
Pytorch实现图像修复:GAN+上下文自编码器
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:Hmrishav Bandyopadhyay 编译:公众号 ronghuaiyang AI公园
一篇比较经典的图像复原的文章。
你知道在那个满是灰尘的相册里的童年旧照片是可以复原的吗?是啊,就是那种每个人都手牵着手,尽情享受生活的那种!不相信我吗?看看这个:
图像修复是人工智能研究的一个活跃领域,人工智能已经能够得出比大多数艺术家更好的修复结果。在本文中,我们将讨论使用神经网络,特别是上下文编码器的图像修复。本文解释并实现了在CVPR 2016中提出的关于上下文编码器的研究工作。
上下文编码器
为了开始使用上下文编码器,我们必须了解什么是“自编码器”。自编码器在结构上由编码器、解码器以及一个bottleneck组成。一般的自编码器的目的是通过忽略图像中的噪声来减小图像的尺寸。然而,自编码器不是特定于图像,也可以扩展到其他数据。自编码器有特定的变体来完成特定的任务。
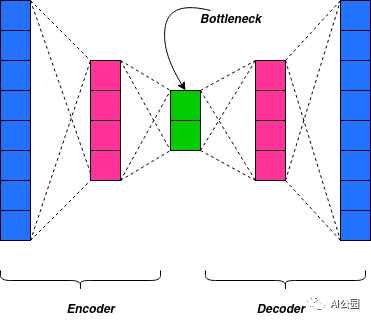
既然我们已经了解了自编码器,我们就可以将上下文编码器比作自编码器。上下文编码器是一种卷积神经网络,经过训练,根据周围环境生成任意图像区域的内容:即上下文编码器接收图像区域周围的数据,并尝试生成适合该图像区域的东西。就像我们小的时候拼拼图一样 —— 只是我们不需要生成拼图的碎片。
我们这里的上下文编码器由一个编码器和一个解码器组成,前者将图像的上下文捕获为一个紧凑的潜在特征表示,后者使用该表示来生成缺失的图像内容。由于我们需要一个庞大的数据集来训练一个神经网络,我们不能只处理修复问题图像。因此,我们从正常的图像数据集中分割出部分图像,创建一个修复问题,并将图像提供给神经网络,从而在我们分割的区域创建缺失的图像内容。
这里需要注意的是,输入到神经网络的图像有太多的缺失部分,经典的修复方法根本无法工作。
GAN的使用
GANs或生成对抗网络已被证明对图像生成极为有用。生成对抗网络运行的基本原理是:一个生成器试图“愚弄”一个鉴别器,一个确定的鉴别器试图区分出生成器生成的图像。换句话说,两个网络试图分别使损失函数最小化和最大化。
区域掩码
区域掩模是我们所屏蔽的图像的一部分,这样我们就可以将生成的修复问题提供给模型。通过屏蔽,我们将该图像区域的像素值设置为0。有三种方法:
中心区域:对图像数据进行遮挡,最简单的方法是将中心的正方形斑块设为零。虽然网络学习修复,但我们面临着泛化的问题。该网络不能很好地泛化,只能学习到低层次的特征。 随机块:为了应对网络“锁定”到掩码区域边界的问题,如在中央区域掩码中,掩码过程是随机的。不是选择一个单一的正方形贴片作为掩码,而是设置多个重叠的正方形掩码,最多占图像的1/4。 随机区域:然而,随机块掩蔽仍然有清晰的边界供网络捕捉。为了解决这个问题,任意的形状必须从图像中移除。可以从PASCAL VOC 2012数据集中获得任意形状,并在任意图像位置进行变形和作为掩模放置。

在这里,我只实现了中心区域掩蔽方法,因为这只是一个指南,让你开始用AI修复绘画。你可以尝试其他屏蔽方法,并在评论中告诉我结果!
结构
现在,你应该对模型有了一些了解。让我们看看你是否正确。
该模型由一个编码器和一个解码器部分组成,构建了模型的上下文编码器部分。这部分还充当生成数据和试图愚弄鉴别器的生成器。该鉴别器由卷积网络和一个最终给出一个标量作为输出的Sigmoid函数组成。
损失
模型的损失函数分为2部分:
1、重建损失:重建损失是L2损失函数。它有助于捕捉缺失区域的整体结构和与其上下文相关的连贯性。数学上,它被表示为:
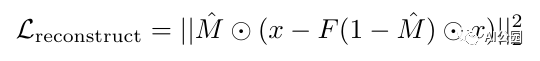
这里需要注意的是,仅使用L2损耗会使图像变得模糊。因为模糊的图像减少了平均像素的误差,因此L2损失是最小的,但这不是我们想要的。
2、对抗损失:这试图使预测“看起来”真实(记住生成器必须可以欺骗鉴别器!),这帮助我们在克服L2损失会导致我们得到模糊的图像。数学上,我们可以把它表示为:
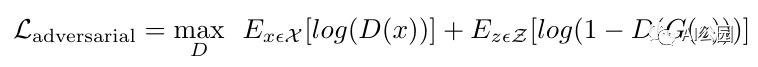
这里有一个有趣的观察:对抗损失鼓励整个输出看起来真实,而不仅仅是缺失的部分。换句话说,对抗性网络给了整个图像一个真实的外观。
总的损失函数:
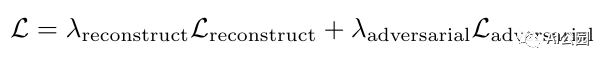
我们来构建这个模型!
现在,因为我们已经清楚了网络的主要的要点,让我们开始构建模型。我将首先建立模型结构,然后进入训练和损失函数部分。该模型使用PyTorch进行构建。
让我们从生成网络开始:
import torch
from torch import nn
class generator(nn.Module):
#generator model
def __init__(self):
super(generator,self).__init__()
self.t1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=(4,4),stride=2,padding=1),
nn.LeakyReLU(0.2,in_place=True)
)
self.t2=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2,in_place=True)
)
self.t3=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2,in_place=True)
)
self.t4=nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2,in_place=True)
)
self.t5=nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2,in_place=True)
)
self.t6=nn.Sequential(
nn.Conv2d(512,4000,kernel_size=(4,4))#bottleneck
nn.BatchNorm2d(4000),
nn.ReLU()
)
self.t7=nn.Sequential(
nn.ConvTranspose2d(in_channels=512,out_channels=256,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.t8=nn.Sequential(
nn.ConvTranspose2d(in_channels=256,out_channels=128,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.t9=nn.Sequential(
nn.ConvTranspose2d(in_channels=128,out_channels=64,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.t10=nn.Sequential(
nn.ConvTranspose2d(in_channels=64,out_channels=3,kernel_size=(4,4),stride=2,padding=1),
nn.Tanh()
)
def forward(self,x):
x=self.t1(x)
x=self.t2(x)
x=self.t3(x)
x=self.t4(x)
x=self.t5(x)
x=self.t6(x)
x=self.t7(x)
x=self.t8(x)
x=self.t9(x)
x=self.t10(x)
return x #output of generator
现在,是鉴别器网络:
import torch
from torch import nn
class discriminator(nn.Module):
#discriminator model
def __init__(self):
super(discriminator,self).__init__()
self.t1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=(4,4),stride=2,padding=1),
nn.LeakyReLU(0.2,in_place=True)
)
self.t2=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2,in_place=True)
)
self.t3=nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2,in_place=True)
)
self.t4=nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(4,4),stride=2,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2,in_place=True)
)
self.t5=nn.Sequential(
nn.Conv2d(in_channels=512,out_channels=1,kernel_size=(4,4),stride=1,padding=0),
nn.Sigmoid()
)
def forward(self,x):
x=self.t1(x)
x=self.t2(x)
x=self.t3(x)
x=self.t4(x)
x=self.t5(x)
return x #output of discriminator
现在让我们开始训练网络。我们将batch size设置为64,epoch的数量设置为100。学习速率设置为0.0002。
from model import generator, discriminator
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
from torch.autograd import Variable
from model import _netlocalD,_netG
import utils
epochs=100
Batch_Size=64
lr=0.0002
beta1=0.5
over=4
parser = argparse.ArgumentParser()
parser.add_argument('--dataroot', default='dataset/train', help='path to dataset')
opt = parser.parse_args()
try:
os.makedirs("result/train/cropped")
os.makedirs("result/train/real")
os.makedirs("result/train/recon")
os.makedirs("model")
except OSError:
pass
transform = transforms.Compose([transforms.Scale(128),
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset = dset.ImageFolder(root=opt.dataroot, transform=transform )
assert dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=Batch_Size,
shuffle=True, num_workers=2)
ngpu = int(opt.ngpu)
wtl2 = 0.999
# custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
resume_epoch=0
netG = generator()
netG.apply(weights_init)
netD = discriminator()
netD.apply(weights_init)
criterion = nn.BCELoss()
criterionMSE = nn.MSELoss()
input_real = torch.FloatTensor(Batch_Size, 3, 128, 128)
input_cropped = torch.FloatTensor(Batch_Size, 3, 128, 128)
label = torch.FloatTensor(Batch_Size)
real_label = 1
fake_label = 0
real_center = torch.FloatTensor(Batch_Size, 3, 64,64)
netD.cuda()
netG.cuda()
criterion.cuda()
criterionMSE.cuda()
input_real, input_cropped,label = input_real.cuda(),input_cropped.cuda(), label.cuda()
real_center = real_center.cuda()
input_real = Variable(input_real)
input_cropped = Variable(input_cropped)
label = Variable(label)
real_center = Variable(real_center)
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
for epoch in range(resume_epoch,epochs):
for i, data in enumerate(dataloader, 0):
real_cpu, _ = data
real_center_cpu = real_cpu[:,:,int(128/4):int(128/4)+int(128/2),int(128/4):int(128/4)+int(128/2)]
batch_size = real_cpu.size(0)
with torch.no_grad():
input_real.resize_(real_cpu.size()).copy_(real_cpu)
input_cropped.resize_(real_cpu.size()).copy_(real_cpu)
real_center.resize_(real_center_cpu.size()).copy_(real_center_cpu)
input_cropped[:,0,int(128/4+over):int(128/4+128/2-over),int(128/4+over):int(128/4+128/2-over)] = 2*117.0/255.0 - 1.0
input_cropped[:,1,int(128/4+over):int(128/4+128/2-over),int(128/4+over):int(128/4+128/2-over)] = 2*104.0/255.0 - 1.0
input_cropped[:,2,int(128/4+over):int(128/4+128/2-over),int(128/4+over):int(128/4+128/2-over)] = 2*123.0/255.0 - 1.0
#start the discriminator by training with real data---
netD.zero_grad()
with torch.no_grad():
label.resize_(batch_size).fill_(real_label)
output = netD(real_center)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.data.mean()
# train the discriminator with fake data---
fake = netG(input_cropped)
label.data.fill_(fake_label)
output = netD(fake.detach())
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.data.mean()
errD = errD_real + errD_fake
optimizerD.step()
#train the generator now---
netG.zero_grad()
label.data.fill_(real_label) # fake labels are real for generator cost
output = netD(fake)
errG_D = criterion(output, label)
wtl2Matrix = real_center.clone()
wtl2Matrix.data.fill_(wtl2*10)
wtl2Matrix.data[:,:,int(over):int(128/2 - over),int(over):int(128/2 - over)] = wtl2
errG_l2 = (fake-real_center).pow(2)
errG_l2 = errG_l2 * wtl2Matrix
errG_l2 = errG_l2.mean()
errG = (1-wtl2) * errG_D + wtl2 * errG_l2
errG.backward()
D_G_z2 = output.data.mean()
optimizerG.step()
print('[%d / %d][%d / %d] Loss_D: %.4f Loss_G: %.4f / %.4f l_D(x): %.4f l_D(G(z)): %.4f'
% (epoch, epochs, i, len(dataloader),
errD.data, errG_D.data,errG_l2.data, D_x,D_G_z1, ))
if i % 100 == 0:
vutils.save_image(real_cpu,
'result/train/real/real_samples_epoch_%03d.png' % (epoch))
vutils.save_image(input_cropped.data,
'result/train/cropped/cropped_samples_epoch_%03d.png' % (epoch))
recon_image = input_cropped.clone()
recon_image.data[:,:,int(128/4):int(128/4+128/2),int(128/4):int(128/4+128/2)] = fake.data
vutils.save_image(recon_image.data,
'result/train/recon/recon_center_samples_epoch_%03d.png' % (epoch))
结果
让我们看一下我们的模型能够构建出什么来?第0个epoch时候的图像(噪声):

第100个epoch时候:

我们看下输入模型的是什么:

英文原文:https://towardsdatascience.com/inpainting-with-ai-get-back-your-images-pytorch-a68f689128e5
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!