
TextCNN可以和对比学习融合吗-SimCSE论文读后感
最近抽时间把SIMCSE用Pytorch复现了一下,中途涉及到的几个思考点,和大家分享一下:
注:原作者有开源论文代码,不过有些复杂,大家可以看一下自己魔改一下;
全文思路如下:
SIMCSE理论介绍以及代码实现的部分细节点 TextCNN是否可以借鉴SIMCSE的思路,来训练模型从而获取比较好的Sentence embedding 是否可以借鉴Dropout数据增强,使用amsoftmax,减少同类距离,增大不同类距离
1. SIMCSE论文理论介绍
当时读完SIMCSE论文之后,没时间写文章,赶紧发了个朋友圈把思路简单的记录了一下;
感兴趣的朋友加我微信【dasounlp】,互看朋友圈啊,笑;
论文分为四个部分来讲,对比学习,无监督SIMCSE,有监督SIMCSE,评价指标;
1.1 对比学习
对比学习的目的是,是减少同类距离,增大不同类之间的距离,借此获得一个文本或者图片更好的表示向量;
定义句子对:;其中N是一个Batch中句子对样本数量,是语义相似的样本,分别是经过编码器Encoder之后得到的表示向量;
那么对比学习的训练目标就是:
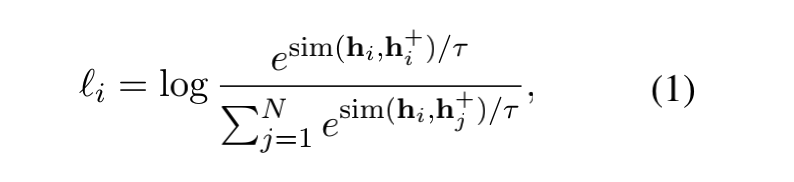
这个公式看着比较唬人,其实本质就是一个多分类softamx的交叉熵损失函数;
需要注意的是参数 是个超参数,是一个相似性度量函数,原论文使用的cosine,其实使用一些其他的相似性函数应该也没问题;
注意一下分母这里:其实一个batch,比如有N个句子对,那么就有2N个句子,其中正例是1个,负样本应该是总样本数目2N减去样本本身加上样本的正例,也就是2N-2;
不过,看公式,作者这里用到的是一个batch中的N个样本,也就是使用的是每个句子对中的其中一个;
关于这个问题,是否使用更多的负样本是不是会获得更好的效果,作者回复说并没有。
我自己在复现的时候,使用的是2N-1个样本【正例+负例总和】;
那么在落地到代码的时候,怎么实现这个交叉熵呢?我画了一个简单的图,比如batch是2:

1.2 正例和负例的构建
上面谈到的整个过程,全程没离开正例和负例;
在图像中,一个图像经过平移旋转等数据增强的方式,可以看成是生成了图像的正例;
在文本上,一些常规的数据增强的手段就是删减单词,替换同义词等等;
文本的数据增强存在的一个问题就是,一个简单的操作可能就会导致语义的改变;
在无监督的SIMCSE中,正例的构造很有意思,就是通过添加一个Dropout的噪声;
Dropout是在随机失活神经元,每次句子经过网络,失活的神经元是不一致的,导致生成的embedding是不一致的;
这一点其实大家应该都懂,但是能联想到把这个作为数据增强的一个手段,确实很强。
在有监督的SIMCSE中,其实是借助了NLI数据集中自带的标签,来构造正例和负例;
直接来看作者原文中的图吧;

1.3 句子向量评价指标
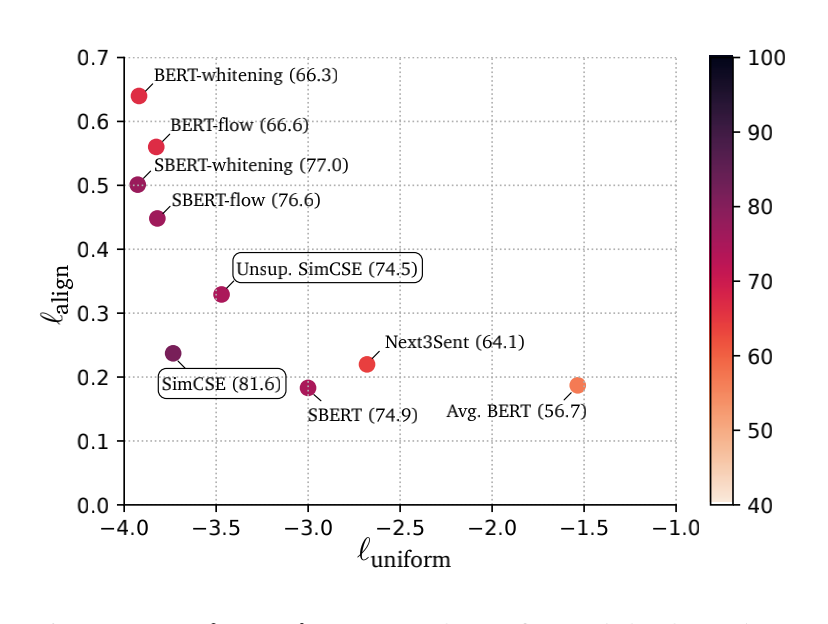
句子向量的评价指标这里,用两个东西来量化一下,alignment和Uniformity;
直接来看图:
2. TextCNN和Dropout的融合
SIMCSE中,BERT作为Encoder未免太复杂了,这时候按照常规思路,我会去思考可不可以使用简单网络比如textcnn代替bert;
那么实现方式就可以分为两种:
一种是我使用textcnn直接作为encoder,然后仿照无监督simcse的训练方式进行训练就可以了;
第二种方式就是知识蒸馏,无监督simcse训练一个bert的encoder出来之后,使用简单网络textcnn进行学习就可以了;
我针对第一种方式做了个实验。
在实验之前,我就没报什么大的希望,只是想亲眼试一下究竟可行不可行;
为什么没有报太大希望呢,很简单,我自己认为dropout作为一种数据增强的形式,太过简单了,textcnn这种简单网络,不足以学习到其中的差异;
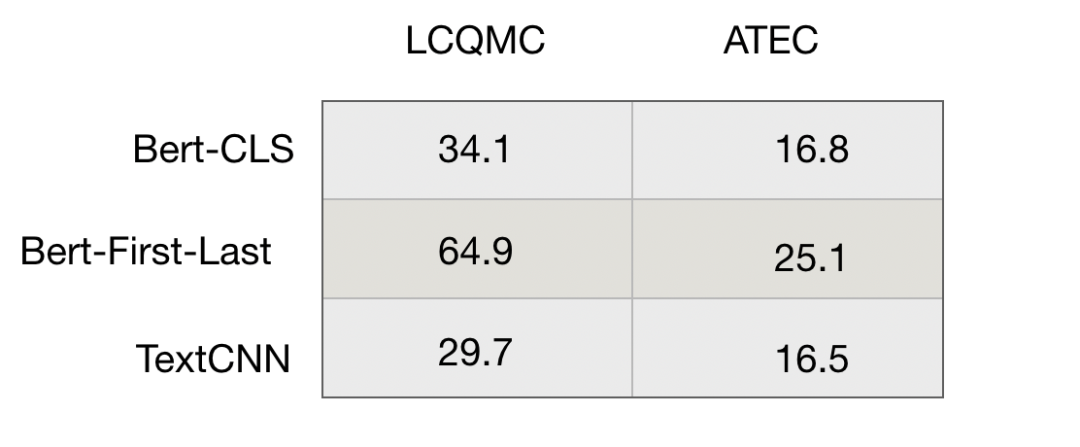
我在中文的LCQMC和ATEC数据集上做了一个简单的测试,Spearman作为评价指标,结果如下:
之后,我看情况能不能把这部分代码开源出来~~,自己实现也挺简单的;
3. Amsoftmax的引入
第三个小思路是这样的,dropout可以看做是一个最小化的文本数据增强的形式。同一个句子,经过encoder,得到的embeding不同,但是语义是相似的,所以可以看做是一个正例;
进一步的,如果我同一个句子经过多次encoder,比如经过10次,那么我得到的就是10个embedding;
也就是说,在同一个语义下面,我得到的是10个语义近似但是embedding不同的向量;
如果我有10万个句子,可以把这个10万个句子当做是10万个类别,每个类别下有10个样本;
想一下这个感觉,不就是人脸识别的操作吗?
那么可不可以使用这种方式,得到更好的语义表达呢?
这个我没做实验,只是一个思路,之后有时间再去做实验,有兴趣的朋友可以做一下;