
对比sql,学习pandas操作
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 译者:黄伟呢 来源:数据分析与统计学之美
阅读须知
import pandas as pd
import numpy as np
url = ("https://raw.github.com/pandas-dev/pandas/master/pandas/tests/io/data/csv/tips.csv")
tips = pd.read_csv(url)
tips
1. 副本与就地操作
sorted_df = df.sort_values("col1")
df = df.sort_values("col1")
df.sort_values("col1", inplace=True)
2. select关键字
SELECT total_bill, tip, smoker, time
FROM tips;
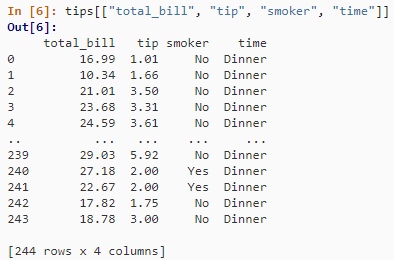
tips[["total_bill", "tip", "smoker", "time"]]
SELECT *, tip/total_bill as tip_rate
FROM tips;
tips.assign(tip_rate=tips["tip"] / tips["total_bill"])

3. where关键字
SELECT *
FROM tips
WHERE time = 'Dinner';
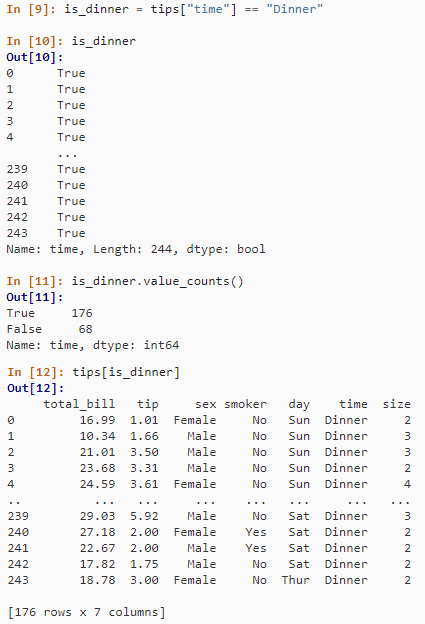
布尔索引。tips[tips["total_bill"] > 10]

is_dinner = tips["time"] == "Dinner"
is_dinner.value_counts()
tips[is_dinner]
SELECT *
FROM tips
WHERE time = 'Dinner' AND tip > 5.00;
tips[(tips["time"] == "Dinner") & (tips["tip"] > 5.00)]

SELECT *
FROM tips
WHERE size >= 5 OR total_bill > 45;
tips[(tips["size"] >= 5) | (tips["total_bill"] > 45)]

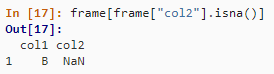
frame = pd.DataFrame({"col1": ["A", "B", np.NaN, "C", "D"], "col2": ["F", np.NaN, "G", "H", "I"]})
frame

SELECT *
FROM frame
WHERE col2 IS NULL;
frame[frame["col2"].isna()]
SELECT *
FROM frame
WHERE col1 IS NOT NULL;
frame[frame["col1"].notna()]

4. group by关键字
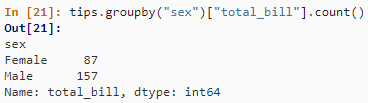
SELECT sex, count(*)
FROM tips
GROUP BY sex;
/*
Female 87
Male 157
*/
tips.groupby("sex").size()

tips.groupby("sex").count()

tips.groupby("sex")["total_bill"].count()
SELECT day, AVG(tip), COUNT(*)
FROM tips
GROUP BY day;
/*
Fri 2.734737 19
Sat 2.993103 87
Sun 3.255132 76
Thu 2.771452 62
*/
tips.groupby("day").agg({"tip": np.mean, "day": np.size})

SELECT smoker, day, COUNT(*), AVG(tip)
FROM tips
GROUP BY smoker, day;
/*
smoker day
No Fri 4 2.812500
Sat 45 3.102889
Sun 57 3.167895
Thu 45 2.673778
Yes Fri 15 2.714000
Sat 42 2.875476
Sun 19 3.516842
Thu 17 3.030000
*/
tips.groupby(["smoker", "day"]).agg({"tip": [np.size, np.mean]})

5. JOIN关键字
df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)})
df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)})
① 内连接
SELECT *
FROM df1
INNER JOIN df2
ON df1.key = df2.key;
# 默认情况下合并执行 INNER JOIN
pd.merge(df1, df2, on="key")
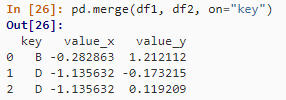
indexed_df2 = df2.set_index("key")
pd.merge(df1, indexed_df2, left_on="key", right_index=True)
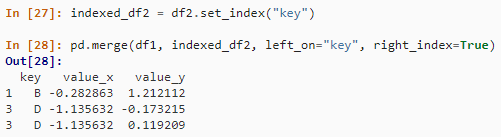
② 左外连接
SELECT *
FROM df1
LEFT OUTER JOIN df2
ON df1.key = df2.key;
pd.merge(df1, df2, on="key", how="left")
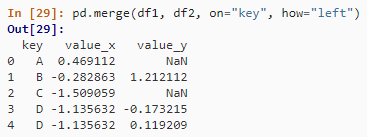
③ 右连接
SELECT *
FROM df1
RIGHT OUTER JOIN df2
ON df1.key = df2.key;
pd.merge(df1, df2, on="key", how="right")
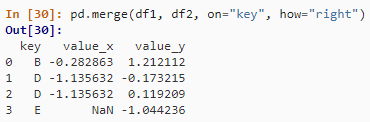
④ 全连接
# 这个不是MySQL写法
SELECT *
FROM df1
FULL OUTER JOIN df2
ON df1.key = df2.key;
pd.merge(df1, df2, on="key", how="outer")

⑤ 联合
SELECT city, rank
FROM df1
UNION ALL
SELECT city, rank
FROM df2;
/*
city rank
Chicago 1
San Francisco 2
New York City 3
Chicago 1
Boston 4
Los Angeles 5
*/
df1 = pd.DataFrame({"city": ["Chicago", "San Francisco", "New York City"], "rank": range(1, 4)})
df2 = pd.DataFrame({"city": ["Chicago", "Boston", "Los Angeles"], "rank": [1, 4, 5]})
pd.concat([df1, df2])
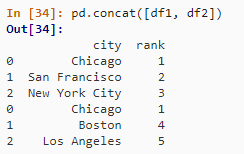
SELECT city, rank
FROM df1
UNION
SELECT city, rank
FROM df2;
-- notice that there is only one Chicago record this time
/*
city rank
Chicago 1
San Francisco 2
New York City 3
Boston 4
Los Angeles 5
*/
pd.concat([df1, df2]).drop_duplicates()
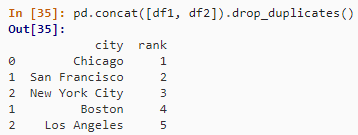
6. limit关键字
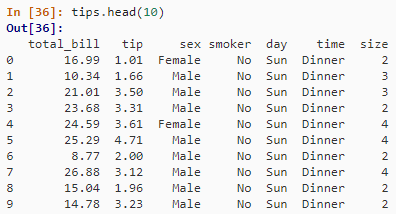
SELECT * FROM tips
LIMIT 10;
tips.head(10)
7. SQL和pandas的一些等效操作
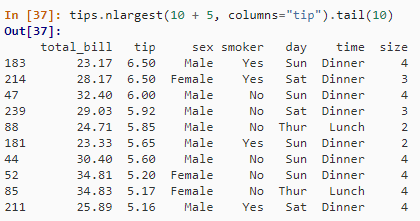
① 具有偏移量的前 n 行
-- MySQL
SELECT * FROM tips
ORDER BY tip DESC
LIMIT 10 OFFSET 5;
tips.nlargest(10 + 5, columns="tip").tail(10)
② 每组前 n 行
# 需要窗口函数
SELECT * FROM (
SELECT
t.*,
ROW_NUMBER() OVER(PARTITION BY day ORDER BY total_bill DESC) AS rn
FROM tips t
)
WHERE rn < 3
ORDER BY day, rn;
(
tips.assign(
rn=tips.sort_values(["total_bill"], ascending=False)
.groupby(["day"])
.cumcount()
+ 1
)
.query("rn < 3")
.sort_values(["day", "rn"])
)

SELECT * FROM (
SELECT
t.*,
RANK() OVER(PARTITION BY sex ORDER BY tip) AS rnk
FROM tips t
WHERE tip < 2
)
WHERE rnk < 3
ORDER BY sex, rnk;
(
tips.assign(
rn=tips.sort_values(["total_bill"].rank(method='first'), ascending=False)
)
.query("rnk < 3")
.sort_values(["day", "rnk"])
)

(
tips[tips["tip"] < 2]
.assign(rnk_min=tips.groupby(["sex"])["tip"].rank(method="min"))
.query("rnk_min < 3")
.sort_values(["sex", "rnk_min"])
)

8. update关键字
UPDATE tips
SET tip = tip*2
WHERE tip < 2;
tips.loc[tips["tip"] < 2, "tip"] *= 2
9. delete关键字
DELETE FROM tips
WHERE tip > 9;
tips = tips.loc[tips["tip"] <= 9]
--END--
老表推荐
图书介绍:《Python自动化测试实战》本书从自动化测试理论入手,全面地阐述自动化测试的意义及实施过程。全文以Python语言驱动,结合真实案例分别对主流自动化测试工具Selenium、RobotFramework、Postman、Python Requests、Appium等进行系统讲解。通过学习本书,读者可以快速掌握主流自动化测试技术,并帮助读者丰富测试思维,提高Python编码能力。
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 优秀的读者都知道,“点赞”传统美德不能丢
评论