
认识元学习 Meta Learning - 窥探通用型 AI
由于公众号修改了推送规则,请加星标,多点在看,以便第一时间收到推送。
〄机器学习与数学宣
深度学习在各个领域都取得了巨大的成功,并将继续展翅翱翔。但是训练传统的神经网络模型的一个主要问题是需要大量的数据,并且需要使用这些标签数据执行多次迭代更新。
让我们看一个经典的猫狗分类的例子。虽然在过去的二十年中,我们已经使模型的准确率越来越高,但上面提到的根本问题还是存在。我们仍然需要大量带标签的狗和猫图像来获得一定准确率。

人类是如何做到用很少的例子来实现分类的呢?假设突然有两种新的动物出现在你面前,它们就像猫和狗一样可以从视觉上区分开来。我很确定任何正常人都可以在少于 100 个例子中得到一个不错的准确率。为什么呢?多年来,我们已经了解了动物的基本结构。我们知道如何提取特征,例如脸型、毛发、尾巴、身体结构等等。简言之,我们已经学会了学习。
Meta Learning 的目的是学会学习,并以最小的数据量泛化 AI 使之适应很多不同的场景。你可能会说,这不是迁移学习做的同样事情么。是的,迁移学习的方向是对的,但它不能让我们走得足够远。我们观察到,当训练网络的任务偏离目标任务时,预训练网络的效益会大大降低。Meta Learning 建议将学习问题划分为两个层次。首先是在每个单独的任务中快速获取知识。这一层次是由第二个层次指导的,它包括从所有任务中缓慢提取学到的信息。Meta Learning 算法可以大致分为下面三类。
1基于梯度下降的方法
这类方法背后的直觉是再次使用标准梯度下降法更新已有神经网络,将其泛化到各种数据集上。
在这种方法中,我们使用一组数据集,每个数据集都有几个实例,我们称每个例子为 k 样本,用于 k-样本学习。设数据集为
我们希望我们的模型能泛化到各类数据集上。所以,我们需要更新参数后的模型在 p(T) 中所有数据集的误差总和。这可以用数学方式表示,
对于
我们可以看到,通过模型的梯度反向传播 Meta 损失涉及计算导数的导数。这可以使用例如 TensorFlow 中支持的 Hessian 矩阵和向量的乘积来实现。
2最近邻法
这套方法基于如下事实: 最近邻法不需要训练,但其性能取决于所选择的度量。
它们由将输入域映射到特征空间的嵌入模型以及将特征空间映射到任务变量的基础学习器组成。Meta Learning的目标是学习一种嵌入模型,以便基础学习器能够出色地泛化到各个任务上。在此,基于嵌入的基于距离的预测规则。我们来看一个被称为匹配网络的具体例子以了解其工作原理。
匹配网络支持将图像标签对
其中,
上述方法让人联想到 KDE 和 kNN 算法。
3基于模型的方法
我们人脑,在处理东西的同时,也储存了它的表示以备后用。这类算法试图通过一些辅助记忆块来模仿人类。基本策略就是学习将表示的类型放入记忆块,以及以后应该如何使用这些表示进行预测。
在这些方法中,输入序列和输出标签是按顺序给定的。一个数据集
在这个具体的实现中,我们将要讨论的记忆模块是神经图灵机(NTM)。它基本上是一台图灵机(内存块上的读写头),带有基于LSTM(有时是简单的神经网络)的控制器。NTM 外部内存模块中的内存编码和检索速度非常快,在每一个时间步长中都可能将向量表示放入或取出内存。这种能力使 NTM 成为 Meta Learning 和低概率预测的完美候选者,因为它既可以通过缓慢更新其权重进行长期存储,也可以通过外部存储模块进行短期存储。
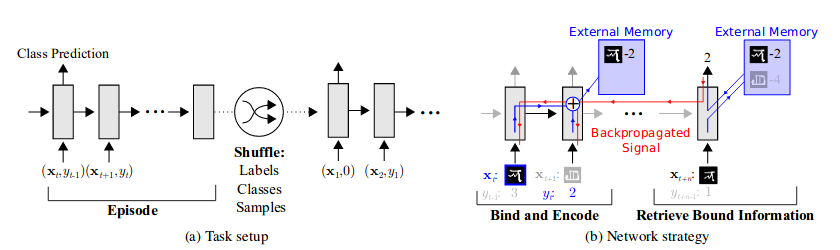
在一些时间步长
Softmax 用于产生读写向量。
这是用于获取内存
它用作下一个控制器状态的输入,以及基于 softmax 的分类器的输入。
元学习是目前机器学习领域中一个令人振奋的研究热点。本篇简要介绍了三类方法,让大家快速对元学习有个总体印象,具体的研究内容等待后续展开。
⟳参考资料⟲
英文链接: https://towardsdatascience.com/meta-learning-ai-generalised-1007b9695fe1