导读:寻找深度学习的普适理论一直是学界关注的焦点。在深度学习的工作中,我们常常使用许多经验性的方法,例如选择不同的非线性层,样本的归一化,残差链接,卷积操作等等。这样的方法为网络带来了优秀的效果,经验性的理解也为深度学习发展提供了指导。但似乎我们对其理解仅限于此,由于网络的黑盒性质,这些方法究竟从理论上如何工作,为何需要加入网络,我们似乎难以回答。 近日UC Berkeley的马毅教授的报告“Deep Networks from First Principle”提供了一种系统性的理论观点。 报告中,马毅教授阐述了最大编码率衰减(Maximal Coding Rate Reduction, MCR^2)作为深度模型优化的第一性原理的系列工作。此外,马毅介绍了近期的工作:通过优化 MCR^2 目标,能够直接构造出一种与常用神经网络架构相似的白盒深度模型,其中包括矩阵参数、非线性层、归一化与残差连接,甚至在引入「群不变性」后,可以直接推导出多通道卷积的结构。该网络的计算具有精确直观的解释,受到广泛关注。 正如费曼所说「What I cannot create I do not understand」。该工作表明,为了学习到线性划分的样本表示,所有这些常用方法都能够精确推导出来,都是实现该目标所必须的。因此,通过该工作,可以更加直观细致地理解神经网络中的常用方法。 本文整理自该报告的部分内容,原报告链接如下:https://www.youtube.com/watch?v=z2bQXO2mYPo
深度学习的第一性原理
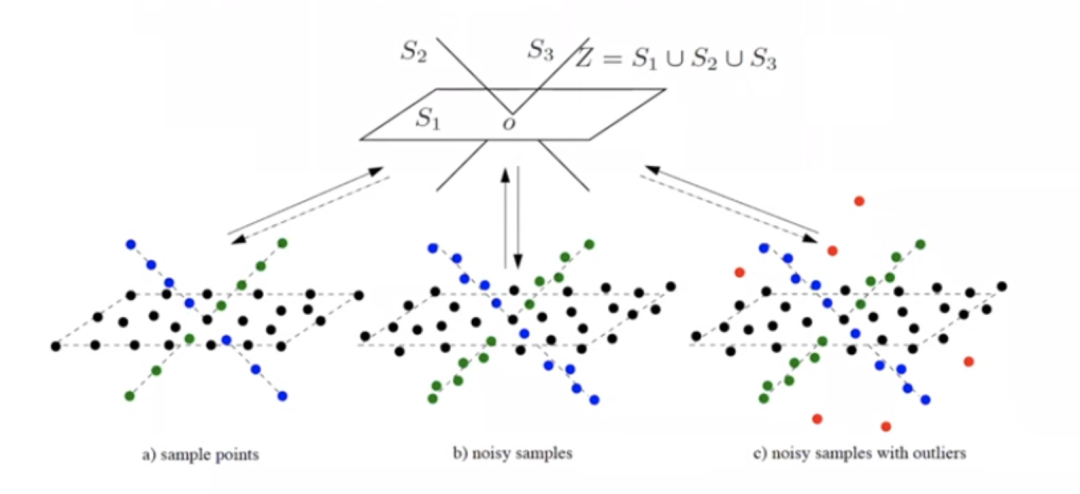
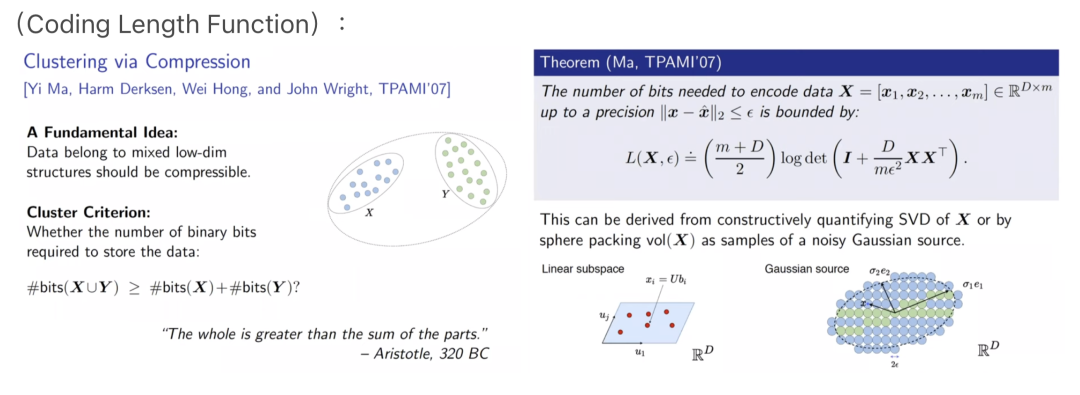
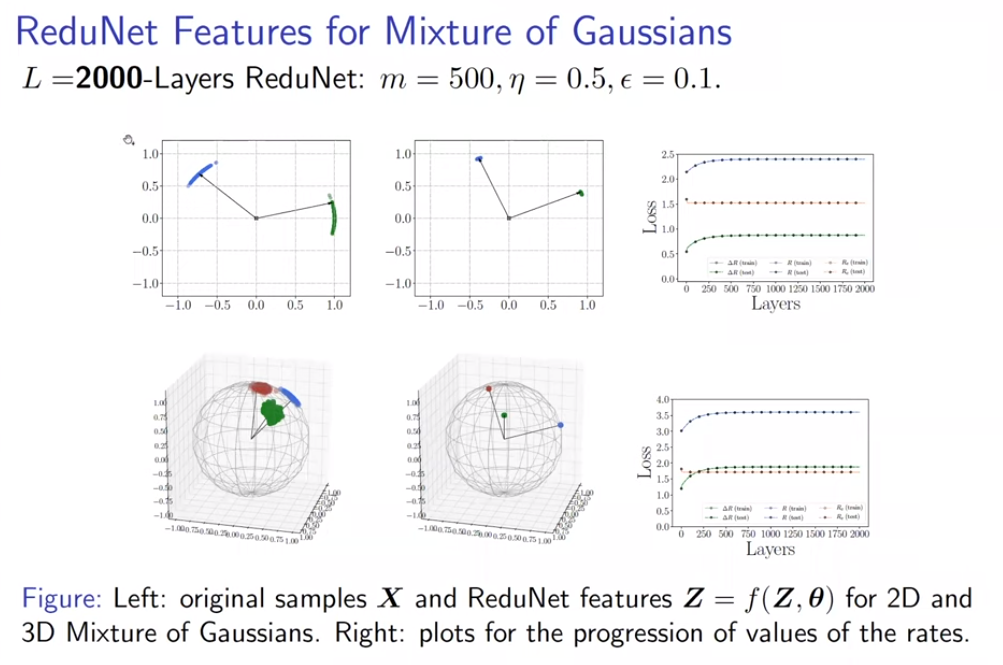
Learn to Compress, Compress to Learn!——马毅 聚类和分类是两种主要的目标,很多任务都可以归类为将数据划分成不同的部分。马毅教授提出,分类和聚类代表的学习任务,与数据压缩(Compression)有关,而这样的任务,通常是在寻找高维目标的低秩结构,且深度网络能够适应于这样的压缩场景。 我们引入一个假设,在数据处理中,通常面对的是具有低维结构的高维数据。在这样的情况下,学习的目标通常会包含三个基本问题:
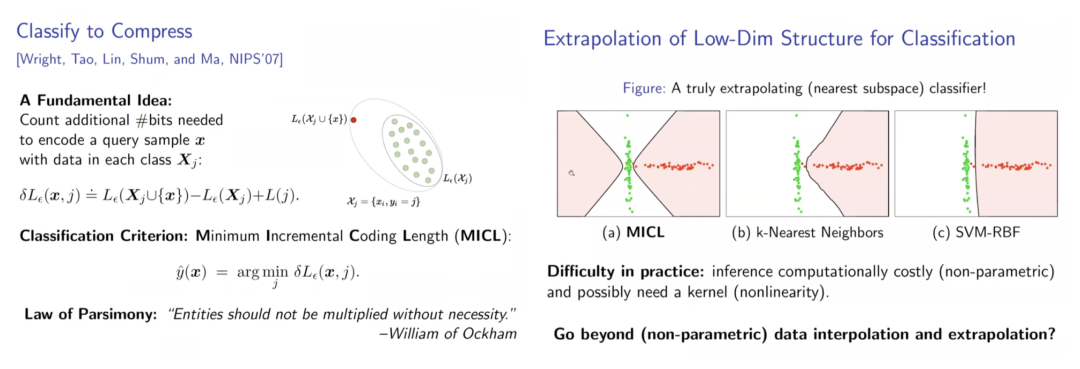
深度学习则将上述数据分析的任务“塞”进黑箱运算中。例如在神经网络分类任务中,我们将输入与输出的标签相互对应,然而足够大的深度网络能够拟合任何给定标签。 尽管在实践中取得了很好的效果,但是理论上来说,训练深度神经网络并不能保证稳定和最优,且我们无法从中了解到模型究竟学到了什么。 IB Theory 提供了一种理解方法,但是,从信息视角理解网络会碰到一个问题,即在高维数据上,传统信息论的统计量是无法定义的,高维数据常常是退化分布的,无法完成有效测量。
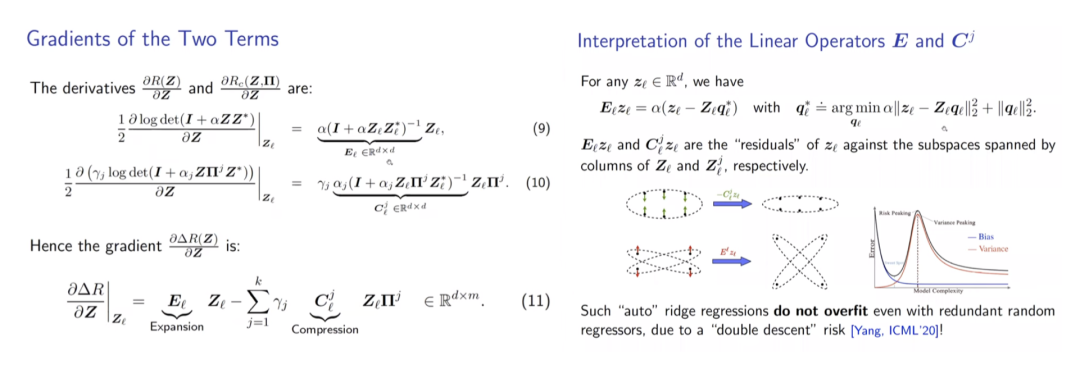
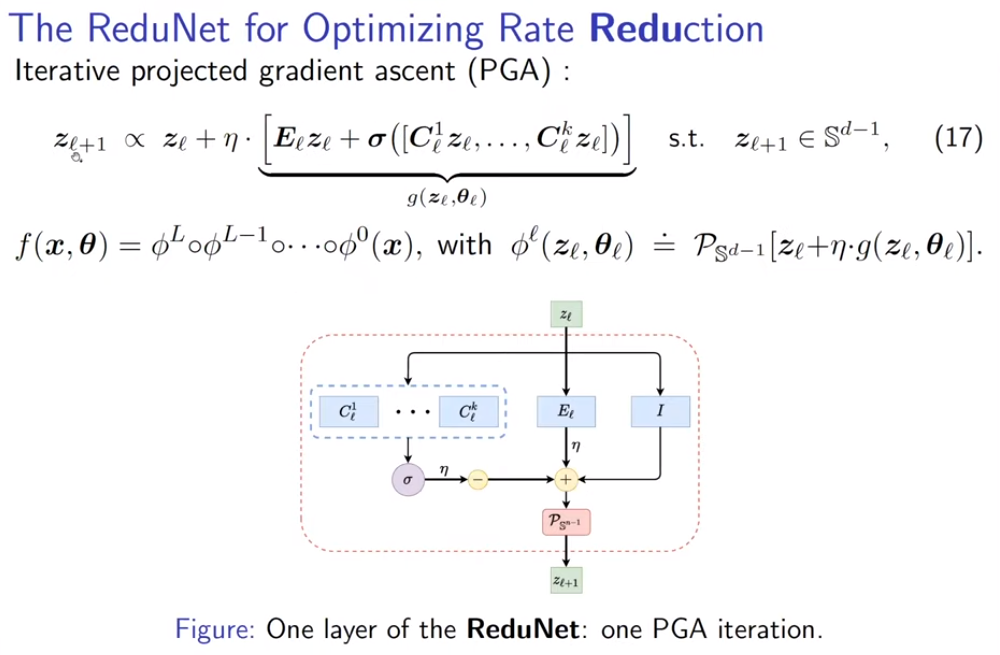
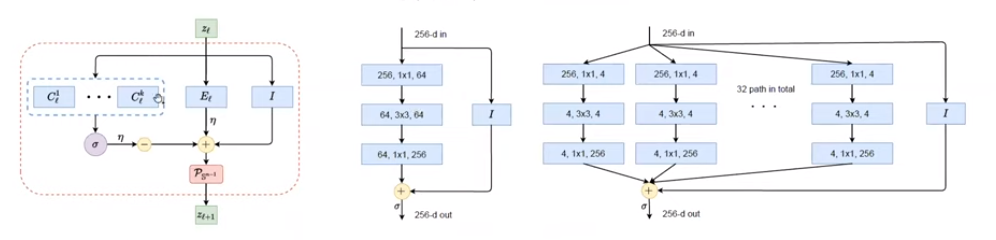
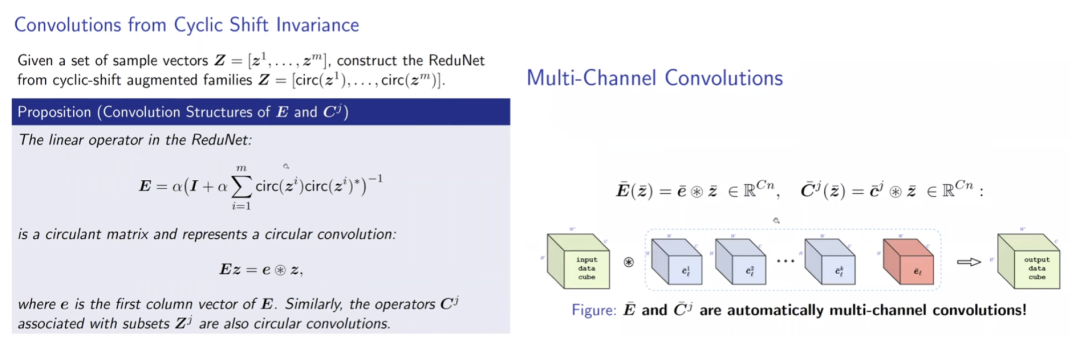
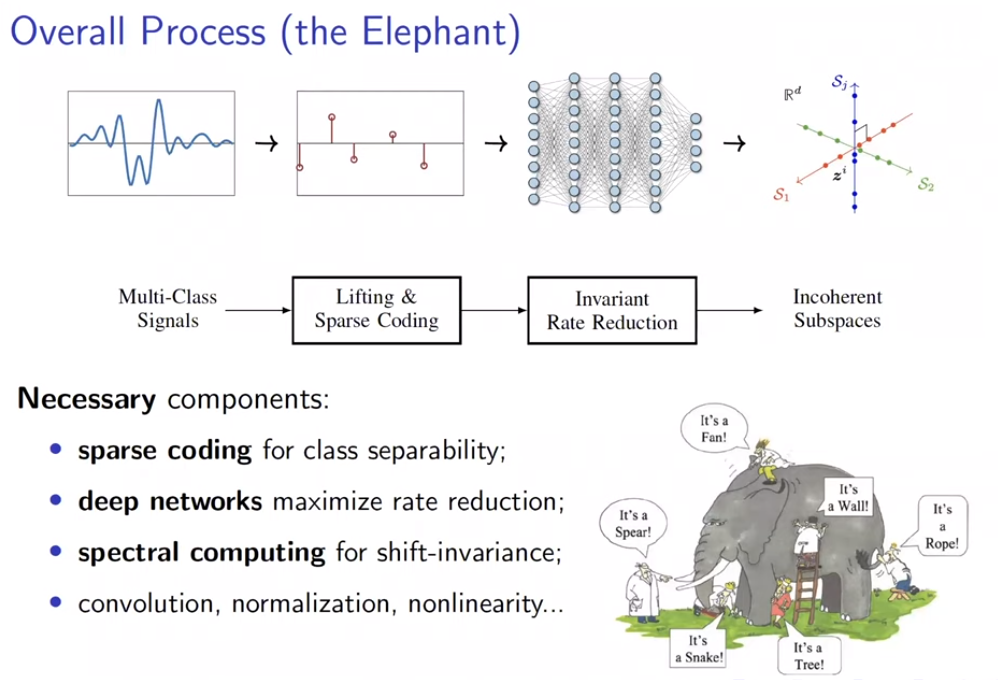
通过引入组不变性,将cyclic shift后的样本视为同一组,每次将一组样本编码到不同低秩空间,ReduNet可以实现识别的平移不变性。 同时,类似卷积的网络性质也随之而来。在引入平移不变的任务要求后,网络使用循环矩阵表示样本,因而在与E,C矩阵进行矩阵乘时,网络的操作自然地等价于循环卷积。 但考虑不变性时,另一个问题出现了。当存在无数种shift可能时,若样本是稠密的,则其可以通过变换生成任意信号,因此,样本的稀疏性和不变性是不可兼得的,这体现为“不变性”与“稀疏性”的Trade-off。通常深度网络可能隐含了样本的稀疏化过程,而ReduNet则使用了随机卷积核提取样本的稀疏编码。 可以看到E,C在考虑不变性后,自动产生了卷积效果,且求逆计算使得通道间的操作相互关联。上述计算还可以通过频域变换来加速计算效率。 构造的ReduNet也可以通过反向传播训练,且前向传播计算得到的参数,为反向传播训练提供了非常好的参数初始化,通过该初始化得到的参数,经过BP训练后,结果比随机初始化并BP训练的结果有显著提升马毅教授指出,在构造ReduNet的过程中发现,深度神经网络中常用的操作,稀疏编码,频域计算,卷积,归一化,非线性等等,都是为了实现优化 MCR^2 目标,学习一个可线性划分的表示所必须的操作,且可以在构造网络的过程中推导出来。教授在报告中引用的费曼这句话"What I cannot create I do not understand.",深刻地揭示了该工作的意义。当深度网络中曾经广泛使用的操作能够真正被构造出来时,我们才真正理解了他们。