
用多模态世界模型预测未来!UC伯克利全新AI智能体,精确理解人类...

来源:新智元
本文约2000字,建议阅读5分钟
UC伯克利的研究人员提出了一种全新的AI智能体,可以通过对未来进行多模态世界建模来学习理解语言。

[ 导读 ] 智能体如何从不同的语言中理解世界?近日,来自UC伯克利的研究人员提出了一种全新的AI智能体,可以通过对未来进行多模态世界建模来学习理解语言。
现在,基于强化学习的智能体已经可以轻松地执行诸如「捡起蓝色积木」这类的指令。
但人类大部分时间的语言表达,却远远超出了指令的范围。比如:「我们好像没有牛奶了」......
而智能体想要学习这类语言在世界中的含义,是非常困难的。
对此,来自UC伯克利的研究团队认为,我们实际上可以利用这些语言,来帮助智能体更好地对未来进行预测。
 论文地址: https://arxiv.org/pdf/2308.01399.pdf
论文地址: https://arxiv.org/pdf/2308.01399.pdf
具体来说,研究人员提出了一种全新的智能体——Dynalang。
与仅用语言预测动作的传统智能体不同,Dynalang通过使用过去的语言来预测未来的语言、视频和奖励,从而获得丰富的语言理解。
除了在环境中的在线交互中学习外,Dynalang还可以在没有动作或奖励的情况下在文本、视频或两者的数据集上进行预训练。

也就是说,新的智能体这时再听到「我们没有牛奶了」,就能get到这句话意思是「冰箱里的牛奶喝完了」。
工作原理
使用语言来理解世界自然而然地适合于世界建模范式。
Dynalang以基于模型的RL智能体DreamerV3为基础,并可利用其在环境中动作时所收集到的经验数据,不断地进行学习。
左:世界模型在每个时间步将文本和图像压缩为潜在表征。在这个表征中,模型被训练以重构原始观察结果,预测奖励,并预测下一个时间步的表征。直观地说,世界模型学会了在给定文本中所读内容的情况下,应该期望在世界中看到什么。
右:Dynalang通过在压缩的世界模型表征基础上训练策略网络来选择动作。它在世界模型的想象中反复进行训练,从而学会采取最大化预测奖励的动作。
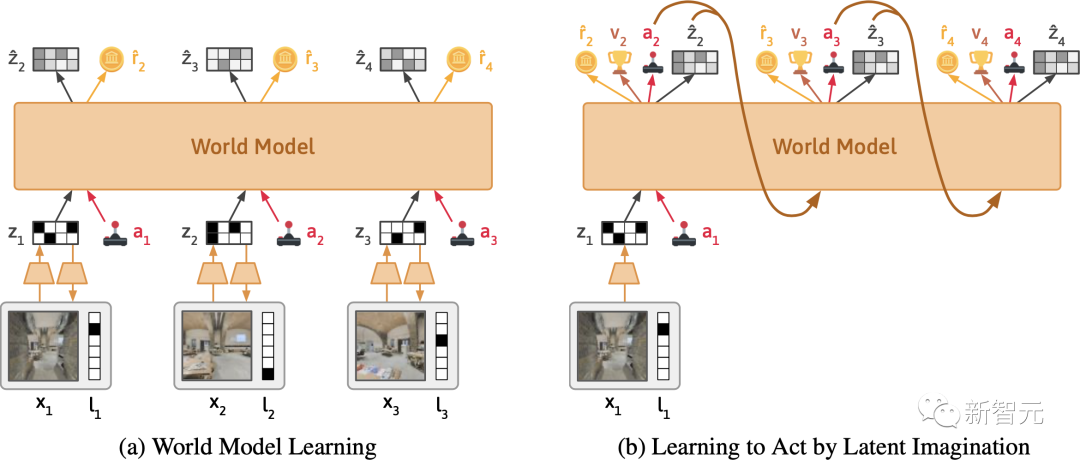
与之前一次处理一个句子或段落的多模态模型不同,Dynalang将视频和文本作为一个统一的序列进行建模,一次处理一个图像帧和一个文本token。
直观地说,这更像是人类在现实世界中接收输入的方式。
将所有内容都建模为一个序列,就 可以像语言模型一样在文本数据上进行预训练,从而提高强化学习的性能。
语言提示
为了评估智能体在环境中的表现,研究人员引入了HomeGrid。其中,智能体除了任务指令外,还会收到语言提示。
HomeGrid中的提示,不仅模拟了智能体可能从人类那里学到的知识或从文本中读到的信息,而且还提供了有用但不是解决任务所必需的信息:
-
「未来观察」:描述智能体在未来可能观察到的情况,例如「盘子在厨房里」。
-
「纠正」:根据智能体正在执行的任务的提供交互式反馈,例如「转过身去」。
-
「动态」:描述环境的动态,例如「踩踏板打开堆肥箱」。
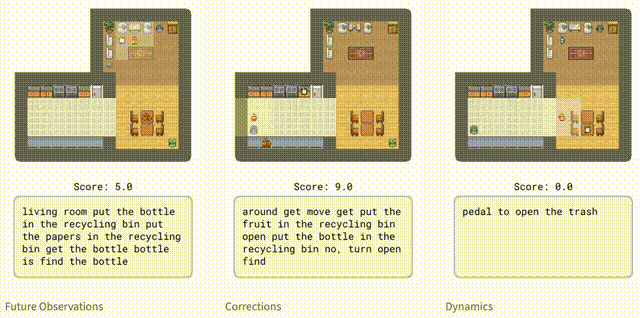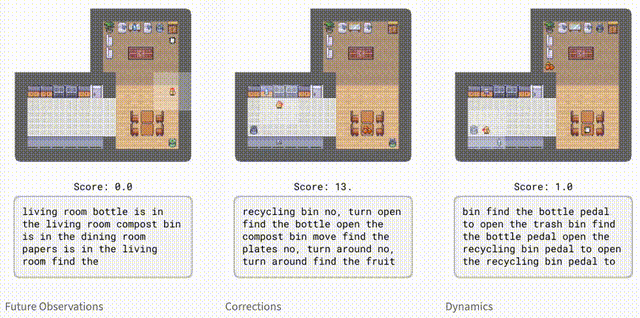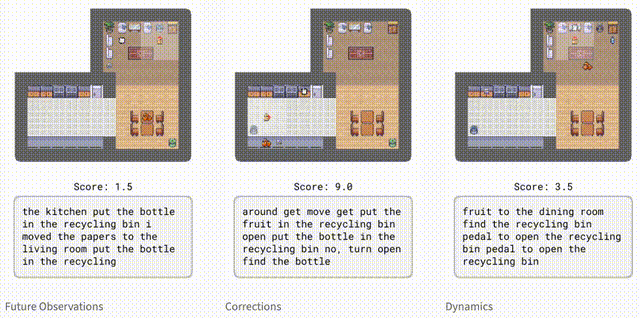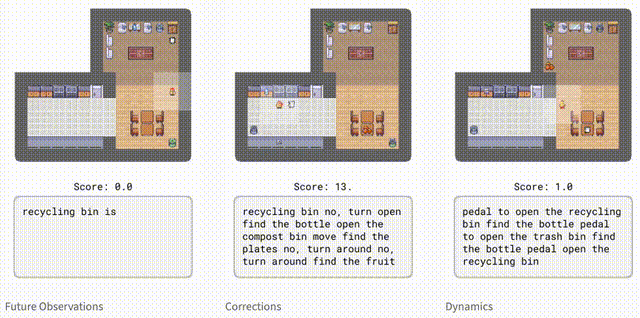
虽然智能体并未接受过明确的指导来分辨观察结果和文本的对应关系。但Dynalang仍能通过未来的预测目标,学会将各种类型的语言与环境联系起来。
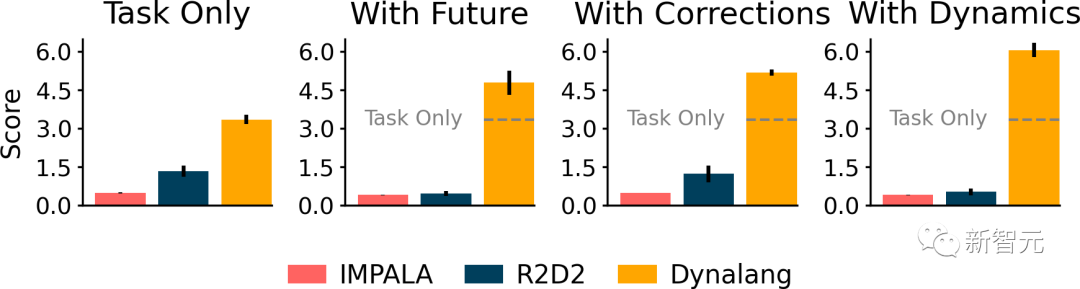
结果显示,Dynalang要明显优于以语言为条件的IMPALA和R2D2。
后者不仅在使用不同类型的语言时非常吃力,而且在使用指令以外的语言时表现得更差。
游戏评估
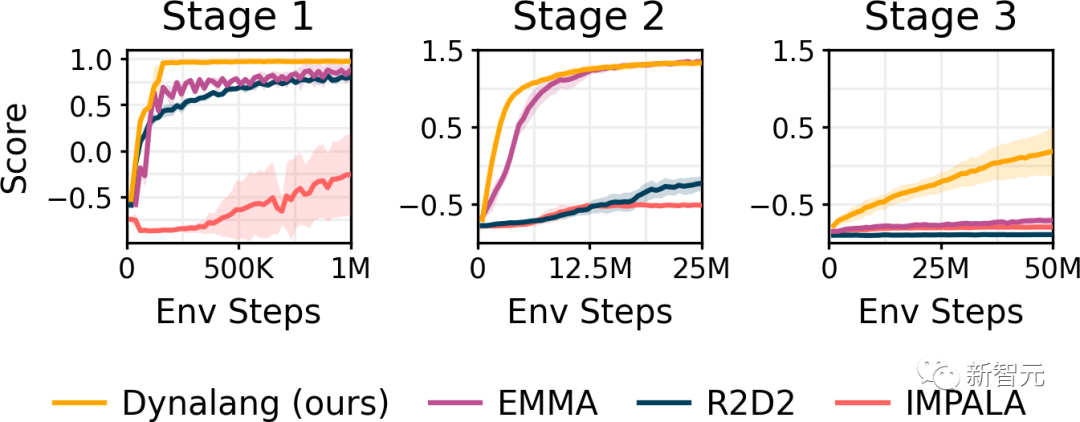
在Messenger游戏环境中,研究人员测试了智能体是如何从较长且更复杂的文本中学习的,这需要在文本和视觉观察之间进行多跳推理。
智能体必须对描述每个情节动态的文本说明进行推理,并将其与环境中的实体观察结合起来,以确定从哪些实体获取消息和避开哪些实体。
结果显示,Dynalang的表现要明显优于IMPALA和R2D2,以及使用专门架构对文本和观察结果进行推理任务优化的EMMA基准,尤其是在最困难的第3阶段。
指令跟随
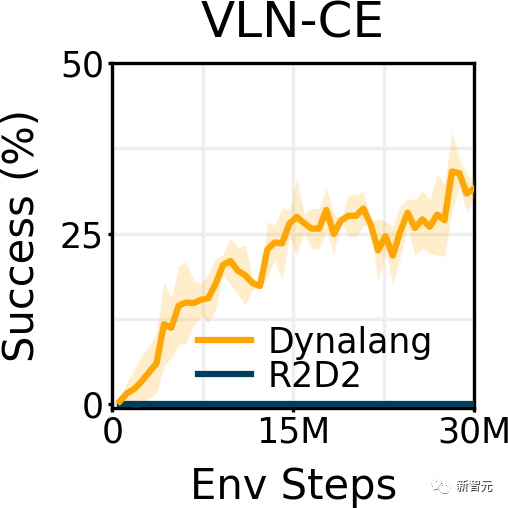
Habitat的测试结果表明,Dynalang能够处理逼真的视觉观察并执行指令。
也就是,智能体需要按照自然语言的指令,导航到家中的目标位置。
在Dynalang中,指令跟随可以通过将其视为未来奖励预测,来在相同的预测框架中统一处理。

语言生成
就像语言会影响智能体对所见事物的预测一样,智能体观察到的事物也会影响它期望听到的语言(例如,关于所见事物的真实陈述)。
通过在LangRoom中将语言输出到动作空间中,Dynalang可以生成与环境相关联的语言,从而执行具体的问题回答。
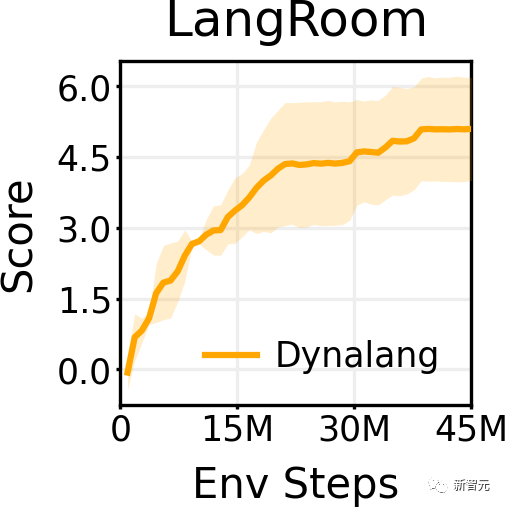

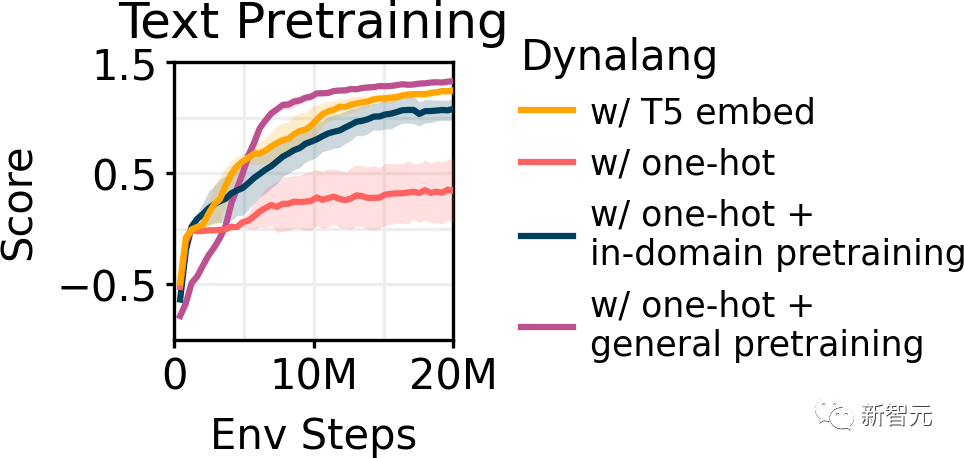
文本预训练
由于使用语言建立世界模型与使用世界模型学习动作是分开的,因此Dynalang可以在没有动作或奖励标签的情况下使用离线数据进行预训练。
这种能力使Dynalang能够从大规模的离线数据集中受益,所有这些数据集都在单一模型架构内。
研究人员使用纯文本数据对Dynalang进行预训练,并从头开始学习token嵌入。
模型在通用文本数据(TinyStories,200万个短故事)上进行预训练之后,可以提高Messenger下游RL任务的表现,甚至超过了使用预训练的T5嵌入。
尽管这项工作的重点是让智能体能够理解语言并采取行动,但其实也可以像纯文本语言模型一样生成文本。
研究人员在潜空间中对预训练的TinyStories模型进行了抽样推演,并在每个时间步骤从表征中解码出token观察。
结果显示,模型生成的结果具有令人惊讶的一致性,不过在质量上仍然低于SOTA的语言模型。
不过由此也可以看出,将语言生成和行动统一到单一的智能体架构中,是一个很有趣的研究方向。

作者介绍

论文一作Jessy Lin,是加州大学伯克利分校人工智能研究院(Berkeley AI Research)的三年级博士生,由Anca Dragan和Dan Klein指导。
她的研究方向是构建能与人类合作和互动并以语言为媒介的智能体。此外, 她还对对话以及语言+强化学习非常感兴趣。目前,她的研究得到了苹果人工智能奖学金的支持。
她在麻省理工学院获得了计算机科学和哲学双学位。在那里,她与计算认知科学小组合作,在Kelsey Allen和Josh Tenenbaum的指导下进 行人类启发式人工智能研究,同时作为labsix的创始成员从事机器学习安全研究。
此外,她还曾在Lilt从事人机协作机器翻译/专家翻译的Copilot研究和产品开发。
参考资料:
https://dynalang.github.io/