
ICCV 2021 Workshop|医学影像等小数据集能否用Transformer替代CNN?

极市导读
本文解读了一篇ICCV 2021 workshop的工作,该工作本文研究比较了CNN和ViTs在三种不同初始化策略下在医学图像任务中的表现,研究了自监督预训练对医学图像领域的影响,最后得出结论:医学图像分析可以从CNN无缝过渡到ViTs,同时获得更好的可解释性特性。>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
医学领域的数据集具有标注样本少、图像非自然的特点,transformer已经证明了在自然图像领域下的成功,而能否应用于医学领域等少量标注样本的非自然图像领域呢?
本文研究比较了CNN和ViTs在三种不同初始化策略下在医学图像任务中的表现,研究了自监督预训练对医学图像领域的影响,并得出了三个结论。

论文地址:https://arxiv.org/abs/2108.09038
代码:https://github.com/ChrisMats/medical_transformers
Background
目前已经提出了许多使transformers适应视觉任务的方法。在自然图像领域,transformers已被证明在标准视觉任务(如ImageNet分类、以及目标检测和语义分割)上优于CNN。与卷积相比,transformers的中心注意力机制提供了几个关键的优势:(1)它捕获远程关系,(2)它具有通过动态计算的self-attention权重(捕获Tokens之间的关系)进行自适应建模的能力,(3)它提供了一种内置的突显性,使人们能够洞察模型关注的是什么。
然而,有证据表明,vision transformer需要非常大的数据集才能超越CNN中,只有当谷歌的3亿张私人图像数据集JFT-300M用于预训练时,ViT的好处才变得明显起来。他们对这种规模的数据的依赖是transformers广泛应用的障碍。这个问题在医学成像领域尤其严重,那里的数据集较小,而且往往伴随着不太可靠的标签。
CNN和ViTs一样,在数据稀缺时性能较差。标准的解决方案是使用迁移学习:通常,模型在较大的数据集(如ImageNet)上预先训练,然后使用较小的、专门的数据集针对特定任务进行微调。在ImageNet上预先训练的CNN通常在最终性能和减少的训练时间方面都优于那些在医学领域从头开始训练的CNN。
自监督是一种处理未标记数据的学习方法,最近得到了广泛的关注。研究表明,在微调前对目标域中的CNN进行自监督预训练可以提高性能。ImageNet的初始化有助于自监督CNN更快地收敛,通常具有更好的预测性能。
这些处理医学图像领域缺乏数据的技术已被证明对CNN有效,但尚不清楚vision transformer是否也有类似的好处。一些研究表明,使用ImageNet对CNN进行医学图像分析的预训练并不依赖于特征复用(feature reuse)(遵循传统观点),而是由于更好的初始化和权重调整。这让人质疑transformers是否能从这些技术中获益。如果他们这样做了,几乎没有什么能阻止ViTs成为医学图像的主导架构。
在这项工作中,论文探索ViTs是否可以很容易地替代CNN用于医学成像任务,以及这样做是否有优势。论文考虑一个典型从业者的用例,它配备了有限的计算预算和访问传统医学数据集的权限,着眼于“即插即用(plug-and-play)”的解决方案。为此,论文在三个主流的公开数据集上进行了实验。
通过这些实验,得出以下结论:
在ImageNet上预先训练的ViTs在数据有限的情况下表现出与CNN相当的性能。 在应用标准训练方案和设置时,迁移学习有利于ViTs。 当自监督的预训之后是监督的微调时,ViTs的表现要好于CNN。
这些发现表明,医学图像分析可以从CNN无缝过渡到ViTs,同时获得更好的可解释性特性。
Methods
论文调查的主要问题是ViTs是否可以作为CNN的即插即用替代品用于医疗诊断任务。为此,进行了一系列实验,以比较ViTs和CNN在相似条件下的差异,将超参数调整保持在最低限度。为了确保比较的公正性和可解释性,选择了具有代表性的ResNet50,以及带有16x16 Tokens的Deit-S作为ViT。之所以选择这些型号,是因为它们在参数数量、内存需求和计算方面具有可比性。
如上所述,当数据不太丰富时,CNN依赖初始化策略来提高性能,医学图像就是这种情况。标准的方法是使用迁移学习-用ImageNet上预训练的权重来初始化模型,并在目标域上微调。
因此,论文考虑了三种初始化策略:(1)随机初始化权重,(2)使用监督ImageNet预训练权值的迁移学习,(3)在目标数据集上的自监督预训练,在初始化之后,如(2)所示。将这些策略应用于三个标准医学成像数据集,以覆盖不同的目标域:
APTOS 2019-在此数据集中,任务是将糖尿病视网膜病变图像分类为5类疾病严重程度。Aptos 2019包含3662张高分辨率视网膜图像。
ISIC 2019-任务是将25,333张皮肤镜图像从九种不同的皮肤损伤诊断类别中分类。
CBIS-DDSM-此数据集包含10,239张乳房X光照片,任务是检测乳房X光照片中是否存在肿块。
Experiments
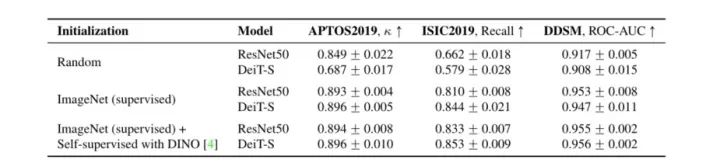
CNN与ViTs在不同初始化策略下的比较
1. 随机初始化的transformer有用吗?
首先将Deit-S与具有随机初始化权重的ResNet50进行比较(Kaiming初始化)。上表中的结果表明,在这种设置下,CNN在所有方面都远远超过ViTs。这些结果与之前在自然图像领域的观察结果一致,在自然图像领域,在有限数据上训练的ViTs表现优于类似大小的CNN,这一趋势被归因于ViT缺乏归纳偏差。由于大多数医学成像数据集的大小适中,随机初始化的ViTs的用处似乎是有限的。
2. ImageNet上的预训练transformer在医学图像领域工作吗?
在医学图像数据集上,随机初始化在实践中很少使用。标准步骤是通过用ImageNet预先训练的权重初始化网络,然后对来自目标域的数据进行微调来训练CNN。在这里,论文调查了这种方法是否可以有效地应用于ViTs。为了测试这一点,论文使用已在ImageNet上以完全监督的方式预先训练的权重来初始化所有模型。然后,使用上述过程进行微调。
上表中的结果表明,CNN和ViTs都从ImageNet初始化中获得了显著的好处。事实上,ViT似乎受益更多,因为它们的表现与CNN不相上下。这表明,当使用ImageNet进行初始化时,CNN可以用ViTs代替,而不会影响使用中等大小训练数据的医学成像任务的性能。
3.医学图像领域的transformer使用自监督是否有益?
最近的自我监督学习方案,如Dino和BYOL,都采用监督学习的方法。此外,如果将它们用于预训练和有监督的微调,它们可以达到新的SOTA。虽然这一现象在较大的数据系统中已经在CNN和ViTs中得到证实,但目前还不清楚ViTs的自我监督预训练是否有助于医学成像任务,特别是在中等和低尺寸数据上。
为了验证这一点,论文采用了Dino的自监督学习方案,该方案可以很容易地应用于CNN和ViTs。Dino使用自蒸馏(self-distillation)来鼓励学生和教师网络在不同的扩充输入的情况下产生相似的表示。自监督预训练从ImageNet初始化开始,然后按照原论文作者建议的默认设置对目标医疗领域数据应用自我监督学习-除了三个小的变化:(1)基本学习率设置为0.0001,(2)初始权重衰减设置为10‘5,并使用余弦进度表增加到10’4,以及(3)使用的均方根均值为0.99。CNN和ViTs使用相同的设置;两者都使用256的批次大小进行了300个周期的预训练,然后进行了微调。
上表中报告的结果显示,ViTs和CNN在自监督的预训练中都表现得更好。在这种情况下,ViTs的表现似乎优于CNN,尽管差距很小。对自然图像的研究表明,VITS和CNN之间的差距将随着更多的数据而扩大。
Conclusion
本文研究比较了CNN和ViTs在三种不同初始化策略下在医学图像任务中的表现。研究了自监督预训练对医学图像领域的影响。
结果表明,ViTs和CNNS的改善幅度很小,但持续不变。虽然使用自监督ViTs获得了最佳的整体性能,但有趣的是,在这种低数据区域中,我们还没有看到有利于先前在具有更多数据的自然图像领域中报告的ViTs的强大优势,例如在中,由于专家标注的成本,很少有大的标记的医学图像数据集,但是可能收集大量未标记的图像。这表明,这是一个诱人的机会,可以将自监督应用于大型医学图像数据集,其中只有一小部分被标记。
总结发现,对于医学图像领域:
正如预期的那样,如果简单地从头开始训练,在低数据制度下,ViTs比CNN更糟糕。 迁移学习弥合了CNN和ViTs之间的性能差距;性能相似。 通过自监督的预训练+微调获得最佳性能,ViTs与同类CNN相比略有优势。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
