
训练CV模型常用的Tips & Tricks
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

极市导读
本文从9个方面(图像增强、更好的模型、学习率和scheduler、优化器、正则化手段、标签平滑、.知识蒸馏、伪标签、错误分析)总结了在训练图像识别模型时常用的一些技巧。
开头
最近参加一个CV比赛,看到有参赛者分享了自己训练图像识别模型时常用到的小技巧,故对其进行记录、整理,方便未来继续学习。整理了很多,它们不一定每次有用,但请记在心中,说不定未来某个任务它们就发挥了作用!
主要从以下9个方面进行介绍:
-
图像增强
-
更好的模型
-
学习率和scheduler
-
优化器
-
正则化手段
-
标签平滑
-
知识蒸馏
-
伪标签
-
错误分析
1.图像增强
以下列出了许多增强方式,有的甚至没见过,但是也不是每一种增强方式都是有利的,需要自己根据任务和实验进行选择合适的增强方式。
颜色增强
Color Skew:
这种增强通过将每个通道乘以随机选择的系数来随机调整图像的色调、饱和度和亮度。系数从 [0:6;1:4] 的范围内选择,以确保生成的图像不会过于失真。
def color_skew(image):
h, s, v = cv2.split(image)
h = h * np.random.uniform(low=0, high=6)
s = s * np.random.uniform(low=1, high=4)
v = v * np.random.uniform(low=0, high=6)
return cv2.merge((h, s, v))
RGB Norm:
这种增强通过从每个通道的值中减去每个通道的平均值并除以通道的标准差来标准化图像的 RGB 通道。这有助于标准化图像中的值,并可以提高模型的性能。
def rgb_norm(image):
r, g, b = cv2.split(image)
r = (r - np.mean(r)) / np.std(r)
g = (g - np.mean(g)) / np.std(g)
b = (b - np.mean(b)) / np.std(b)
return cv2.merge((r, g, b))
Black and White:
这种增强通过将图像转换为灰度色彩空间将图像转换为黑白。
def black_and_white(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
Ben Graham: Greyscale + Gaussian Blur:
这种增强将图像转换为灰度并应用高斯模糊来平滑图像中的任何噪声或细节。
def ben_graham(image):
image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
image = cv2.GaussianBlur(image, (5, 5), 0)
return image
Hue, Saturation, Brightness:
这种增强将图像转换为 HLS 色彩空间,HLS 色彩空间将图像分成色调、饱和度和亮度通道。
def hsb(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2HLS)
LUV Color Space:
这种增强将图像转换为 LUV 色彩空间,该空间旨在在感知上保持一致并实现更准确的色彩比较。
def luv(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2LUV)
Alpha Channel:
这种增强为图像添加了一个 alpha 通道,可用于增加透明效果。
def alpha_channel(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2RGBA)
YZ Color Space:
这种增强将图像转换为 XYZ 颜色空间,这是一种与设备无关的颜色空间,可以实现更准确的颜色表示。
def xyz(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2XYZ)
Luma Chroma:
这种增强将图像转换为 YCrCb 颜色空间,它将图像分成亮度(亮度)和色度(颜色)通道。
def luma_chroma(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2YCrCb)
CIE Lab:
这种增强将图像转换为 CIE Lab 颜色空间,该颜色空间设计为感知均匀,可实现更准确的颜色比较。
def cie_lab(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2Lab)
YUV Color Space:
这种增强将图像转换为 YUV 颜色空间,它将图像分成亮度(亮度)和色度(颜色)通道。
def yuv(image):
return cv2.cvtColor(image, cv2.COLOR_RGB2YUV)
Center Crop:
这种增强随机裁剪长宽比为 [3/4,4/3] 的矩形区域,然后按 [8%,100%] 之间的因子随机缩放裁剪,最后将裁剪调整为 img_{size} * img_{size} img_{size} * img_{size} 正方形。这是在每个批次上随机完成的。
transforms.CenterCrop((100, 100))
Flippings:
这种增强增加了图像随机水平翻转的概率。例如,概率为 0.5,图像有 50% 的机会被水平翻转。
def flippings(image):
if np.random.uniform() < 0.5:
image = cv2.flip(image, 1)
return image
Random Crop:
这种增强从图像中随机裁剪出一个矩形区域。
transforms.RandomCrop((100, 100
Random Resized Crop:
这种增强从图像中随机调整大小和裁剪矩形区域。
transforms.RandomResizedCrop((100, 100))
Color Jitter:
这种增强随机调整图像的亮度、对比度、饱和度和色调。
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
Random Affine:
这种增强对图像随机应用仿射变换,包括旋转、缩放和剪切。
transforms.RandomAffine(degrees=45, translate=(0.1, 0.1), scale=(0.5, 2.0), shear=45)
Random Horizontal Flip:
以 0.5 的概率随机水平翻转图像。
transforms.RandomHorizontalFlip()
Random Vertical Flip:
这种增强以 0.5 的概率随机垂直翻转图像。
transforms.RandomVerticalFlip()
Random Perspective:
这种增强随机对图像应用透视变换。
transforms.RandomPerspective()
Random Rotation:
这种增强将图像随机旋转给定的度数范围。
transforms.RandomRotation(degrees=45)
Random Invert:
这种增强会随机反转图像的颜色。
transforms.RandomInvert()
Random Posterize:
这种增强随机减少了用于表示每个像素值的位数,从而产生了分色效果。
transforms.RandomPosterize(bits=4)
Random Solarize:
这种增强对图像随机应用曝光效果,其中高于某个强度阈值的像素被反转。
transforms.RandomSolarize(threshold=128)
Random Autocontrast:
这种增强通过将强度值拉伸到整个可用范围来随机调整图像的对比度。
transforms.RandomAutocontrast()
Random Equalize:
这种增强随机地均衡了图像的直方图,从而增加了对比度。
transforms.RandomEqualize()
更高级的增强方式
除了以上的基础增强方式,还有一些更高级的增强方式。
Auto Augment:
Auto Augment 是一种增强方法,它使用强化学习来搜索给定数据集的最佳增强策略。它已被证明可以提高图像分类模型的性能。
from autoaugment import AutoAugment
auto_augment = AutoAugment()
image = auto_augment(image)
Fast Autoaugment:
Fast Autoaugment 是 Auto Augment 方法的更快实现。它使用神经网络来预测给定数据集的最佳扩充策略。
from fast_autoaugment import FastAutoAugment
fast_auto_augment = FastAutoAugment()
image = fast_auto_augment(image)
Augmix:
Augmix 是一种增强方法,它将多个增强图像组合起来创建一个单一的、更加多样化和逼真的图像。它已被证明可以提高图像分类模型的鲁棒性和泛化能力。
from augmix import AugMix
aug_mix = AugMix()
image = aug_mix(image)
Mixup/Cutout:
Mixup 是一种增强方法,通过线性插值像素值来组合两个图像。Cutout 是一种从图像中随机删除矩形区域的增强方法。这些方法已被证明可以提高图像分类模型的鲁棒性和泛化能力。
"You take a picture of a cat and add some "transparent dog" on top of it. The amount of transparency is a hyperparam."
x=lambda*x1+(1-lambda)x2,
y=lambda*x1+(1-lambda)y2
Test Time Augmentations(TTA)
图像增强不仅在训练期间很有用,而且在测试期间也很有用。用在测试阶段,人们称它为TTA,只需将测试集的图像进行多次增强,应用于预测并对结果进行平均即可。这种方法能增强预测的鲁棒性,但是相应的,会增加时间。对测试集做增强,不适应太高级的增强方式,常见的如改变图像尺度,crop不同的地方,进行翻转等。
个人感觉这种做法应该只适用于比赛中吧~
2.比赛中目前仍然常见的模型
虽然下面的模型距离现在相隔几年,但是它们出众的性能,使得它们仍在比赛中占据前排,这几年虽然出了更好的模型,但很多模型未开源或是太大了,并未得到更广泛的应用。
tf_efficientnetv1,v2系列
seresnext
以及一些可以尝试的想法和模型。
Swin Transformer
BeIT Transformer
ViT Transformers
在backbone后面添加更多隐藏层
添加更多层可能是有益的,因为你可以使用它们来学习更多高级特征,但它也可以缓和大型预训练模型的微调,甚至损害模型性能。
逐层解冻
一个可以让你获得微小改进的简单技巧是随着训练的进行解冻预训练骨干的层。先添加更多层并冻结backbone,然后再慢慢解冻backbone的参数让其参与训练。
## Weight freezing
for param in model.parameters():
param.requires_grad = False
## Weight unfreezing
for param in model.parameters():
param.requires_grad = True
TensorFlow 中的权重冻结和解冻
## Weight freezing
layer.trainable = False
## Weight unfreezing
layer.trainable = True
3.学习率和学习率调度器
学习率和学习率调度器会影响模型的训练性能。改变学习率会对性能和训练收敛产生很大影响。
学习率schedulers
最近,One Cycle Cosine schedule 已经显示出在其在多个任务上提供更好的结果,你可以这样使用它:
One Cycle Cosine scheduling in PyTorch
from torch.optim.lr_scheduler import CosineAnnealingLR
optimizer = torch.optim.Adam(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
#这里使用
scheduler = CosineAnnealingLR(optimizer, T_max=num_train_optimization_steps)
num_training_steps = num_train_optimization_steps / args.gradient_accumulation_steps
# Update the scheduler
scheduler.step()
# step the learning rate scheduler here,
# you will want to step the learning rate scheduler only once per optimizer step nothing more nothing less.
# So in this case, it should be called before you expect the gradients to be applied.
tensorflow
## One Cycle Cosine scheduling in TensorFlow
optimizer = tf.keras.optimizers.Adam(learning_rate)
scheduler = tf.keras.optimizers.schedules.CosineDecay(learning_rate, decay_steps=num_training_steps)
使用学习率调度器的小技巧
-
使用“Triangular”或“One Cyclic”方法进行学习率调整可以提供微妙但显着的改进——这些学习率调度的智能方法可以克服一些batch大小问题。
-
花时间研究适合你的任务和你使用的模型的最佳学习率调度方法,这是你的模型如何收敛的一个非常重要的部分。
-
学习率调度策略可用于训练具有较低batchsize或多个学习率的模型。
-
众所周知,学习率很重要,所以首先优先尝试低学习率,再看看提高学习率是有助于还是损害模型的表现。
-
在训练的后期增加学习率或多个学习率或batchsize或梯度累积或学习率调度策略有时会帮助模型更好地收敛,这是一种高级技术,因为有时它会损害性能但前提是你给予它太大的值 - 记得测试它。
-
当使用梯度累积或多个学习率或高批量大小时,Loss scaling有助于减少损失方差并改善梯度流,但如果你试图通过增加批量大小来解决该问题,请尝试增加学习率,因为它有时会产生更好的性能。
4.优化器-Optimizers超参数
现在很多人都在使用 Adam 或 AdamW。如果你希望从 Adam 优化器中获得最佳性能,则需要了解几件事:
找到最佳的权重衰减值可能很麻烦,依靠大量的实验(和运气)。
-
另一个重要的超参数是 Adam 优化器中使用的 beta1 和 beta2,选择最佳值取决于你的任务和数据。许多新任务可以从较低的 beta1 和较高的 beta2 中获益,而在已建立的任务中它们会执行相反的操作。再强调一遍:实验将是你最好的朋友。
-
在 Adam 优化器的世界中,首要规则是不要低估优化器 epsilon 值的重要性。寻找最佳权重衰减超参数的相同原则也适用于此。
-
不要过度使用梯度裁剪范数——当你的梯度爆炸时它有时可能会有所帮助,反之亦然——它会阻止某些任务的收敛。
-
梯度累积仍然可以提供一些微妙的好处,我通常累积大约 2 步的梯度,但如果你的 GPU 没有耗尽内存,你最多可以推送 8 步梯度累积。使用混合精度时,梯度累积也很有用。
另外,如果你以足够的时间去调整 SGD的动量,你可能会得到更好的结果,但这同样需要大量调整。
以下还有几个值得注意的优化器:
-
AdamW:这是 Adam 算法的扩展,可防止外层模型权重的指数权重衰减,并鼓励低于默认权重的惩罚超体积。
-
Adafactor:它被设计成具有低内存使用率和可扩展性。该优化器可以使用多个 GPU 提供显着的优化器性能。
-
Novograd:基本上是另一个类似 Adam 的优化器,但具有更好的特性。它是用于训练 bert-large 模型的优化器之一。
-
Ranger:Ranger 优化器是一个非常有趣的优化器,它在性能优化方面的解决方案中取得了不错的成绩,但它不是很出名或不受支持。
-
Lamb:由 GLUE 和 QQP 竞赛获胜者开发的 GPU 优化可重用 Adam 优化器。
-
Lookahead:一种流行的优化器,你可以在其他优化器之上使用它,它将为你提供一些性能提升。
5.过拟合和正则化
使用dropout! 在层之间添加dropout通常会产生更高的训练稳定性和更可靠的结果,请在隐藏层中使用。Dropout 也可用于小幅提高性能,在训练前尝试设置层 dropouts。任务和模型。
正则化: 当你的神经网络过度拟合或欠拟合时,正则化可以极大地提升性能,对于正常的机器学习模型,L1 或 L2 正则化是可以的。
始终使用实验来检验想法:使用实验。实验。实验并尝试模型。
Multi Validations:你可以通过使用Multi Validations来提高模型对过度拟合的稳健性。然而,这是以计算时间为代价的。
6.Label Smoothing
论文链接:
When Does Label Smoothing Help?:
https://arxiv.org/pdf/1906.02629.pdf
核心公式一行概括之:
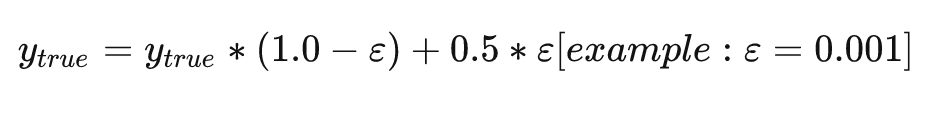
通常效果很好,可以在很多比赛中看到它的身影。以二分类任务为例,以下给出标签平滑的示例代码,可以直接用。
Tensorflow:
loss = BinaryCrossentropy(label_smoothing = label_smoothing)
Pytorch:
from torch.nn.modules.loss import _WeightedLoss
class SmoothBCEwLogits(_WeightedLoss):
def __init__(self, weight = None, reduction = 'mean', smoothing = 0.0, pos_weight = None):
super().__init__(weight=weight, reduction=reduction)
self.smoothing = smoothing
self.weight = weight
self.reduction = reduction
self.pos_weight = pos_weight
@staticmethod
def _smooth(targets, n_labels, smoothing = 0.0):
assert 0 <= smoothing < 1
with torch.no_grad(): targets = targets * (1.0 - smoothing) + 0.5 * smoothing
return targets
def forward(self, inputs, targets):
targets = SmoothBCEwLogits._smooth(targets, inputs.size(-1), self.smoothing)
loss = F.binary_cross_entropy_with_logits(inputs, targets,self.weight, pos_weight = self.pos_weight)
if self.reduction == 'sum': loss = loss.sum()
elif self.reduction == 'mean': loss = loss.mean()
return loss
7.知识蒸馏
用一个大的teacher network来指导一个small network的学习。
步骤:
-
训练大型模型:在数据上训练大型模型。
-
计算软标签:使用训练好的大模型计算软标签。即大模型“软化”后softmax的输出
-
Student模型训练:在大模型的基础上,训练一个基于教师输出的学生模型作为额外的软标签损失函数,通过插值调整两个损失函数的比例。
8.伪标签(Pseudo Labeling)
使用模型标记未标记的数据(例如测试数据),然后使用新的标记数据来重新训练模型。
步骤:
-
训练教师模型:根据你拥有的数据训练模型。
-
计算伪标签:使用训练好的大模型为未标注数据计算软标签。
-
仅使用模型“确定”的目标:仅使用最高置信度的预测作为伪标签,以尽可能避免错误。(如果你不这样做,它可能不起作用)
-
Studnet 模型训练:根据你拥有的新标记数据训练学生模型。
9.错误分析
很多人在训练的时候,都只是一昧的调参,却不懂得分析,在公司里面也常常听到分析bad case这一词。它同样很重要,甚至有时候可以为我们提供额外的思路。可以为你节省大量时间的一个重要做法是使用你的模型来查找更难或损坏的数据样本。图像对于你的模型来说“更难”的原因可能有很多,例如,小目标对象、不同颜色、切断目标、无效注释等等。尝试从中找出原因,这可能能帮助你。
错误有时候是好消息!
这些它们正是将排行榜顶部大佬与其他参与者区分开来的样本。如果你很难解释你的模型发生了什么,那么看看你的模型遇到的验证样本。
Finding Your Model's Errors!
查找错误的最简单方法是根据模型的置信度分数对验证样本进行排序,并查看哪些样本的预测置信度最低。
mistakes_idx = [img_idx for img_idx in range(len(train)) if int(pred[img_idx] > 0.5) != target[img_idx]]
mistakes_preds = pred[mistakes_idx]
sorted_idx = np.argsort(mistakes_preds)[:20]
# Show the images of the sorted idx here..
总结
以上,整理了很多,它们不一定每次有用,但请记在心中,说不定未来某个任务它们就发挥了作用!
参考文献
1.https://www.kaggle.com/competitions/rsna-breast-cancer-detection/discussion/372567
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~