
田渊栋团队&UC伯克利新作:从第一性原理出发,多智能体协作该如何建模
新智元报道
新智元报道
来源:知乎
编辑:SF
【新智元导读】本文主要想解决的问题是,如何更好地在复杂环境下同时训练多个智能体相互协作,并且让它们在未重新训练的情况下,自动适应环境和其它智能体的变化。
这是田渊栋老师团队在多智能体强化学习上的一篇新的工作,是Facebook AI Research和UC Berkeley合作的,由BAIR Open Research Commons支持,代码已开源。
GitHub链接:
https://github.com/facebookresearch/CollaQ
原文地址:https://arxiv.org/abs/2010.08531
那么到底是如何做到的呢?
我们试图从第一性原理出发,思考多智能体协作应当如何建模。
首先,如果我们不做任何思考,把多智能体协作当成单智能体建模,会发生什么事呢?
在这种情况下,假设我们有K个智能体,考虑值函数  。
。
理想情况下,有了这个值函数,那么每时每刻每个智能体的下一步最优行动,就能通过最大化这个值函数来找到。
实际情况下没人这么用,因为有以下的三点问题:
 的样本复杂度是指数级的;
的样本复杂度是指数级的;- 无法做到分布式执行(Decentrized Execution),也即是说,对某个智能体来说,寻找自己的最优行动时,需要知道所有其它智能体的状态。在实际情况中这个就需要有中央总控制,不满足分布式的条件;
- 在使用时,无法自动适应环境和其它智能体的变化。
那要怎么才能解决这个问题呢?
一个自然的想法是往深里想一想,智能体之间为什么要协作?
在利益相同的情况下,我们假设协作的原因是因为存在“你帮我做任务A方便,而我帮你做任务B方便”这样的情况。
这就引出了如下的最大化目标函数:
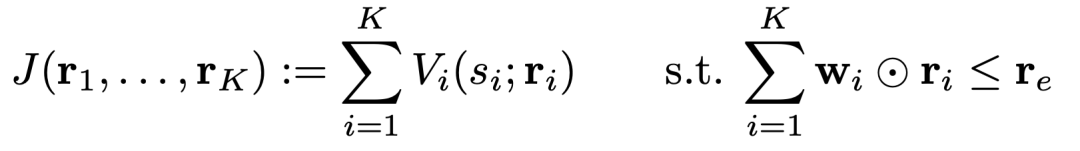
其中  是第i个智能体的值函数。注意这个值函数是依赖于第i个智能体被委派的任务(或者奖励
是第i个智能体的值函数。注意这个值函数是依赖于第i个智能体被委派的任务(或者奖励  )的,在文中我们叫它perceived rewards。
)的,在文中我们叫它perceived rewards。
不同的委派奖励 ,对应的值函数也不同,当然智能体的行为也会不同。  是总的外部奖励,目标函数中的约束是希望委派奖励的加权和不要超过外部奖励(不然所有的值函数都会奔着正无穷而去)。
是总的外部奖励,目标函数中的约束是希望委派奖励的加权和不要超过外部奖励(不然所有的值函数都会奔着正无穷而去)。

我们假设,每个智能体之所以会和别人协作,完全是因为委派的奖励不同。换种说法,有了委派奖励,智能体眼里就盯着奖励去了,再不用管其它智能体在干什么。
这样听起来,就通过委派奖励这个中间变量,把智能体之间的行为,在形式上解耦了。这就是为什么会有对 求和的目标函数出现。
不同的委派奖励,就会对应不同智能体的行为。那我们想要找的,当然是最优的委派奖励  ,让智能体间的协作效益最大化。
,让智能体间的协作效益最大化。

但这样问题就来了,要解出最优委派奖励 ,还需要知道当前所有智能体的状态。这样不就绕圈子回去了吗?
但幸运的是,在满足某些条件的情况下,对于第i个智能体,我们找到一个近似最优的委派奖励  ,满足以下两条。
,满足以下两条。
其一,它离最优解比较近;
其二,它只依赖于第i个智能体及其附近其它智能体的状态。
有了前者,委派奖励就不是无的放失,有了后者,分布式执行就有了保障。
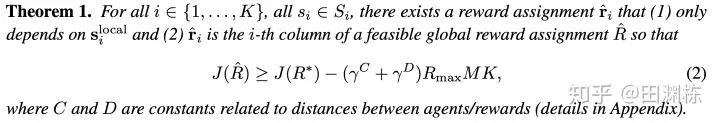
知道这个“近似最优解”的存在性之后,我们并不显式将其算出(因为这个代价仍然太大),而是利用这个结构,对第i个智能体的Q函数做相应的分解。
具体来说,利用在委派奖励上的泰勒展开,我们可以得到这样的分解:
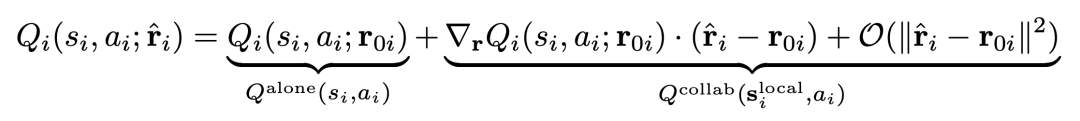
第一项叫作  ,也即假设所有其它智能体都不存在情况下的Q值;第二项叫作
,也即假设所有其它智能体都不存在情况下的Q值;第二项叫作  ,只建模当前智能体和其它人的交互。
,只建模当前智能体和其它人的交互。
第一项只用当前智能体状态作为输入特征,以减少样本复杂度;第二项则加入正则项(MARA Loss),让它在只观察到当前智能体的时候,取值为零。
实验表明,这个加进去的正则项极大提高了性能,间接印证了理论分析。
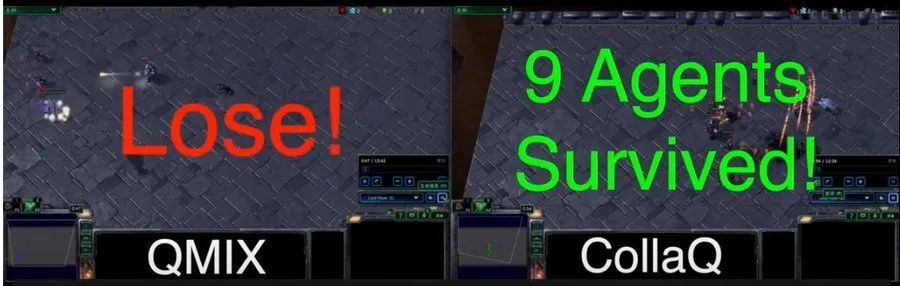
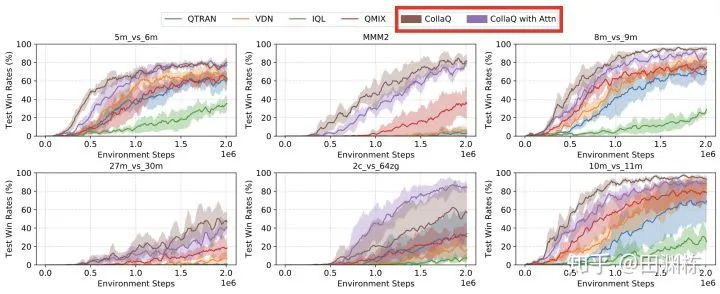
通过这样的分解,我们得到了CollaQ。CollaQ在一些多智能体星际争霸的“极度困难”(super-hard)任务上得到了相当不错的效果。
比如说在MMM2这类需要复杂多兵种(Marine,医疗船,光头兵)合作的情况下,CollaQ仅用2M的步数(environment step)就达到了80%以上的胜率,显示出它更有效的训练样本利用率。
有一局我们甚至看到它通过精妙的微操,把电脑打得溃不成军,在全歼对方之后,已方还能剩9个兵(见youtu.be/NyT8njh4cj4)
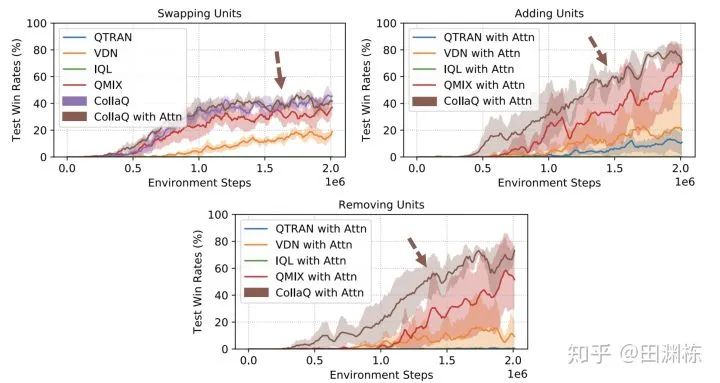
另外如前所说,CollaQ训练出来的AI,在变化环境或者增多、减少、及替换智能体的情况下也有不错的表现。
代码已开源,欢迎大家使用!
3分钟简介视频:https://link.zhihu.com/?target=http%3A//yuandong-tian.com/collaQ.mp4

