
可以让深度学习编译器来指导算子优化吗
0x0. 前言
之前在阅读Ansor论文的时候(https://zhuanlan.zhihu.com/p/390783734)我就在想这样一个问题,既然Ansor是在人为指定的推导规则下启发式的生成高性能的Scheduler模板。那么这个算子生成的Scheduler模板是否可以反过来指导我们写程序呢?嗯,然后我就开启了这个实验,但最近因为工作的事情delay得厉害,终于在这个周末抽出时间来更新这个实验结果并且记录了这篇文章。由于笔者只对GEMM的优化熟悉,这里就以优化X86的GEMM为例子来探索。希望这篇文章能为你带来启发,文章所有的实验代码都放到了https://github.com/BBuf/tvm_learn ,感兴趣的可以点个star一起学习(学习TVM的4个月里,这个工程已经收到了快100star了,我很感激)。
0x1. 浮点峰值测量
其实如何测试硬件的浮点峰值在我一年前的这篇文章中已经讲到了。https://zhuanlan.zhihu.com/p/268925243。为了照顾一下新来的,这里复习一下什么是浮点峰值?
算法的浮点峰值gflops代表计算量除以耗时获得的值。
显然浮点峰值约高,那么算法的性能自然越好。
所以在优化之前,我们需要先测出硬件的浮点峰值。以X86为例,参考https://zhuanlan.zhihu.com/p/28226956 ,克隆https://github.com/pigirons/cpufp,然后sh build.sh编译就可以获得测试浮点峰值的可执行文件cpufp。
然后运行./cpu_fp -num_threads就可以测出指定线程下硬件的最大gflops。
这里我实验的CPU是:64 Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz。
然后指定线程为1,测出浮点峰值如下:
Thread(s): 1
avx512_vnni int8 perf: 262.2060 gops.
avx512f fp32 perf: 65.5496 gflops.
avx512f fp64 perf: 33.2332 gflops.
fma fp32 perf: 73.0070 gflops.
fma fp64 perf: 36.3787 gflops.
avx fp32 perf: 36.5239 gflops.
avx fp64 perf: 18.2485 gflops.
sse fp32 perf: 22.2130 gflops.
sse fp64 perf: 9.2662 gflops.
由于本文的优化都是基于fma指令,所以这里只需要关注使用fma fp32的浮点峰值峰值即可。「可以看到大约为73gflops」。
0x2. 入门GEMM优化
https://github.com/flame/how-to-optimize-gemm/wiki 中介绍了如何采用各种优化方法来优化GEMM。其基本方法是将输出划分为若干个 4×4 子块,以提高对输入数据的重用。同时大量使用寄存器,减少访存;向量化访存和计算;消除指针计算;重新组织内存以地址连续等。最终将GEMM的性能提到到原始版本的8倍以上。
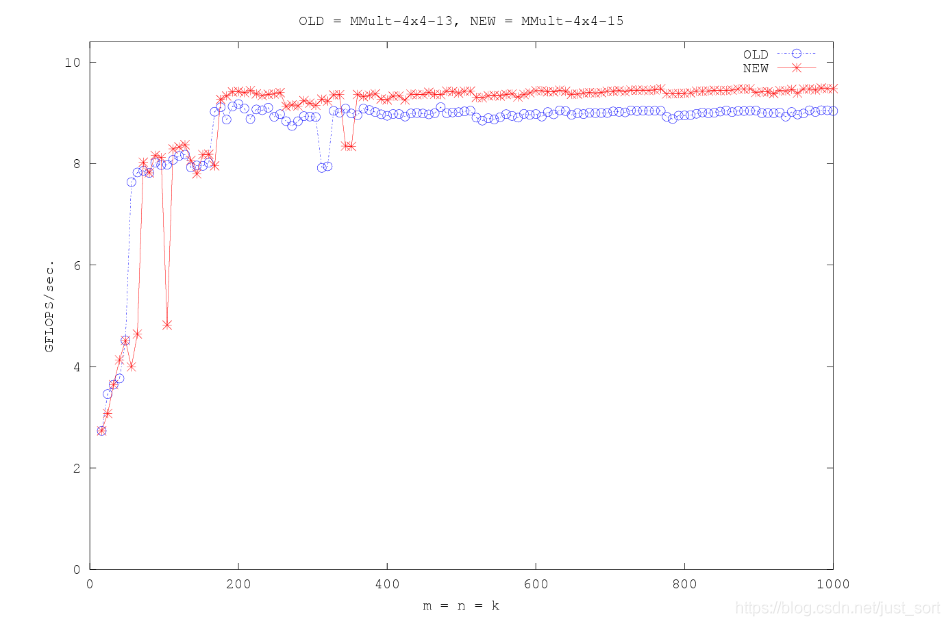
我改了一个简易的how-to-optimize-gemm的版本,可以更直观的获得每个优化的gflops,地址在这里:https://github.com/BBuf/tvm_learn/tree/main/optimize_gemm/src。感兴趣的读者可以去学习上面那个一步步优化GEMM博客,了解GEMM的一些常用优化方法。在我的测试记录中,「分块并使用大量寄存器」 以及 「重新组织内存以地址连续」 是性能提升的关键。(当然为了你的时间考虑,不学习应该也问题不大,不影响我接下来要讲到的东西)
0x3. 一个更优的GEMM优化
在上一节中展示的性能优化图中,我们可以看到在矩阵比较小的时候GEMM的gflops并不高,所以猜测这个算法仍然有较大的可优化空间。
这一节来介绍一个之前高叔叔写的GEMM,给定两个矩阵,其shape分别为(m,k)和(k, 24),求这两个矩阵乘积。为了使得这个矩阵可以放进L1 Cache,这里将m和k分别取值为,。
这里先跑一下这个程序看看它的gflops能达到硬件浮点峰值的多少。测试结果如下:
sgemm_kernel_x64_fma(24, 24, 64): time = 1.018230 us, perf = 72.407987 GFLOPS.
在第一节中我们测试的硬件浮点峰值如下:
fma fp32 perf: 73.0070 gflops.
可以看到这个GEMM的gflops达到了硬件浮点峰值的99%了。之前知乎的立交桥跳水冠军详细的解释过这个算法,见:https://zhuanlan.zhihu.com/p/383115932 ,不理解这个代码的读者可以看一看,我这里就不重复这段代码的原理了。
其实在一年前接触GEMM的时候和高叔叔就有交流,当时是这样的:
当时我找了不少的优化方法并且也自己思考过,但都不能在L1 Cache里面达到90%+的硬件利用率,这完全是因为我的程序中还存在很大的读写冗余,一直没有想到什么办法去解决好。因为我的思路一直就是定死分块的大小之后枚举k维度,然后一次计算多行和多列。虽然每一次计算的时候也快用满了寄存器,「但当时一直没有仔细去想一个问题,那就是在这个过程还存在其它读写冗余吗,以及当前的寄存器使用方式是否合理」?
我复习一下我当时的做法,分块大小是,首先我每次从矩阵A的8行分别拿出8个元素,也对应的要去拿矩阵B的1列8个元素(因为这里是以k来循环),这里一共占用了8+1共9个寄存器,然后输出还需要8个寄存器,所以一共用到了17个ymm寄存器。而X86架构AVX引入了16个256位寄存器(YMM0至YMM15)。这里多用了一个,所以退而求其次,我在拿A的数据时只用了4个寄存器,因此我实际上只用到了13个寄存器。代码见:https://github.com/BBuf/tvm_learn/blob/main/optimize_gemm/how_to_optimize_gemm/MMult_4x4_14.h。因此这个思路中寄存器还没用恰好用满,并且还存在大量读写冗余,性能不高也能想通了。
我认为高叔叔的这个代码恰好解决了我计算思路中这两个关键问题,因为这段代码不仅完全用满了16个ymm寄存器,并且读写冗余也降低了很多。所以能在L1 Cache中达到99%的硬件利用率。这份代码十分经验和Trricky的,突出一个凑得很好。
为了方便做实验,这份代码也被我copy到了tvm_learn仓库这里:https://github.com/BBuf/tvm_learn/tree/main/optimize_gemm/sgemm_kernel 。
0x4. 能否让编译器来指导算子优化?
假如你和我一样,对如何凑出高效的GEMM并不敏感,并且你有需要将一个GEMM算子优化到性能比较好的需求时你可以怎么做呢?
所以我想的是是否可以基于Ansor的搜索结果来指导我来编写高效的GEMM程序。因为Ansor不需要像AutoTVM那样人工指定Scheduler就可以生成高性能的Scheduler。
首先写一个搜索GEMM算子的Ansor程序,代码我放了到这里:https://github.com/BBuf/tvm_learn/blob/main/optimize_gemm/auto_scheduler/gemm.py 。
先按照TVM Docs中给出的经典配置来搜索一下,并统计一下当前搜索出的最佳程序的GFlops。
Execution time of this operator: 0.005 ms
GFlops: 14.80202901153263
有点低,emmm,不慌,我们再挣扎一下
上面的Ansor程序中可调超参数部分主要在这里:
log_file = "gemm.json"
measure_ctx = auto_scheduler.LocalRPCMeasureContext(min_repeat_ms=300)
tune_option = auto_scheduler.TuningOptions(
num_measure_trials=10, # change this to 1000 to achieve the best performance
runner=measure_ctx.runner,
measure_callbacks=[auto_scheduler.RecordToFile(log_file)],
verbose=2,
)
可以看到这里有一行注释说将num_measure_trials设置为1000可以获得最佳性能,我们改一下这个参数看看结果会不会改善一些,搜索了20分钟后结果如下:
Execution time of this operator: 0.004 ms
GFlops: 18.229696212591662
虽然结果好了一些,但gflops大概只有浮点峰值的25%左右。。而且TVM可能还使用了多个线程,而我们刚才测的峰值仅仅是单线程。
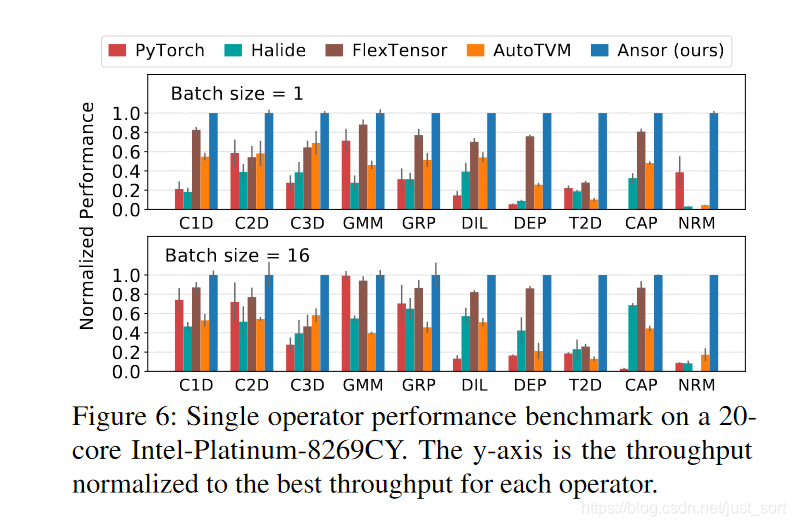
然后我拿出了Ansor论文中在X86上单个算子优化能力Benchmark图,这里面的NRM就表示2D GEMM。但比较遗憾的是论文没有提到这个矩阵的大小QAQ 。从这个图形来看,Ansor在GEMM的优化上是很强的,那么这里为什么没有达到预期的效果呢?我的理解是,在矩阵非常小的情况下,Ansor中很多的scheduler比如cache_read,parallel,reorder并不会产生什么增益,因为这个时候考验的是寄存器是否用满以及计算冗余的消除。所以我猜想当矩阵比较大的时候,Ansor的效果才会比较好。
既然在小矩阵上表现一般,Ansor在大矩阵上能获得更好的gflops?这里继续来尝试一下:直接把矩阵的,,分别设为2048,24,2048,然后把num_measure_trials设置为100,将target = tvm.target.Target("llvm -mcpu=skylake-avx512"), 看看最终的gflops:
Execution time of this operator: 0.319 ms
GFlops: 577.5124321897242
577.5GFlops!!! 注意,这里在llvm生成代码的时候,使用了avx512指令集。
为了结果更加准确,需要用满CPU的线程来重新测一下浮点峰值。我这里CPU的核心数是16,所以在之前测试gflops的基础上直接执行./cpufp 16就可以获取浮点峰值。
Thread(s): 16
avx512_vnni int8 perf: 4283.9168 gops.
avx512f fp32 perf: 1070.8582 gflops.
avx512f fp64 perf: 535.5170 gflops.
fma fp32 perf: 1172.6536 gflops.
fma fp64 perf: 586.3434 gflops.
avx fp32 perf: 586.3019 gflops.
avx fp64 perf: 293.1215 gflops.
sse fp32 perf: 344.4352 gflops.
sse fp64 perf: 172.0953 gflops.
这里要基于avx512f的fp32 gflops来看,感觉是一个挺不错的结果,已经有54%左右的硬件利用率了。
这里我为什么要用16线程的浮点峰值来对比,是因为我没有找到Ansor的并行scheduler策略会使用多少个核,所以我这里默认它会把CPU的线程用满,如果有大佬知道我可以更新一下这里的数据,可能真实的硬件利用率会更好一点。
0x5. 对比实验(对比Ansor和手工分块)
仍然是上面大矩阵的大小,,,分别设为2048,24,2048。我们直接运行0x3节中来自高叔叔的GEMM程序,把m和k设为2048,那个程序中24是固定的。结果如下:
sgemm_kernel_x64_fma(1024, 24, 1024): time = 741.568826 us, perf = 67.871850 GFLOPS.
在同样的矩阵大小下,手动设计的Kernel竟然还有90%左右的硬件利用率。
对于同样的矩阵大小,Ansor可以获得50%+的硬件利用率,而手工精细设计的GEMM能达到90%+的硬件利用率,这说明在GEMM这个算子的优化上,有经验的手工优化比Ansor的性能会好很多。
0x6. 结论
从上面的实验来看,基于Ansor优化GEMM算子仍然比不上手工精细设计的Kernel,所以想让Ansor来指导我们做高要求的算子优化是困难的。从Ansor的论文中可以了解到在优化GEMM这种计算密集型算子的时候有固定的规则,比如使用“SSRSRS”tile结构来作为GEMM的Scheduler,其中“S”代表空间循环的一个tile级别,“R”代表reduction循环的一个tile级别。这个tile实际上就是上面提到的分块。所以Ansor在优化的工程中也是借鉴了大量的人工经验,并且仅仅也只是在调整算子的Scheduler方面,并不能去改寄存器的使用方式,不能调整流水。
但如果一个人水平有限或者并不是很了解Kernel优化,只是好奇想尝试一些方法。但他优化算子的时候获得的性能还不如这些自动调优工具,那么我们可以尝试基于这些调优结果展示的Scheduler结果来进行思考自己代码的Scheduler究竟是哪个地方出了问题。是分块大小不合适,还是局部性比较差?或许看一下自动搜索出的代码的Scheduler目标就会获得一些机器带来的启发,可以帮助我们改进。
在算子优化中,除了Scheduler之外,寄存器的使用时机,针对不同硬件的指令重排,指令集本身的选择等都是影响最终性能的因素。但这些东西在TVM里很难去自动的操作,只能让LLVM编译器来做。或者就是人工去写算子的优化代码。
总之,这篇文章是笔者对一些小实验进行观察而获得的,不能保证我的观点都是正确的,欢迎指出错误和我交流。
《Python计算机视觉与深度学习实战》立足实践,从机器学习的基础技能出发,深入浅出地介绍了如何使用 Python 进行基于深度学习的计算机视觉项目开发。开篇介绍了基于传统机器学习及图像处理方法的计算机视觉技术;然后重点就图像分类、目标检测、图像分割、图像搜索、图像压缩及文本识别等常见的计算机视觉项目做了理论结合实践的讲解;最后探索了深度学习项目落地时会用到的量化、剪枝等技术,并提供了模型服务端部署案例。
《Python计算机视觉与深度学习实战》适合有一定的Python 编程基础,初学深度学习的读者阅读。

对本书有兴趣的可以使用下方链接进行购买。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信: