修复结果。同时得益于 STTN 强大的并行建模能力,它也加快了运行速度(24.10 fps VS. 3.84 fps)。
目标跟踪新范式:基于时空 Transformer
视频目标跟踪(Visual Object Tracking)是计算机视觉领域中的一项基础且颇具挑战性的任务。在过去几年中,基于卷积神经网络,目标跟踪迎来了快速的发展。然而卷积神经网络并不擅长建模图像与特征中的长距离依赖关系,同时现有的目标跟踪器或是仅利用了空间信息,亦或是并未考虑到时间与空间之间的联系,造成跟踪器在复杂场景下性能的下降。
如何解决以上问题?微软亚洲研究院的研究员们提出了一种名为 STARK 的基于时空 Transformer 的目标跟踪器新范式,将目标跟踪建模为一种端到端的边界框预测问题,从而彻底摆脱以往跟踪器使用的超参敏感的后处理,该方法在多个短时与长时跟踪数据集上都取得了当前最优的性能。
相关论文“Learning Spatio-Temporal Transformer for Visual Tracking”
链接:https://arxiv.org/abs/2103.17154
GitHub地址:https://github.com/researchmm/stark

STARK 包括 Spatial-Only 和 Spatio-Temporal 两个版本,其中 Spatial-Only 版本仅使用空间信息,Spatio-Temporal 版本则同时利用了时间和空间信息。
Spatial-Only 版本的框架图如图8所示。首先,第一帧的模板和当前帧的搜索区域会一同送入骨干网络提取视觉特征,然后特征图沿空间维度展开并拼接,进而得到一个特征序列。之后,Transformer 编码器会建模序列元素之间的全局关联,并利用学习到的全局信息来强化原始特征,使得新的特征序列对目标具有更强的判别力。受 DETR 的启发,研究员们使用了一个解码器以及一个目标查询(Target Query)来对编码器的输出进行译码。目标查询与前面提到的编码器输出的特征序列进行交互,从而学习到和目标相关的重要信息。最后,编码器输出的特征序列以及译码器输出的新的目标查询特征再一同送入边界框预测模块,得到最终的边界框坐标。
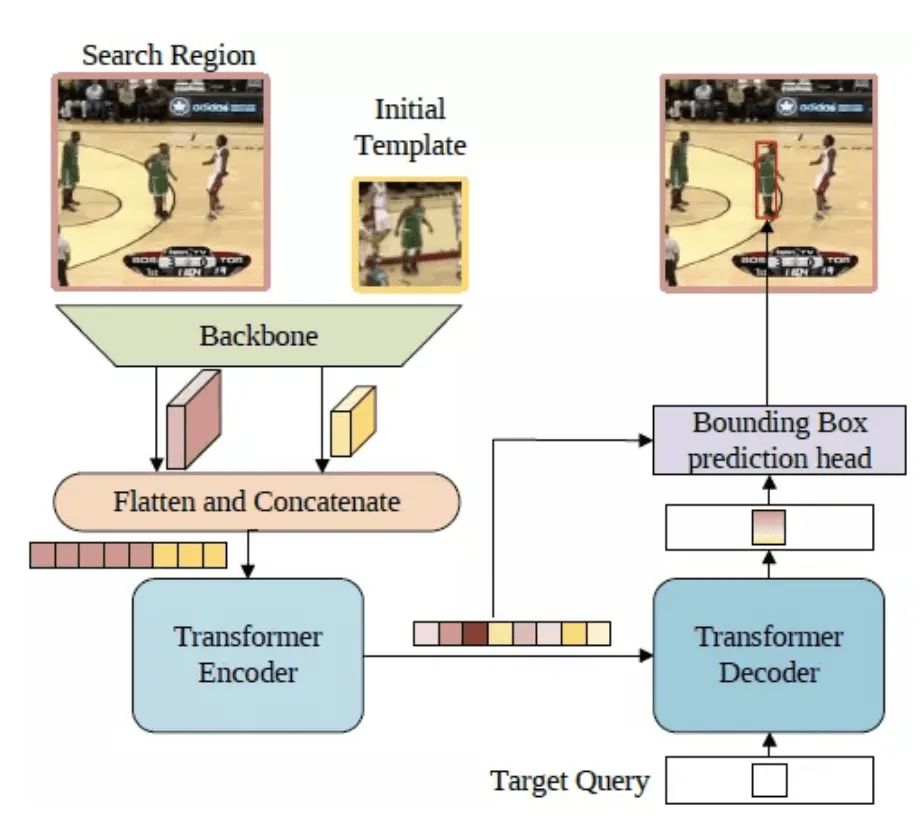 图8:Spatial-Only 版本的框架图
图8:Spatial-Only 版本的框架图
边界框预测模块的结构如图9所示,首先从编码器的输出序列中取出搜索区域相关的特征,用该特征序列与译码器输出的目标查询特征计算一次注意力机制,强化目标所在区域的特征,削弱非目标区域的特征。然后,经注意力机制强化后的搜索区域特征序列的空间结构被还原,并通过简单的全卷积网络预测目标左上角和右下角一对角点(corners)的热力图,最终的角点坐标则通过计算角点坐标的数学期望得到。不同于之前的Siamese和DCF方法,该框架将目标跟踪建模为一个直接的边界框预测问题,每一帧上都可直接预测一个边界框坐标,无需使用任何超参敏感的后处理。
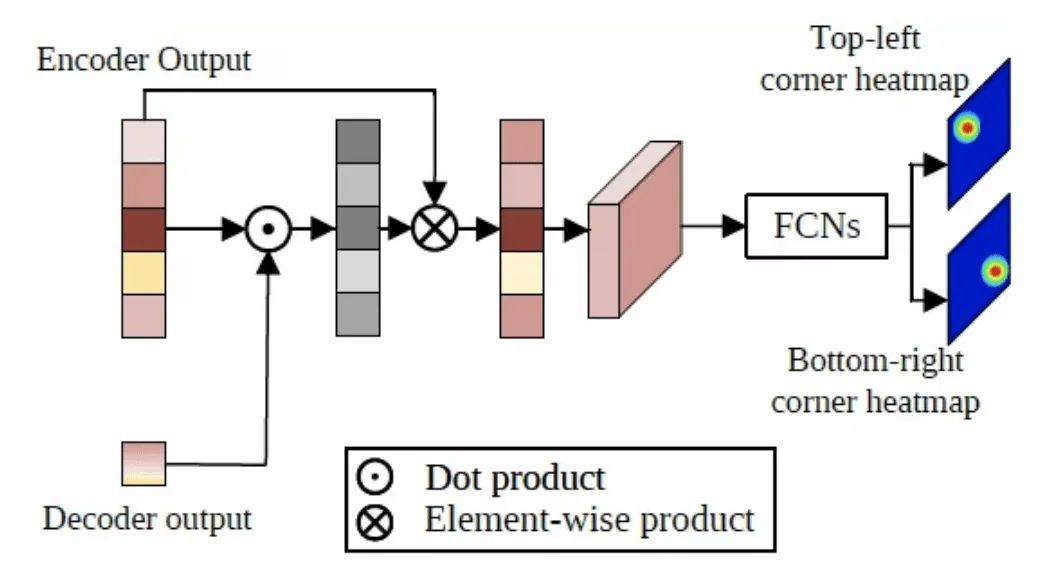
图9:边界框预测模块的结构
Spatio-Temporal 版本的框架图如图10所示,粉色区域展示了为了利用时序信息而新加入的结构。新框架额外加入了一个 “动态模板” 作为新输入。动态模板是根据中间帧跟踪结果裁剪得到的,并随着跟踪的进行动态更新,为整个框架补充了之前缺少的时序信息。利用第一帧模板、当前帧搜索区域、动态模板同时作为 Transformer 编码器的输入,编码器能够从全局视角提取时空信息,学习到鲁棒的时空联合表示。除动态模板之外,研究员们还引入了由多层感知机实现的更新控制器来更新动态模板,它与边界框预测头并联,以预测当前帧可靠程度的置信度分数。
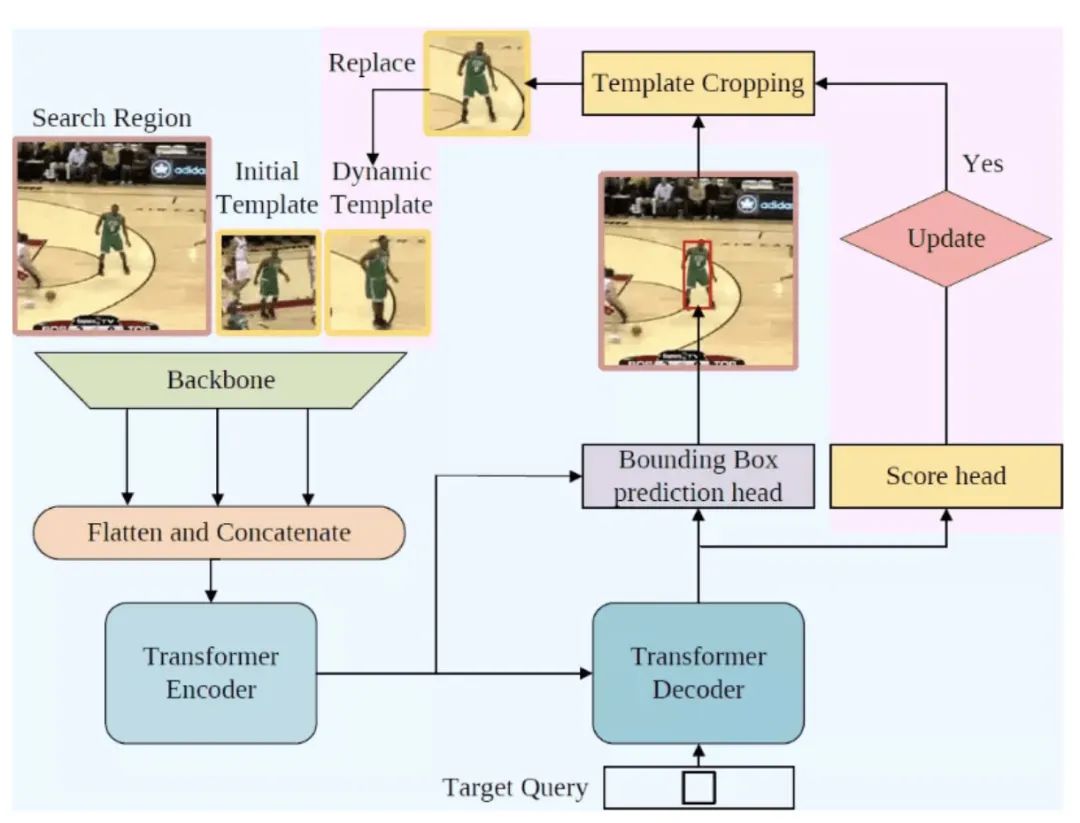
图10:Spatio-Temporal 版本框架图
STARK 在多个短时跟踪与长时跟踪数据集上都取得了目前最先进的性能,并且运行速度可达 30FPS 到 40FPS。其中,在 LaSOT, GOT-10K, TrackingNet 三个大规模目标跟踪数据集上的结果如下所示。
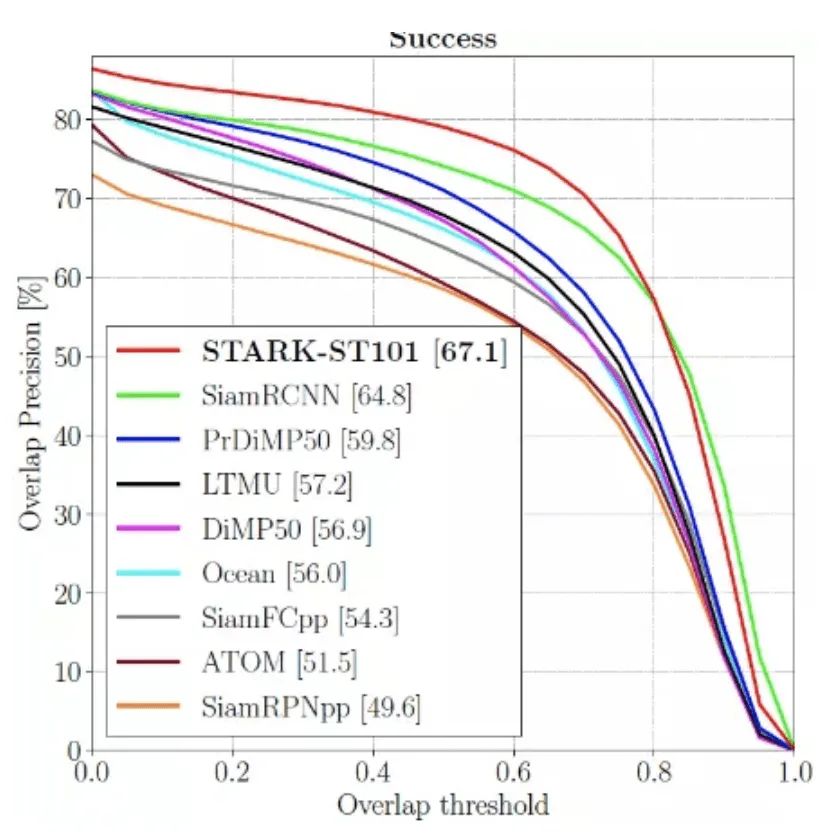
图11:LaSOT 数据集上的结果比较

表格6:GOT-10K 数据集上的结果比较

表格7:TrackingNet 数据集上的结果比较
上述四个工作将 Transformer 结构成功地应用于图像内容增强和视频内容分析, 充分地展现了 Transformer 的优势和潜力。目前研究员们已经看到,无论是在图像分类、物体检测与分割等基础视觉任务上,还是在 3D 点云分析、图像视频内容生成等新兴课题中,Transformer 都大放异彩。未来,视觉 Transformer 结构的设计和自动化搜索将会是一个非常具有前景的研究课题。相信 Transformer 结构在计算机视觉领域会继续展现其强大的模型潜力。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CNN综述”获取67页综述深度卷积神经网络架构~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
