
高效Transformer | 85FPS!CNN + Transformer语义分割的又一境界,真的很快!


本文提出了一种用于城市场景语义分割的高效混合Transformer(EHT),其利用CNN和Transformer结合学习全局-局部上下文来加强特征表征,性能优于ABCNet等网络,速度高达83.4FPS!代码将开源!
作者单位:武汉大学,兰卡斯特大学等
1简介
高分辨率城市场景图像的语义分割在土地覆盖制图、城市变化检测、环境保护和经济评估等广泛的实际应用中起着至关重要的作用。卷积神经网络采用分层特征表示,具有很强的局部上下文特征提取的能力。然而,卷积层的局部特性限制了网络捕获全局信息,而这个特点对于改善高分辨率图像分割至关重要。
最近, Transformer成为计算机视觉领域的热门话题。Vision Transformer也展示了其全局信息建模的强大能力,推动了许多视觉任务,例如图像分类、目标检测,尤其是语义分割。
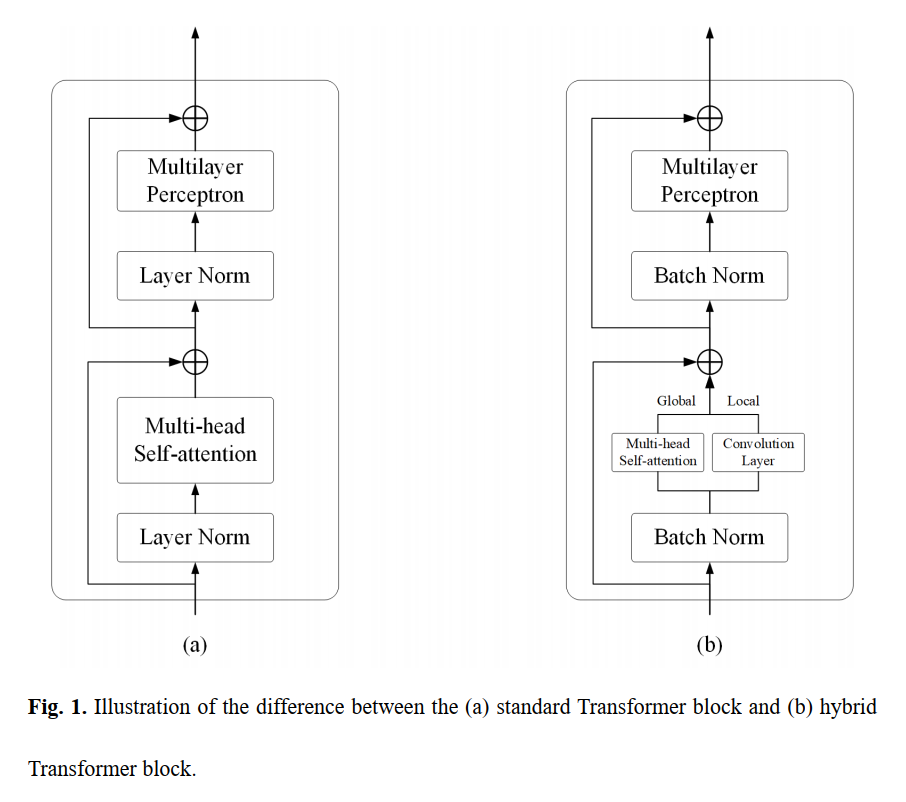
在本文中提出了一种用于城市场景图像语义分割的高效混合Transformer(EHT)。EHT利用CNN和ransformer结合设计学习全局-局部上下文来加强特征表示。
大量实验表明,与最先进的方法相比, EHT具有更高的效率和具有竞争力的准确性。具体来说,所提出的EHT在UAVid测试集上实现了67.0%的mloU,并且明显优于其他轻量级模型。
2本文方法
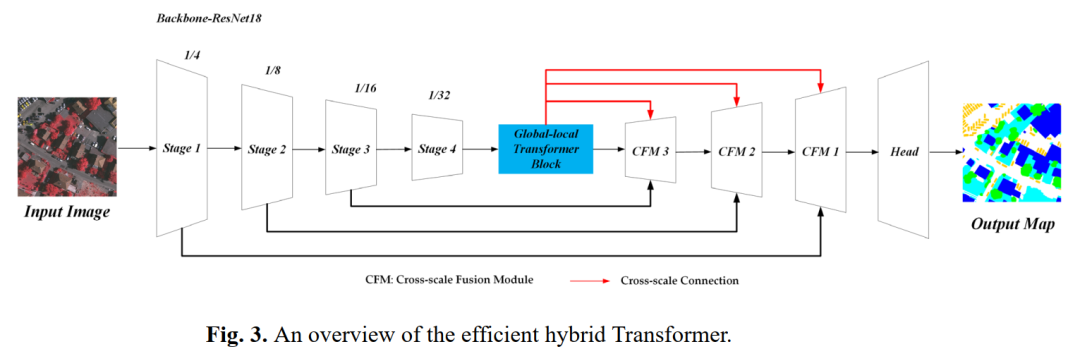
所提出的efficient hybrid Transformer如图所示。将Global-Local Transformer Block附加到ResNet18 Backbone的顶部,就像BottleNeck Transformer一样。利用3个具有3个跨尺度连接的跨尺度融合模块来聚合多层特征。
2.1 Global-local Transformer Block
提出的Global-local Transformer Block(GLTB)的细节如下图所示。主要模块global-local attention block是一种混合结构,采用linear multi-head self-attention捕获全局上下文信息,采用卷积层提取局部上下文信息。
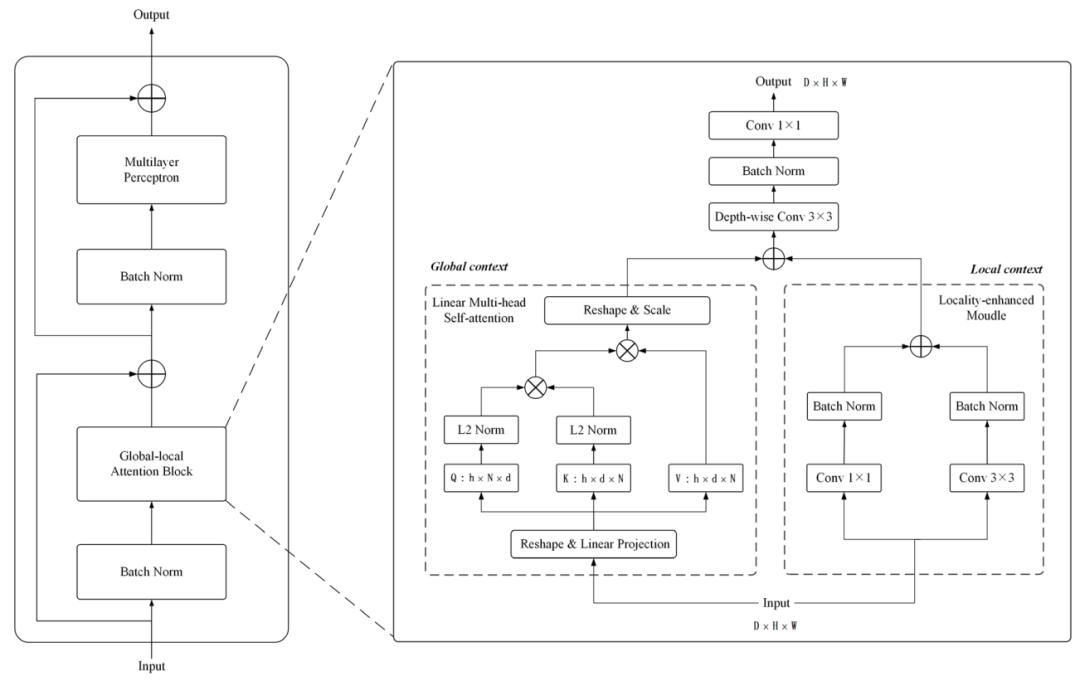
最后,对全局上下文和局部上下文应用一个add操作来提取全局-局部上下文。
1、Linear multi-head self-attention
本文提出了一种线性注意力机制,用泰勒展开的一阶近似来代替softmax函数。本文将线性注意力改进为线性多头自注意力,以获得更高的效率和更强的序列建模。具体公式推导过程如下:
设归一化函数为softmax,则自注意力注意产生的结果矩阵的第
行可表示为:
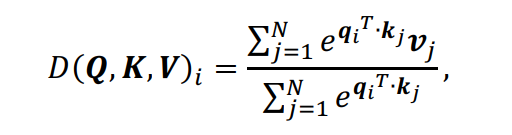
其中
是第
个特征。根据泰勒的扩展:
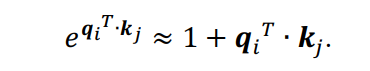
为了保证上述近似是非负的,
和
被归一化
,从而确保
:
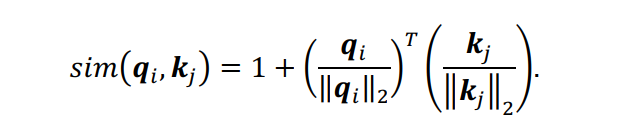
因此,(1)式可以重写为(4)式,并简化为(5)式:
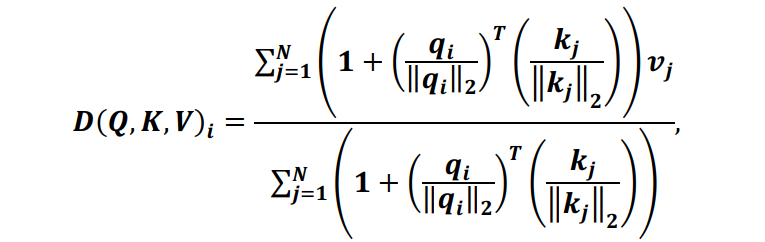
进而有:
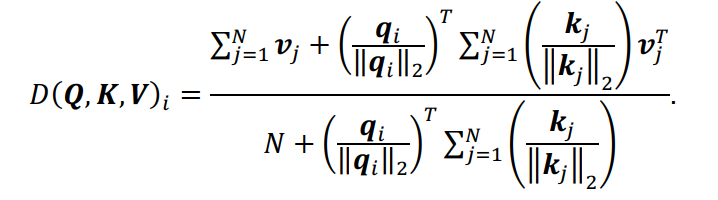
上式可以转化为矢量形式:
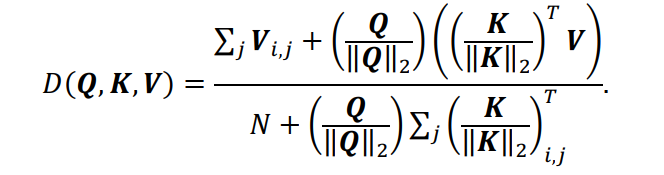
和
可以计算得到并可以为每个query重用。
注意: 在线性多头自注意力的输出上部署了一个可训练的尺度因子,以实现稳定的上下文聚合。
2、Locality-enhanced模块
采用2个并行卷积层,然后是一个BN操作来提取局部上下文信息。
生成的全局局部上下文进一步进行深度卷积、批归一化操作和
卷积,以增强泛化能力。
2.2 Cross-scale融合模块
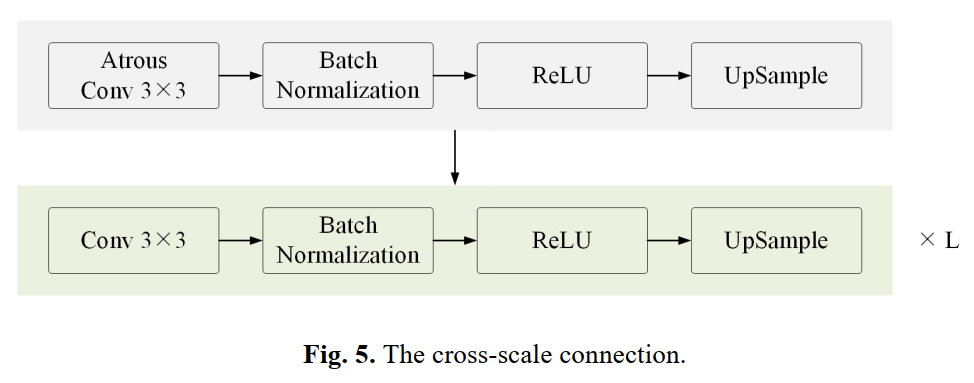
1、Cross-scale连接
采用两个并行卷积层,然后是一个BN操作来提取局部上下文信息。Cross-scale连接的细节如下图所示。上采样操作的比例因子为2。L为重复次数。3个跨尺度连接对应3个跨尺度融合模块。3个跨尺度连接的Atrous卷积扩张率分别为6、12和18。
2、加权特征融合
将Cross-scale连接生成的3种语义特征通过加权元素求和运算与相应的残差特征和上采样的全局局部语义特征进行聚合,以增强泛化能力。公式如下:
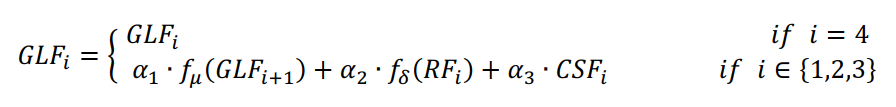
其中
为Resize操作,用来统一
和
;
为
卷积操作,用来统一
和
通道的数量;而
为3个特征的权重系数,其中
。
进一步聚合作为Head的输入,用于最终的分割。
3实验
Backbone:可以通过ResNet-18和像UNet一样的逐层特征融合来构建。
Backbone+CFM:用跨尺度融合模块代替逐层特征融合来构建一个简单的变体。利用该变体验证了跨尺度融合模块的有效性。
Backbone+CFM+GLTB:将Global-Local Transformer块插入到Baseline+CFM来生成整个EHT,可以证明所提方法的有效性。
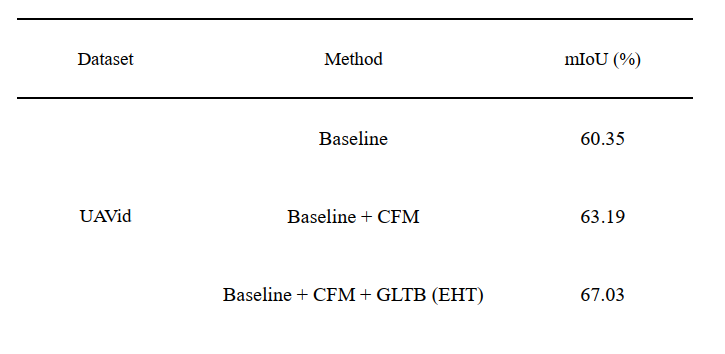
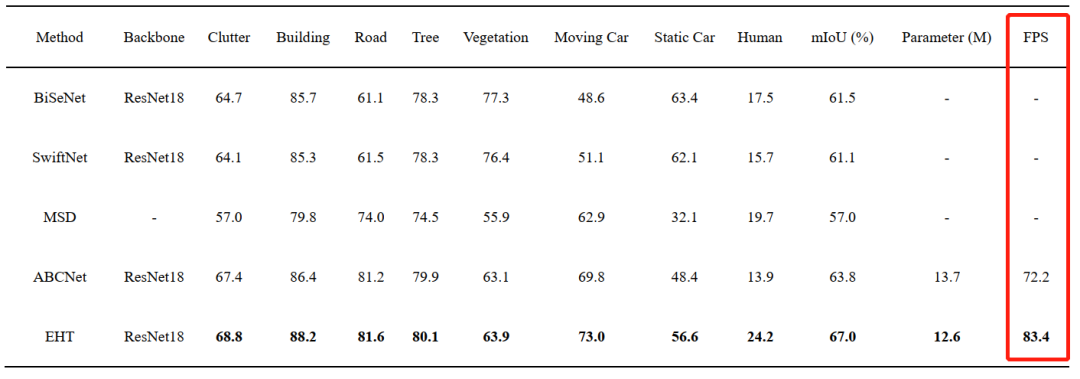

可以看出本文所提模块可以很好的兼顾全局和局部的上下文信息,值得小伙伴们进行学习和借鉴。
4参考
[1].Efficient Hybrid Transformer: Learning Global-local Context for Urban Sence Segmentation
5推荐阅读

【书童的学习笔记】集智小书童建议你这么学习Transformer,全干货!!!

改进UNet | 透过UCTransNet分析ResNet+UNet是不是真的有效?

详细解读TPH-YOLOv5 | 让目标检测任务中的小目标无处遁形
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
