
ECCV2020 | CPNDet:Anchor-free两阶段的目标检测框架,详解
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
CPNDet
1 Introduction
2 Approach
2.1 CPN 网络框架
2.2 Inference 阶段
3 Experiments
4 Conclusion

论文地址:https://arxiv.org/abs/2007.13816
开源代码:https://github.com/Duankaiwen/CPNDet
其他解读:https://mp.weixin.qq.com/s/pPvDC_3SuGgZ2z6e5F8RDQ
本文亮点
提出了一种anchor-free两阶段的目标检测框架。
第一阶段的感兴趣区域是使用anchor-free来提取的,查找可能的角点关键点组合来提取多个候选目标object proposals。第二阶段是借鉴了一阶段中的角点组合进行提取proposal,使用两步分类器对proposal进行过滤,为每个候选object分配一个类别标签。
1 Introduction
本文提出了一种基于anchor-free的两阶段的角点目标检测器。第一阶段是通过角点提取出感兴趣区域,第二阶段是对感兴趣区域进行预测与回归。
提出这种方法,有两个论点:
为什么是基于anchor-free?——检测方法的召回率取决于它对不同几何形状的物体的定位能力,尤其是那些形状罕见的物体,而anchor-free方法(尤其是基于定位物体边界的方法)在这项任务中可能更好;
为什么要两阶段?——anchor-free方法通常会产生大量的误检,因此需要单独的分类器来提高检测精度。
基于CornerNet的关键点检测方法,但是并没有使用对关键点进行分组来实现目标检测;而是使用将所有有效的角点组合作为潜在对象,并且借用二阶段的思想,即训练一个分类器,根据对应的区域特征来区分真实物体和错误匹配的关键点。
分类器有两个步骤:
二元分类器,过滤掉不符合目标的proposal。
多元分类器,对仍存在的多个类别的目标分数进行排序。

图解:
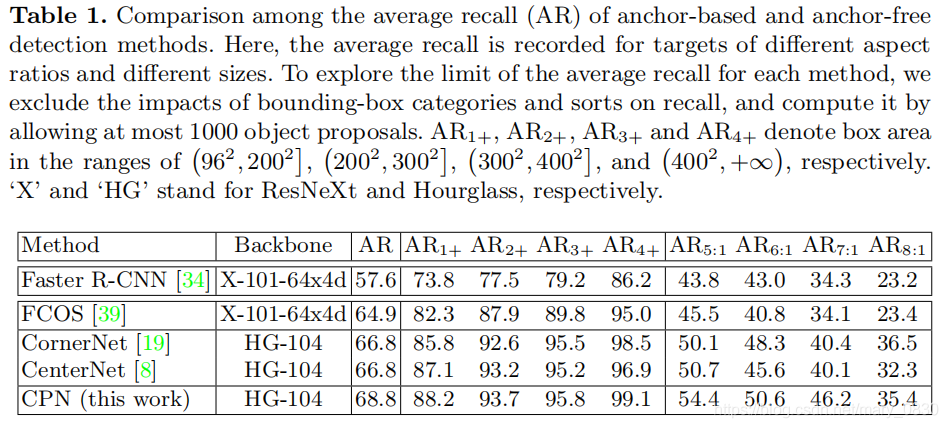
上图实验中,评估了四种目标提取proposal的方法。
第一行:基于anchor-based方法(faster rcnn)很难找到具有特殊形状的目标(比如大尺寸目标、目标的横纵比例很大),并且没有得到更高的召回率。
第二行:基于anchor-free方法(cornerNet)由于缺乏语义信息,可能会错误地将不相关的关键点分组到一个目标中,导致出现大量的错误检测。
绿色框表示true positives,蓝色框表示false positives,红色框表示false negatives。
2 Approach
作者的核心观点:
anchor-free定位方法具有更好地灵活性来定位任意几何形状的对象,可以获得较高的召回率。
由于anchor-free的方法可能会检测出大量的错误检测,因此需要采用二阶段的方法来过滤出错误检测。
基于anchor的方法是通过实验和经验设定锚点,因为是人为设置anchor,导致了算法不够灵活,也不能够对特殊形状的物体进行精确检测,容易发生漏检问题。
 图解:
图解:
基于anchor的faster rcnn的召回率较低,实验发现,对于纵横比为5:1、8:1等情况下,召回率特别低,甚至比anchor-free的方法都低,原因是:这种纵横比没有预定义anchor。
FCOS也存在类似的现象,FCOS是一种anchor-free方法,它通过关键点和到边界的距离来表示对象。当边界远离中心时,很难预测准确的距离。
实验发现,cornerNet和centerNet就没有这个问题,因为它是将关键点分组到一个对象中,解决了角点对距离的问题。
因此,本文作者选择了anchor-free的方法,特别是选择了角点对分组的方法来提高目标检测的召回率。
 图解:
图解:
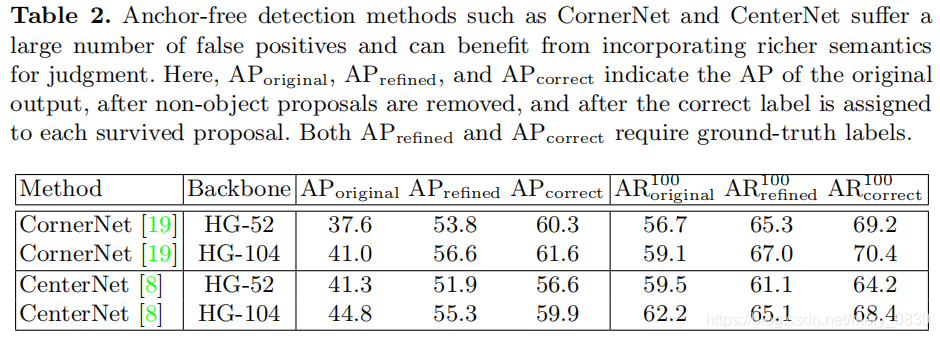
对比在anchor-free方法下,不同的backbone计算得到的AP和召回率的结果。
APoriginal AP_{original} APoriginal表示原始输出的AP, APrefined AP_{refined} APrefined表示删除非目标proposal之后的AP, APcorrect AP_{correct} APcorrect表示每个留下来的proposal正确分配标签后的AP。
实验表明,修正过后的AP和AR都得到了提高,因此说明这个想法的可行性。
参数说明:
I:原始图像区域
bn∗, n=1,2,…… , N:ground-truth bbox
cn∗, n=1,2,……, N:ground-truth 对应的类别
In∗, n=1,2,……, N:ground-truth 相对应边界框的图像区域
bm, m=1,2,……, M:定位目标的bbox
bm:定位目标对应的类别标签
2.1 CPN 网络框架
 图解:
图解:
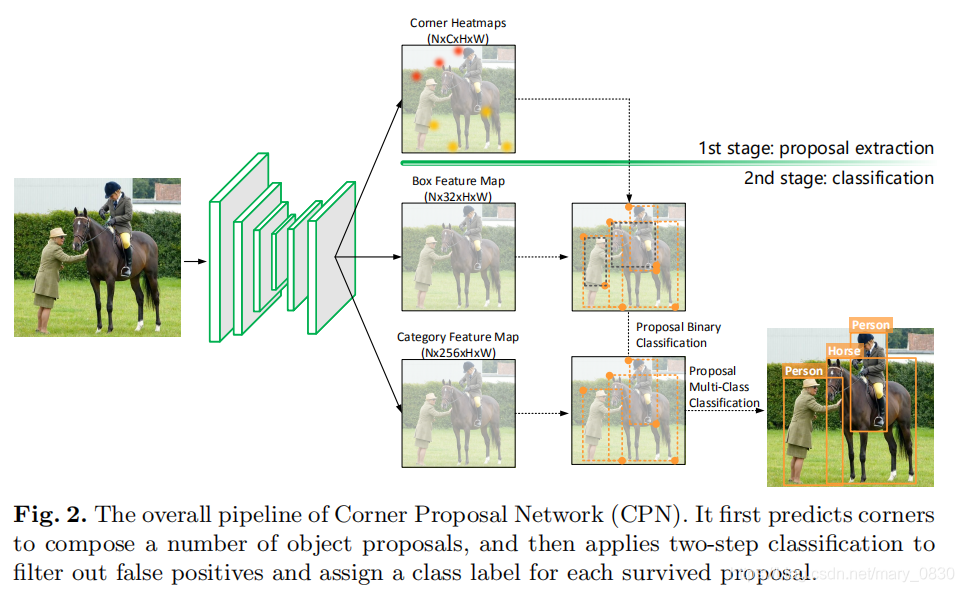
上图是本文提出的CPN的网络结构图。它使用anchor-free方法提取object proposal,然后进行有效的区域特征计算和分类以滤除误报。
第一步,先预测角点,组成多个目标proposal;
每个对象都有两个关键点(左上角和右下角)来确定其位置。 对于每一个类别,计算两个热图(热图上的每个值表示对应位置出现角点的概率),与原始图像相比分辨率降低了4倍。热图有两个loss:

分别表示热图上关键点损失(用于定位热图上的关键点)和热图中偏移损失(用于学习其偏移到准确的角点位置)。
对每一对有效的关键点定义一个目标的proposal(有效指的是两个关键点属于同一个类,且左上角的x和y坐标要分别小于右下角的x和y的坐标)。但是,这可能会导致大量的误报,因此把区分和分类交给二阶段来做。
第二步,使用两步分类过滤出错误检测,为每一个留下来的proposal分配一个类别标签。
用一种轻量级的二元分类器滤除掉80%的proposal(大量的非目标),然后用一个更精细的分类器来确定每个留下来的proposal的类别标签和置信度。
假设M是K个左上角和K个右下角关键点生成的目标proposal总数(基于centernet将 K设置为70,会使得每个图像上平均有2500个目标proposal)。因此,设计了一种两步分类过滤器。
两步分类器具体过程:
第一步: 训练一个二进制分类器,以确定每个proposal是否是一个目标对象。
首先采用卷积核大小为7×7的RoIAlign来提取每个proposal上的box特征。
然后通过32×7×7的卷积层得到每个proposal的分类分数。从而建立一个二元分类器。二分类的损失函数为:
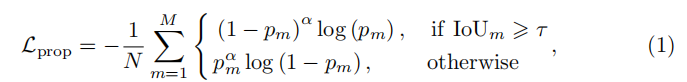
其中, N表示正样本的数量,pm∈[0,1],pm∈[0,1]表示第m个proposal的置信度分数,IoUm表示第m个proposal与所有gt bbox之间最大的IoU值。τ表示IoU的阈值(设置为0.7)。α=2表示平滑损失函数的超参数, π=0.1。
第二步: 为每个留下来的proposal分配一个类别标签。
使用C输出训练另一个分类器,其中C是数据集中类别的数目。
基于第一步提取的RoIAlign特征的基础上,从类别特征映射中提取特征以保留更多的信息,对于每一个留下来的proposal,使用256×7×7的卷积层获得 C C C维(表示类别)的向量。然后建立C−way分类器(为每个留下来的proposal建立单独的分类器),其损失函数为:

其中, M^和 N^分别表示留下来proposal的数量和在这其中正样本的数量。IoUm,c表示第m个proposal与第c个类别中所有gt bbox之间最大的IoU值。τ表示IoU的阈值保持不变(设置为0.7)。qm,c表示第 m m m个目标中第c个类别的分类分数。β=2与α=2相似的作用。
整个网络的损失函数为: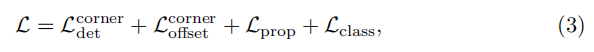
前两项表示关键点定位和偏移损失,后两项表示二分类和多分类的损失。
PS:
DeNet (《Denet: Scalable real-time object detection withdirected sparse sampling》)和本文的方法在想法上是相似的。不同之处在于,本文为每个角点配备一个多类别标签而不是一个二进制标签,因此本文的方法可以依靠类别标签消除不必要的无效角点对,以节省整个框架的计算成本;其次,本文使用一种额外的轻量级二进制分类方法减少分类网络要处理的proposal数量,而DeNet仅依赖一个分类网络。最后,本文的方法为两个分类器设计了一种新的focal损失函数变体,它不同于DeNet中的最大似然函数,这主要是为了解决训练过程中正样本和负样本之间的不平衡问题。
2.2 Inference 阶段
推理阶段与训练阶段类似,只是设置了阈值过滤掉低质量的proposals。由于proposals的预测分数都较低,因此选择了较低的阈值(这里设置为0.2),让更多的proposals都留下来。
当阈值设置为0.2时,平均保留下来的ROI大约占总量的20%,二分类所使用的计算量约为多分类计算量的10%,更凸显了第二阶段的优势。
对于保留在第二步的proposals,为其分配最多两个类别标签,对应于角点的主要类别和proposals的主要类别(两个类别可能不同,若不同时,proposal将成为两个得分可能不同的proposal)。
对于每个候选类别,使用 s 1 s_{1} s1表示角点分类分数(两个角点关键点的平均值,范围是(0,1)。若两个角点的分数不同,将两个角点的平均得分作为 s 1 s_{1} s1)。 s 2 s_{2} s2表示区域分类分数(多类别分类器预测的proposal类别标签的概率,范围是(0,1))。
通过公式计算最终的类别分数:s c = ( s 1 + 0.5 ) ( s 2 + 0.5 ) s_{c}=(s_{1}+0.5)(s_{2}+0.5) sc=(s1+0.5)(s2+0.5),最后将 s c s_{c} sc进行标准化到[0,1]。
最后,选取分数最高的100个proposals进行评估。
下图中,显示了两个分类器对CPN的检测性能对比。
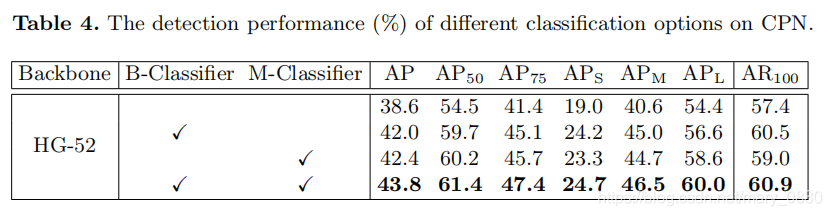
图解:由上表可知,两个分类器起到了信息互补的作用,使得检测精度大幅度的提升了。
3 Experiments
backbone: 52/104层的Hourglass网络
数据集: MS-COCO
框架: Pytorch
baseline: 基于CornerNet和CenterNet
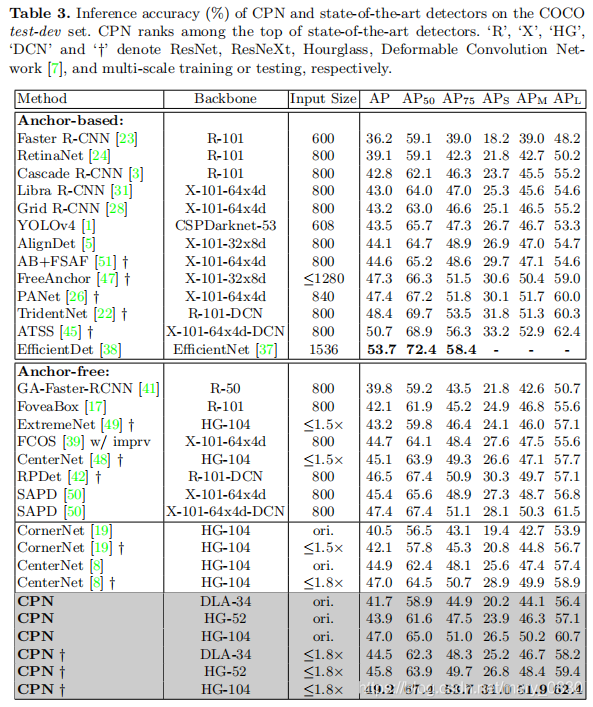
图解:
“R”、“X”、“HG”、“DCN”和“†”分别表示ResNet、ResNeXt、Hourglass、可变形卷积网络和多尺度训练或测试。
上图表示各个模型精度的对比。
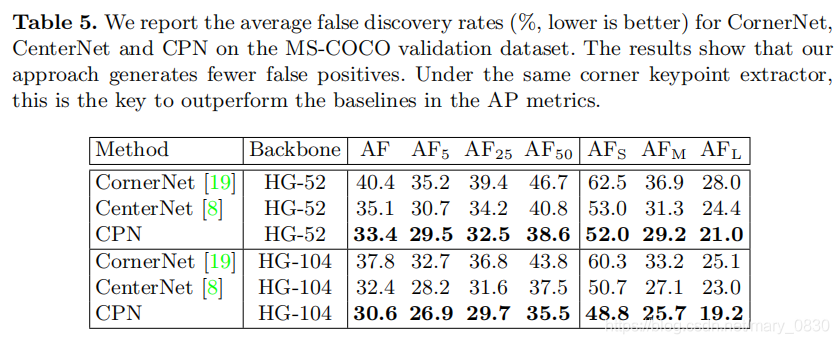
图解:
AF表示平均错误发现率,该值越低越好,表示错误检测的个数就越少。
CPN-52和CPN-104报告的AF分别为33.4%和30.6%,低于直接使用baseline:CornerNet和CenterNet。
AF=1−AP~
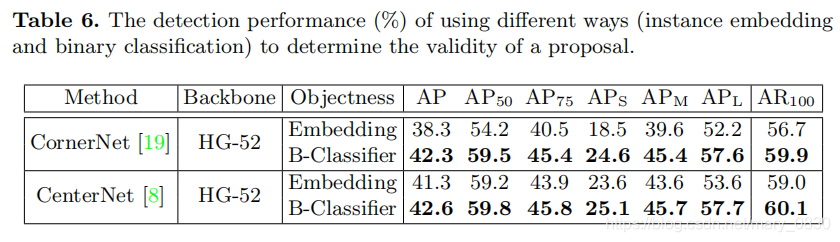
图解:
上图表示在两个不同的检测方法中加入同样的创新点,效果差别不大。

图解:
上图表示三种方法的检测结果图对比。从上至下分别是:CornerNet, CenterNet 和CPN。
绿色框表示true positive,红色框表示false positive。
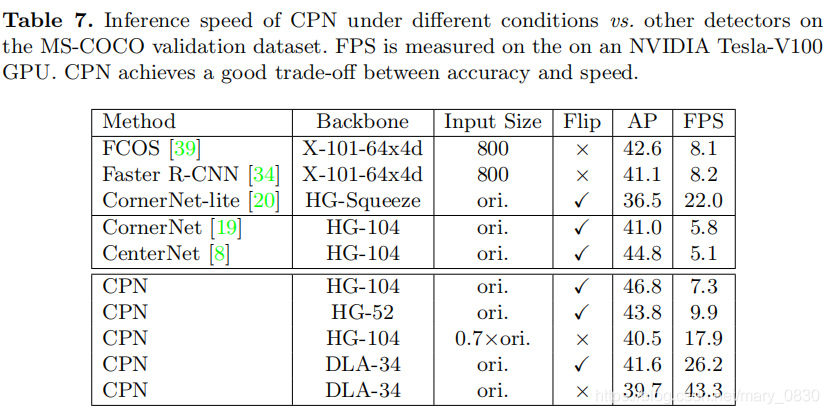
图解:
上图表示各个网络模型速度的对比。
在相同的设置下,CPN-104的FPS/AP为7.3/46.8% 比CenterNet-104 5.1/44.8%,速度极快,效果又好。
CPN-52的主干网较小,其FPS/AP为9.9/43.8%,同样也优于CornerNet52和CenterNet-52。
4 Conclusion
提出了一种anchor-free两阶段的目标检测框架。
基于anchor-free方法提取proposal更加灵活,通过两步分类方法进行预测。