小扎下血本!Meta专为元宇宙搞了个AI模型
共
1852字,需浏览
4分钟
·
2022-07-31 05:39
【新智元导读】专门为元宇宙打造的AI框架,是什么样子的?
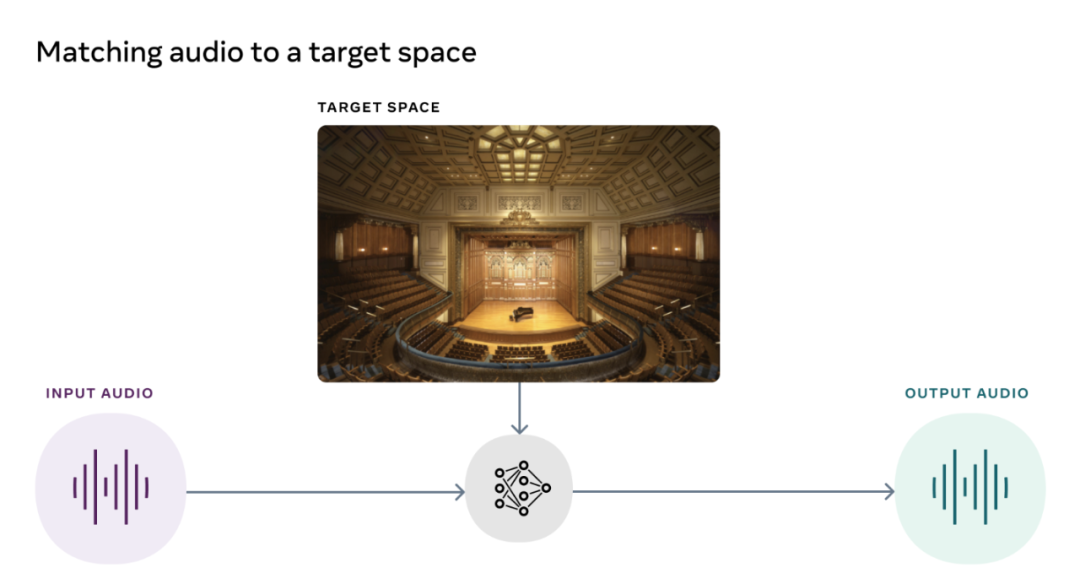
人工智能在元宇宙中可与多种相关技术结合,如计算机视觉、自然语言处理、区块链和数字双胞胎。2月,扎克伯格在该公司的第一个虚拟活动——Inside The Lab中展示了元宇宙的样子。他说,该公司正在开发一系列新的生成式AI模型,用户只需通过描述就可以生成自己的虚拟现实化身。扎克伯格宣布了一系列即将推出的项目,例如CAIRaoke项目,一项用于构建设备语音助手的完全端到端的神经模型,可帮助用户更自然地与语音助手进行交流。同时,Meta正努力构建一个通用语音翻译器,可为所有语言提供直接的语音到语音翻译。然而,Meta并不是唯一一家在游戏中拥有皮肤的科技公司。英伟达等公司也发布了其自主研发的AI模型以提供更丰富的元宇宙体验。开源预训练Transformer(OPT-1750亿参数)GANverse 3D由英伟达AI Research开发,是一种使用深度学习将2D图像处理成3D动画版本的模型,去年的ICLR和CVPR上发表的一篇研究论文中介绍了该工具,它可以用更低的成本更快地生成模拟。该模型使用StyleGAN可自动从单个图像生成多个视图。该应用程序可以作为NVIDIA Omniverse的扩展导入,以在虚拟世界中准确地渲染3D对象。英伟达推出的Omniverse可帮助用户在虚拟环境中创建他们最终想法的模拟。3D模型的制作已成为构建元宇宙的关键因素。耐克和Forever21等零售商已经在元宇宙建立了他们的虚拟商店,以推动电子商务销售。Meta的现实实验室团队与德克萨斯大学合作,建立了一个人工智能模型,以改善元空间的声音质量。该模型帮助匹配场景中的音频和视频。它对音频片段进行转换,使其听起来像是在特定环境中录制的。该模型在从随机的在线视频中提取数据后使用了自我监督学习。理想情况下,用户应该能够在他们的AR眼镜上观看他们最喜欢的记忆,并聆听实际体验中产生的确切声音。Meta AI发布了AViTAR的开源,同时还发布了其他两个声学模型,考虑到声音是metaverse体验中经常被忽视的部分,这是非常罕见的。Meta AI发布的第二个声学模型被用来去除声学中的混响。该模型是在一个大规模的数据集上训练出来的,该数据集有各种来自家庭三维模型的真实音频渲染。混响不仅降低了音频的质量,使其难以理解,而且还提高了自动语音识别的准确性。
VIDA的独特之处在于,它在使用视觉线索的同时也使用音频方式进行观察。在典型的仅有音频的方法的基础上进行改进,VIDA可以增强语音,并识别语音和说话者。Meta AI发布的第三个声学模型VisualVoice可以从视频中提取语音。与VIDA一样,VisualVoice也是根据未标记的视频中的视听线索进行训练。该模型已经自动分离了语音。
这个模型有重要的应用场景,如为听障人士制作技术,增强可穿戴AR设备的声音,从环境嘈杂的在线视频中转录语音等。去年,英伟达发布了Omniverse Audio2Face的开放测试版,以生成人工智能驱动的面部动画,以匹配任何配音。该工具简化了为游戏和视觉效果制作动画的漫长而繁琐的过程。该应用还允许用户以多种语言发出指令。
今年年初,英伟达发布了该工具的更新,增加了BlendShape Generation等功能,帮助用户从一个中性头像中创建一组blendhapes。此外,还增加了流媒体音频播放器的功能,允许使用文本到语音应用程序的音频数据流。Audio2Face设置了一个3D人物模型,可以用音轨做动画。然后,音频被送入一个深度神经网络。用户还可以在后期处理中编辑角色,改变角色的表现。https://analyticsindiamag.com/ai-models-built-for-the-metaverse/
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报






 下载APP
下载APP