训练CV模型新思路来了:用NLP大火的Prompt替代微调,性能全面提升

本文经ai新媒体量子位(公众号 id:qbitai)授权转载,转载请联系出处 本文约1500字,建议阅读5分钟
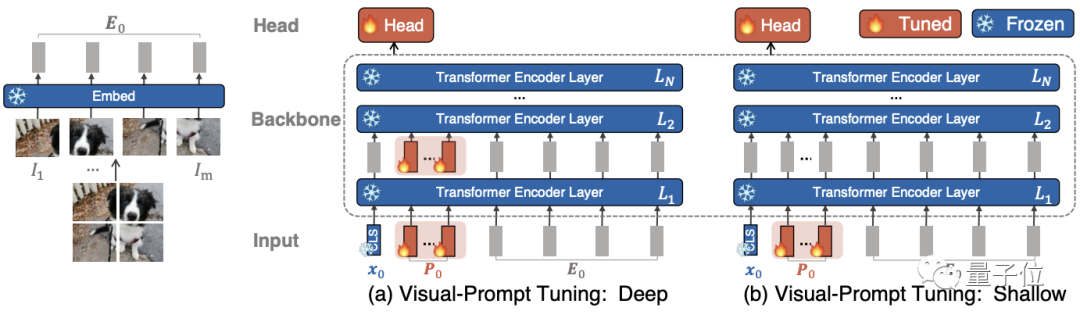
通过Prompt来调整基于Transformer的视觉模型。
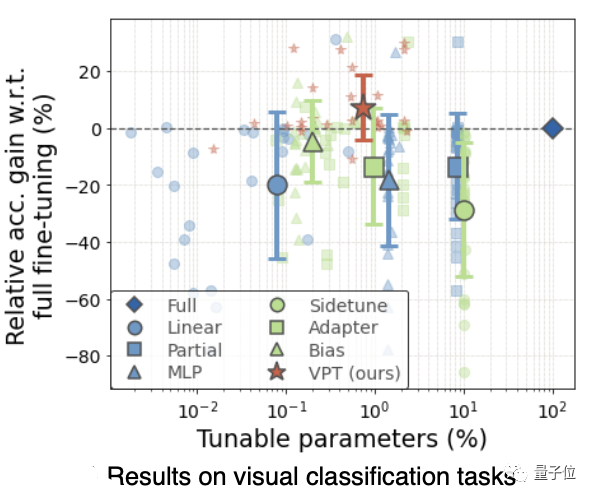

只使用不到1%的模型参数
20/24的优胜率




作者介绍


论文地址:
https://arxiv.org/abs/2203.12119
评论
 下载APP
下载APP本文经ai新媒体量子位(公众号 id:qbitai)授权转载,转载请联系出处 本文约1500字,建议阅读5分钟
通过Prompt来调整基于Transformer的视觉模型。
论文地址:
https://arxiv.org/abs/2203.12119