
ConvNeXt:全面超越Swin Transformer的CNN
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
自从ViT提出之后,在过去的一年里(2021年),基于transformer的模型在计算机视觉各个领域全面超越CNN模型。然而,这很大程度上都归功于Local Vision Transformer模型,Swin Transformer是其中重要代表。原生的ViT模型其计算量与图像大小的平方成正比,而Local Vision Transformer模型由于采用local attention(eg. window attention),其计算量大幅度降低,除此之外,Local Vision Transformer模型往往也采用金字塔结构,这使得它更容易应用到密集任务如检测和分割中,因为密集任务往往输入图像分辨率较高,而且也需要多尺度特征(eg. FPN)。虽然Local Vision Transformer模型超越了CNN模型,但是它却越来越像CNN了:首先locality是卷积所具有的特性,其次金字塔结构也是主流CNN模型所采用的设计。那么问题来了,CNN模型相比Local Vision Transformer模型到底差在哪里?能否设计一个纯粹的CNN模型实现和Local Vision Transformer模型一样的效果?近日,MetaAI在论文A ConvNet for the 2020s中从ResNet出发并借鉴Swin Transformer提出了一种新的CNN模型:ConvNeXt,其效果无论在图像分类还是检测分割任务上均能超过Swin Transformer,而且ConvNeXt和vision transformer一样具有类似的scalability(随着数据量和模型大小增加,性能同比提升)。
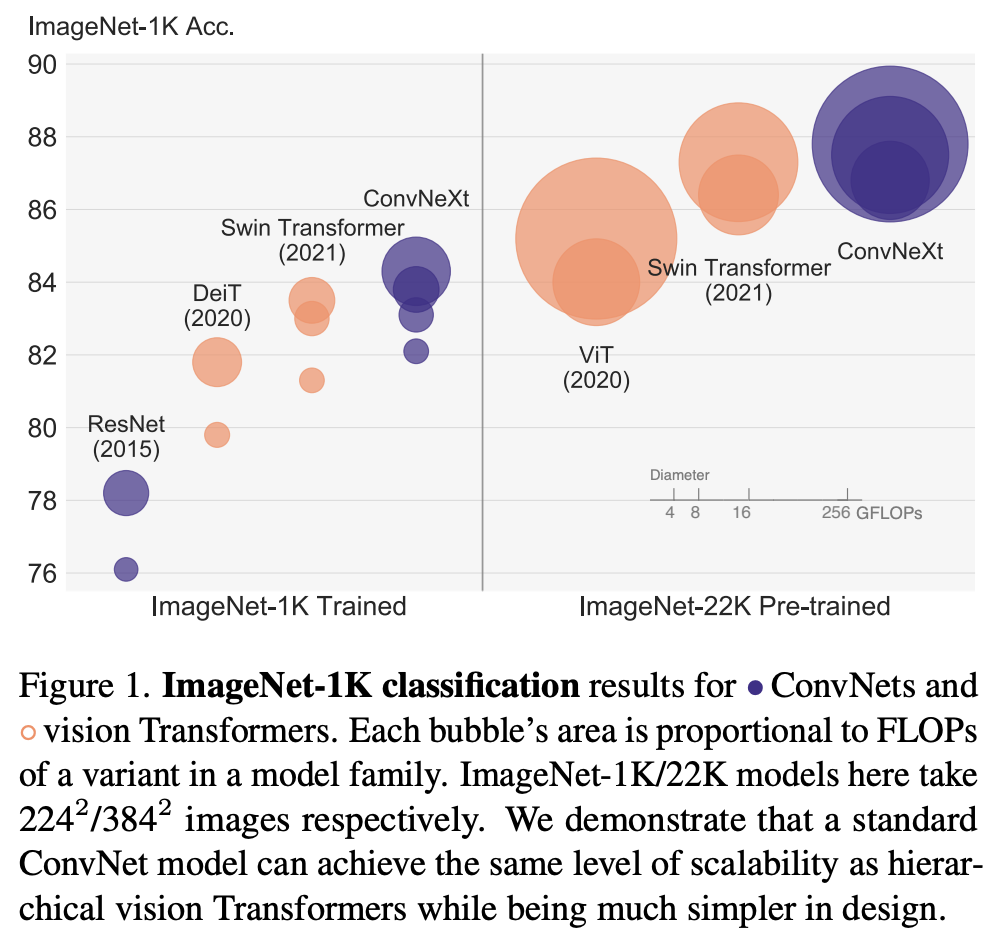
从ResNet到ConvNeXt
论文的整体思路是从原始的ResNet出发,通过借鉴Swin Transformer的设计来逐步地改进模型。论文共选择了两个不同大小的ResNet模型:ResNet50和ResNet200,其中ResNet50和Swin-T有类似的FLOPs(4G vs 4.5G),而ResNet200和Swin-B有类似的FLOPs(15G)。首先做的改进是调整训练策略,然后是模型设计方面的递进优化:宏观设计->ResNeXt化->改用Inverted bottleneck->采用large kernel size->微观设计。由于模型性能和FLOPs强相关,所以在优化过程中尽量保持FLOPs的稳定。
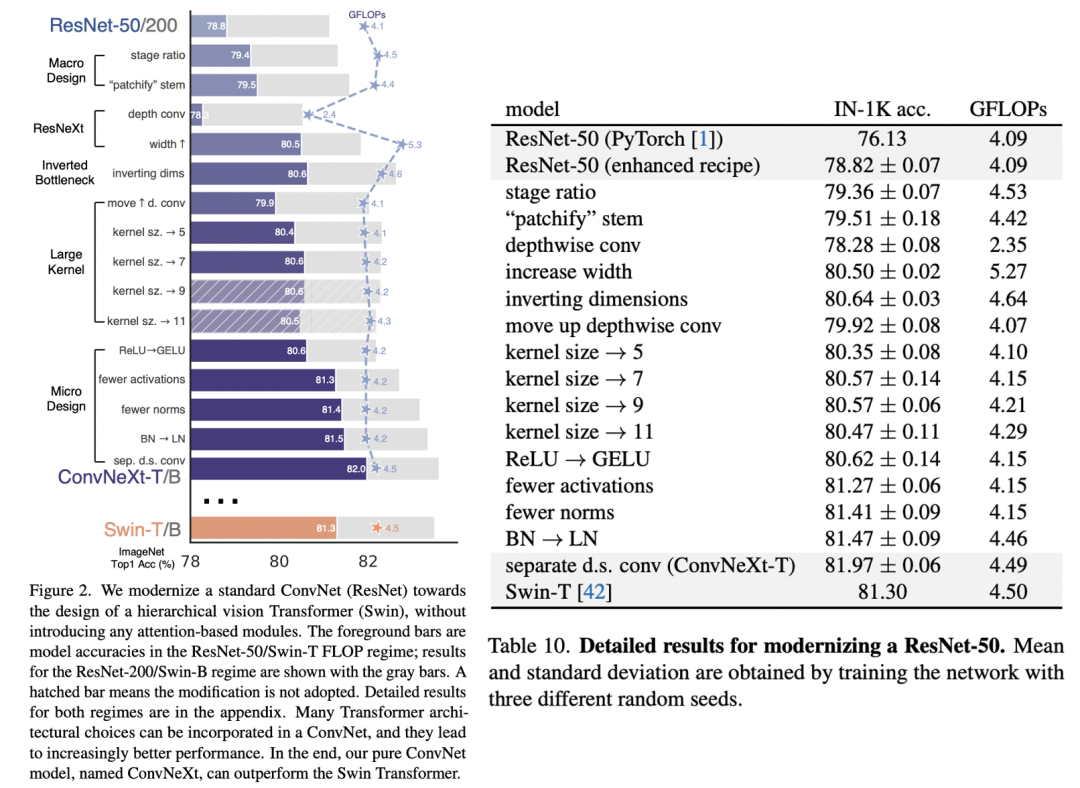
(1)训练策略
原生的ViT需要大规模数据的预训练,而MetaAI在DeiT论文中提出了一种增强版本的训练策略来解决这个问题,这个训练策略也被随后的vision transformer模型所采用。对于ResNet50,其训练策略比较简单(torchvision版本):batch size是32*8,epochs为90;优化器采用momentum=0.9的SGD,初始学习速率为0.1,然后每30个epoch学习速率衰减为原来的0.1;正则化只有L2,weight decay=1e-4;数据增强采用随机缩放裁剪(RandomResizedCrop)+水平翻转(RandomHorizontalFlip)。而DeiT的训练策略则非常heavy:采用了比较多的数据增强如Mixup,Cutmix和RandAugment;训练的epochs增加至300;训练的optimizer采用AdamW,学习速率schedule采用cosine decay;采用smooth label和EMA等优化策略。这里直接将DeiT的训练策略(具体参数设置如下表)应用在ResNet50模型,其性能从原来的76.1%提升至78.8%(+2.7)。这也说明vision transformer模型相比CNN模型的提升很多程度上归功于训练策略的优化,关于这个问题,另外一篇论文Visformer也论证过这一点,而且最近timm库和torchvison库也分别发布了ResNet新的训练策略,并将ResNet50的性能提升至80%+。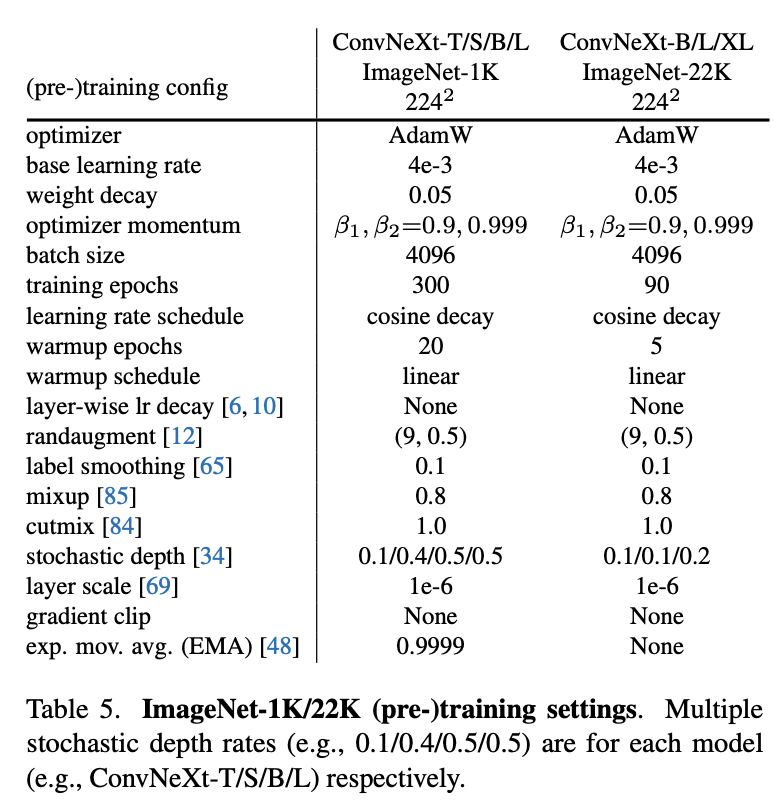
(2)宏观设计
Swin Transfomer和CNN一样也采用金字塔结构:包含4个stage,每个stage输出不同尺度的特征。这里考虑Swin Transformer和ResNet在宏观设计上的区别,主要有两点:每个stage的计算量占比以及stem cell结构(即stage1之前的模块)。首先是各个stage的计算量占比,对比ResNet50,4个stage的blocks数量分别是(3,4,6,3),而Swin-T的设置为(2,2,6,2),4个stage的计算量比约为1:1:3:1。这里调整ResNet50各个stage的blocks数量以和Swin-T一致:从原来的(3,4,6,3)调整至(3,3,9,3)。调整之后模型性能从78.8%提升至79.4%,不过这里要注意的一点是,调整后其实blocks数量增加了,模型的FLOPs从原来的4G增加至4.5G,基本和Swin-T一致了,所以这个性能的提升很大程度上归功于FLOPs的增加。关于各个stage的计算量分配,并没有一个理论上的参考,不过RegNet和EfficientNetV2论文中都指出,后面的stages应该占用更多的计算量。**第二个就是stem的区别。**对于Swin-T模型,其stem是一个patch embedding layer,实际上就是一个stride=4的4x4 conv。而ResNet50的stem相对更复杂一些:首先是一个stride=2的7x7 conv,然后是一个stride=2的3x3 max pooling。两种stem最后均是得到1/4大小的特征,所以这里可以直接用Swin的stem来替换ResNet的stem,这个变动对模型效果影响较小:从79.4%提升至79.5%。对于ViT模型,其patch size一般较大(eg. 16),只采用一个stride较大的conv来做patch embedding往往会存在一定问题,比如Mocov3论文中就指出patch embed可能会导致训练不稳定,而论文Early Convolutions Help Transformers See Better指出将patch embed设计成几个堆叠的stride=2的3*3 conv,无论是在模型效果上,还是在训练稳定性以及收敛速度都更好;而Swin-T的patch size相对较小,不会出现ViT的上述问题,不过Swin-T采用的是non-overlapping conv,后面有论文指出采用overlapping conv(eg stride=4的7x7 conv)会带来一定的性能提升。
(3)ResNeXt化
相比ResNet,ResNeXt通过采用group conv来提升性能,标准的conv其输入是所有的channels,而group conv会对channels进行分组来减少计算量,这样节省下来的计算量用来增加网络的width即特征channels。对于group conv,其最极端的情况就是每个channel一个group,这样就变成了depthwise conv(简称dw conv),dw conv首先在MobileNet中应用,后来也被其它CNN模型广泛采用。对于dw conv,其和local attention有很多的相似的地方,local attention其实就是对window里的各个token的特征做加权和,而且操作是per-channel的;而dw conv是对kernel size范围的token的特征求加权和,也是分channel的。这里的最大区别就是:self-attention的权重是动态计算的(data dependent),而dw conv的权重就是学习的kernel,关于这点,微软的论文Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight有深入的分析。 这里将ResNet50中的3x3 conv替换成3x3 dw conv,为了弥补FLOPs的减少,同时将ResNet50的base width从原来的64增加至96(和Swin-T一致,这里的base width是指stem后的特征大小),此时模型的FLOPs有所增加(5.3G),模型性能提升至80.5%。
这里将ResNet50中的3x3 conv替换成3x3 dw conv,为了弥补FLOPs的减少,同时将ResNet50的base width从原来的64增加至96(和Swin-T一致,这里的base width是指stem后的特征大小),此时模型的FLOPs有所增加(5.3G),模型性能提升至80.5%。
(4)改用Inverted bottleneck
如果把self-attention看成一个dw conv的话(这里忽略self-attention的linear projection操作),那么一个transformer block可以近似看成一个inverted bottleneck,因为MLP等效于两个1x1 conv,并且MLP中间隐含层特征是输入特征大小的4倍(expansion ratio=4)。inverted bottleneck最早在MobileNetV2中提出,随后的EfficientNet也采用了这样的结构。ResNet50采用的是正常的residual bottleneck,这里将其改成inverted bottleneck,即从图(a)变成图(b),虽然dw conv的计算量增加了,但是对于包含下采样的residual block中,用于shortcut的1x1 conv计算量却大大降低,最终模型的FLOPs减少为4.6G。这个变动对ResNet50的影响较小(80.5%->80.6%)。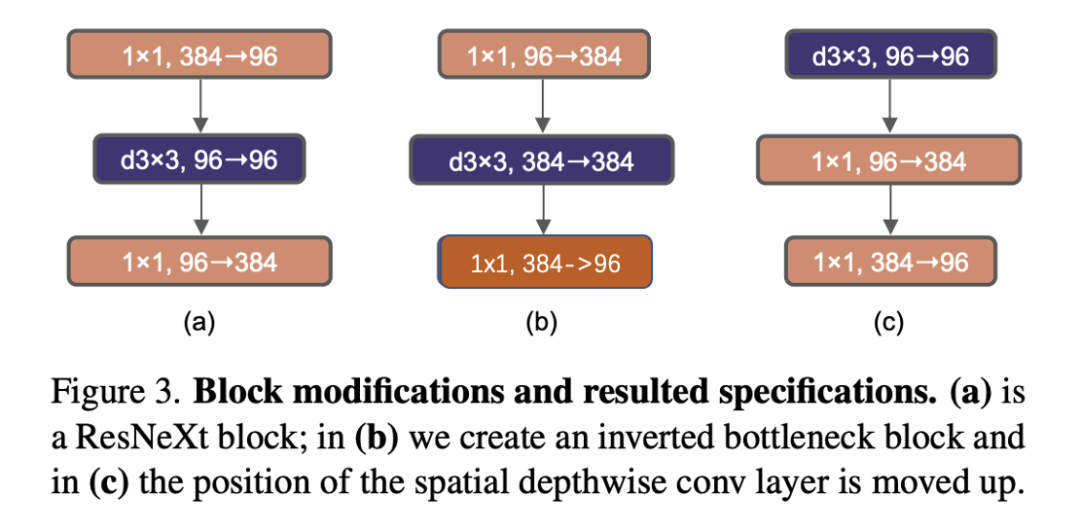
(5)采用large kernel size
自从VGG之后,主流的CNN往往采用较小的kernel size,如3x3和5x5,其中3x3 conv在GPU上有高效的实现。然而Swin-T采用的window size为7x7,这比3x3 conv对应的windwo size要大得多,所以这里考虑采用更大的kernel size。在这之前,首先将dw conv移到inverted bottleneck block的最开始,如上图(c)所示。对于transformer block,其实self-attention也是在开始,同时由于采用inverted bottleneck,将dw conv移动到最前面可以减少计算量(4.1G),后续采用较大的kernel size后模型的FLOPs变动更少。由于模型FLOPs的降低,模型性能也出现一定的下降:80.6%->79.9%。然后调整dw conv的kernel size,这里共实验了5种kernel size:3x3,5x5,7x7,9x9和11x11。实验发现kernel size增加,模型性能有提升,但是在7x7之后采用更大的kernel size性能达到饱和。所以最终选择7x7,这样也和Swin-T的window size一致,由于前面的dw conv位置变动,采用7x7的kernel size基本没带来FLOPs的增加。采用7x7 dw conv之后,模型的性能又回到80.6%。
(6)微观设计
经过前面的改动,模型的性能已经提升到80%以上,此时改动后的ResNet50也和Swin-T在整体结构上很类似了,下面我们开始关注一些微观设计上的差异,或者说是layer级别的不同。首先是激活函数,CNN模型一般采用ReLU,而transformer模型常常采用GELU,两者的区别如下图所示。这里把激活函数都从ReLU改成GELU,模型效果没有变化(80.6%)。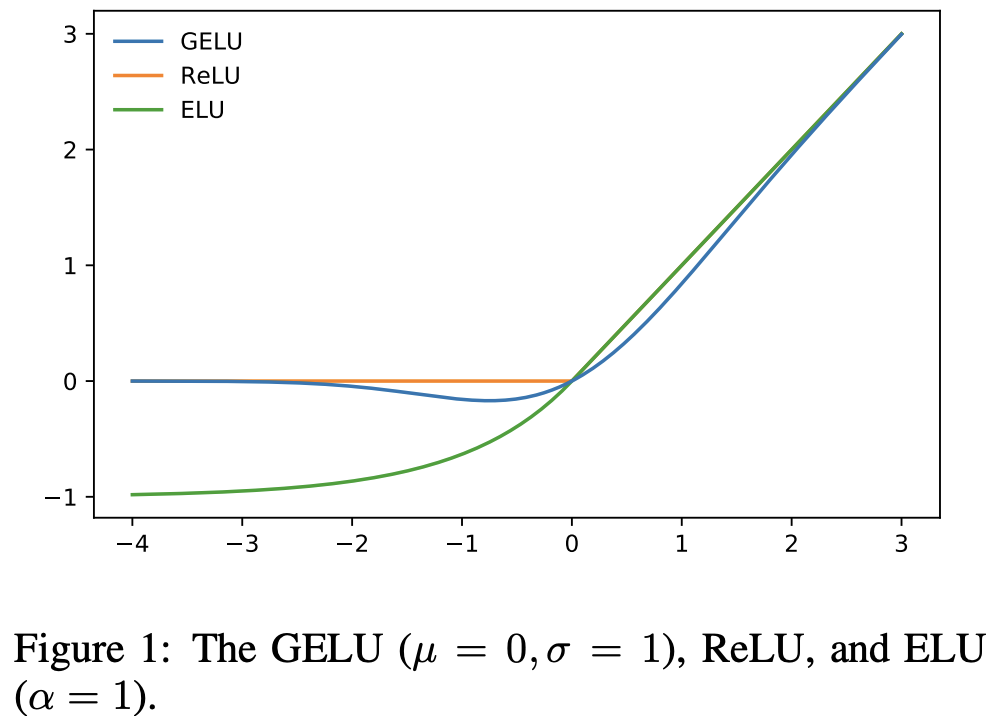 另外的一个差异是transformer模型只在MLP中间采用了非线性激活,而CNN模型常常每个conv之后就会用跟一个非线性激活函数。如下图示,这里只保留中间1x1 conv之后的GELU,就和Swin-T基本保持一致了,这个变动使模型性能从80.6%提升至81.3%。
另外的一个差异是transformer模型只在MLP中间采用了非线性激活,而CNN模型常常每个conv之后就会用跟一个非线性激活函数。如下图示,这里只保留中间1x1 conv之后的GELU,就和Swin-T基本保持一致了,这个变动使模型性能从80.6%提升至81.3%。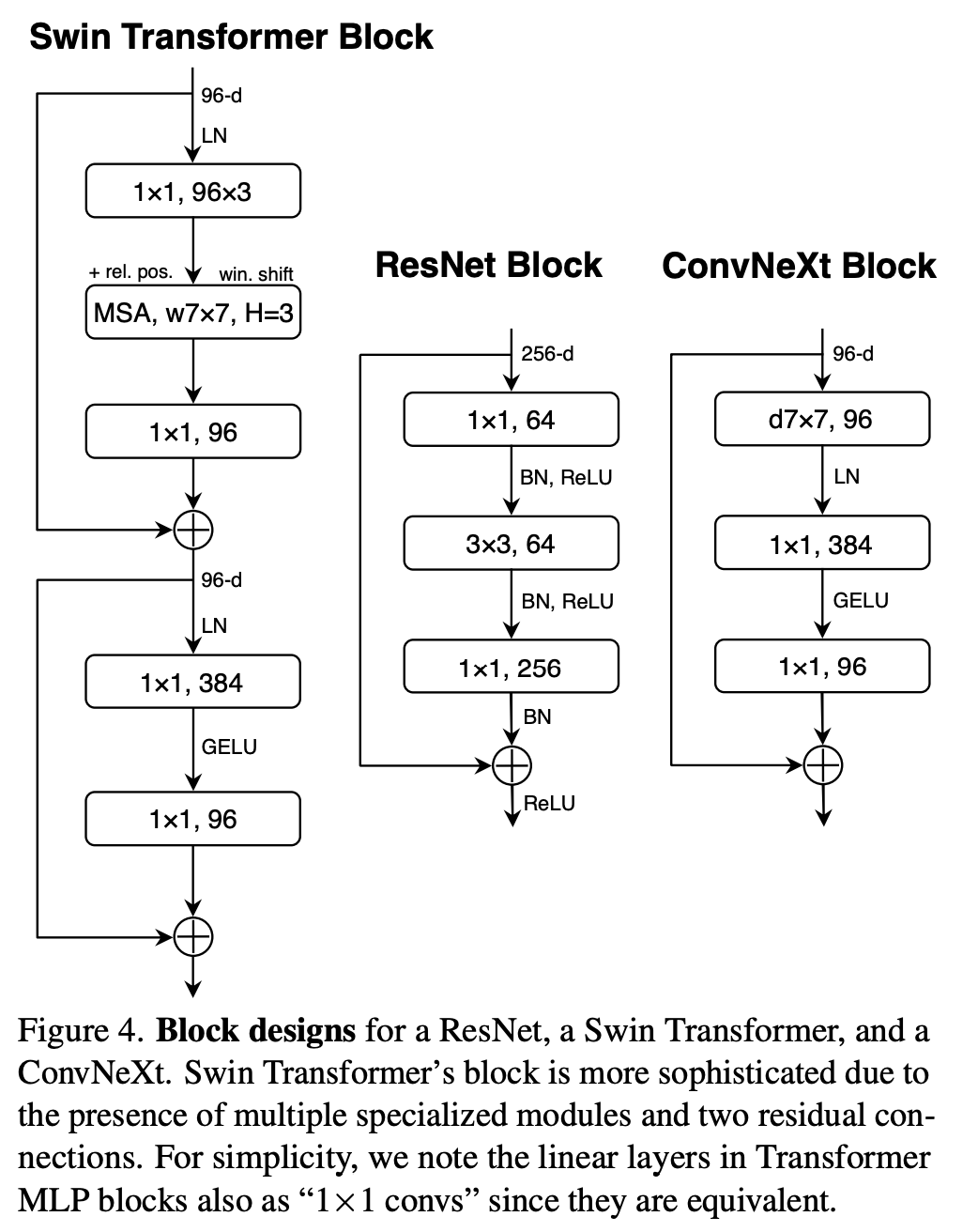 对于norm层,也存在和激活函数一样的问题,transformer中只在self-attention和MLP的开始采用了LayerNorm,而ResNet每个conv之后采用BatchNorm,比transformer多一个norm层。这里去掉其它的BatchNorm,只保留中间1x1 conv前的BatchNorm,此时模型性能有0.1%的提升。实际上要和transformer保持一致,应该在block最开始增加一个BatchNorm,但是这个并没有提升性能,所以最终只留下了一个norm层。另外,transformer的norm层采用LayerNorm,而CNN常采用BatchNorm,一般情况下BatchNorm要比LayerNorm效果要好,但是BatchNorm受batch size的影响较大。这里将BatchNorm替换成LayerNorm后,模型性能只有微弱的下降(80.5%)。最后一个差异是下采样,ResNet中的下采样一般放在每个stage的最开始的block中,采用stride=2的3x3 conv;但是Swin-T采用分离的下采样,即下采样是放在两个stage之间,通过一个stride=2的2x2 conv(论文中叫patch merging layer)。但是实验发现,如果直接改用Swin-T的下采样,会出现训练发散问题,解决的办法是在添加几个norm层:在stem之后,每个下采样层之前以及global avg pooling之后都增加一个LayerNom(Swin-T也是这样做的)。最终模型的性能提升至82.0%,超过Swin-T(81.3%)。
对于norm层,也存在和激活函数一样的问题,transformer中只在self-attention和MLP的开始采用了LayerNorm,而ResNet每个conv之后采用BatchNorm,比transformer多一个norm层。这里去掉其它的BatchNorm,只保留中间1x1 conv前的BatchNorm,此时模型性能有0.1%的提升。实际上要和transformer保持一致,应该在block最开始增加一个BatchNorm,但是这个并没有提升性能,所以最终只留下了一个norm层。另外,transformer的norm层采用LayerNorm,而CNN常采用BatchNorm,一般情况下BatchNorm要比LayerNorm效果要好,但是BatchNorm受batch size的影响较大。这里将BatchNorm替换成LayerNorm后,模型性能只有微弱的下降(80.5%)。最后一个差异是下采样,ResNet中的下采样一般放在每个stage的最开始的block中,采用stride=2的3x3 conv;但是Swin-T采用分离的下采样,即下采样是放在两个stage之间,通过一个stride=2的2x2 conv(论文中叫patch merging layer)。但是实验发现,如果直接改用Swin-T的下采样,会出现训练发散问题,解决的办法是在添加几个norm层:在stem之后,每个下采样层之前以及global avg pooling之后都增加一个LayerNom(Swin-T也是这样做的)。最终模型的性能提升至82.0%,超过Swin-T(81.3%)。
经过6个方面的修改或者优化,最终得到的模型称为ConvNeXt,其模型结构如下所示,可以看到,ConvNeXt-T和Swin-T整体结构基本一致,而且模型FLOPs和参数量也基本一样,唯一的差异就是dw conv和W-MSA(MSA的前面和后面都包含linear projection,等价1x1 conv),由于dw conv和W-MSA的计算量存在差异,所以ConvNeXt-T比Swin-T包含更多的blocks。另外MSA是permutation-invariance的,所以W-MSA采用了相对位置编码;而且Swin-T需要采用shifted window来实现各个windows间的信息交互;而相比之下,ConvNeXt-T不需要这样的特殊处理。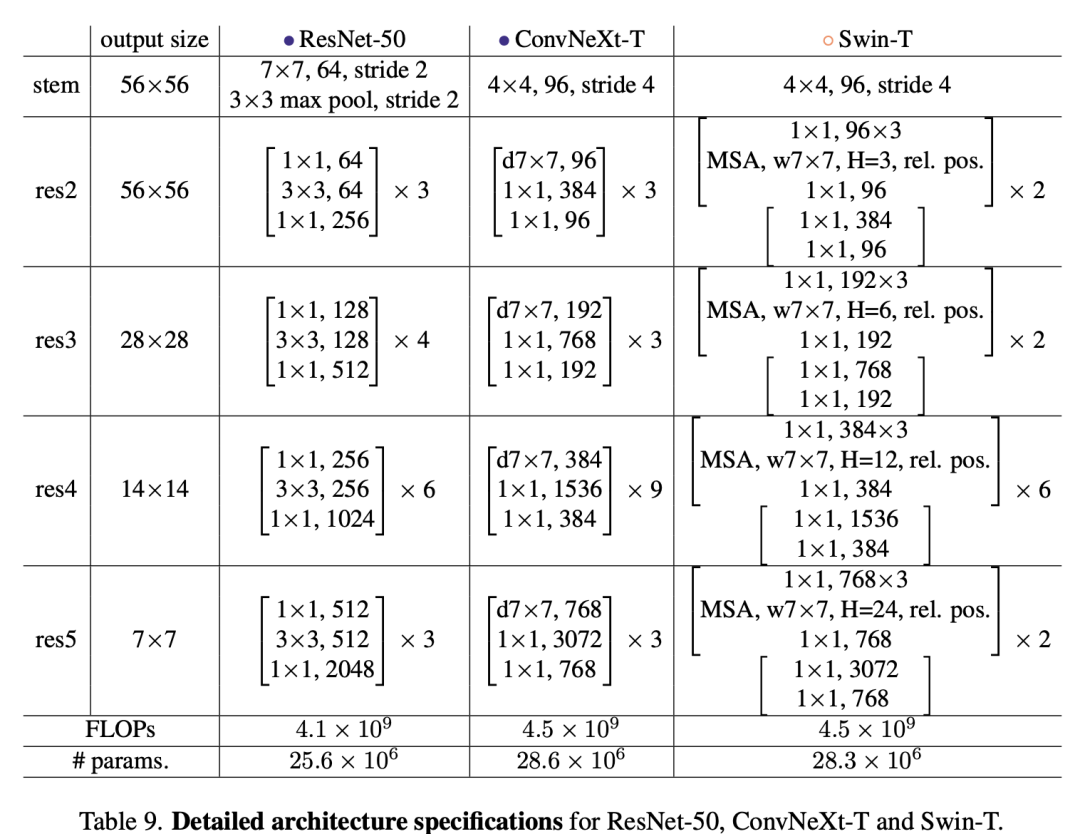 从上面的分析来看,dw conv的性能是不低于W-MSA的,这个其实早在微软的论文Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight中被验证过,这篇论文设计了DW Conv模型,它也和Swin模型结构一致,差别是将W-MSA直接换成了7x7 DW conv,由于保留了两个linear层,所以各个stage的blocks数量也一致。DW Conv-T和Swin-T的性能是一样的(81.3%),略低于ConvNeXt-T。
从上面的分析来看,dw conv的性能是不低于W-MSA的,这个其实早在微软的论文Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight中被验证过,这篇论文设计了DW Conv模型,它也和Swin模型结构一致,差别是将W-MSA直接换成了7x7 DW conv,由于保留了两个linear层,所以各个stage的blocks数量也一致。DW Conv-T和Swin-T的性能是一样的(81.3%),略低于ConvNeXt-T。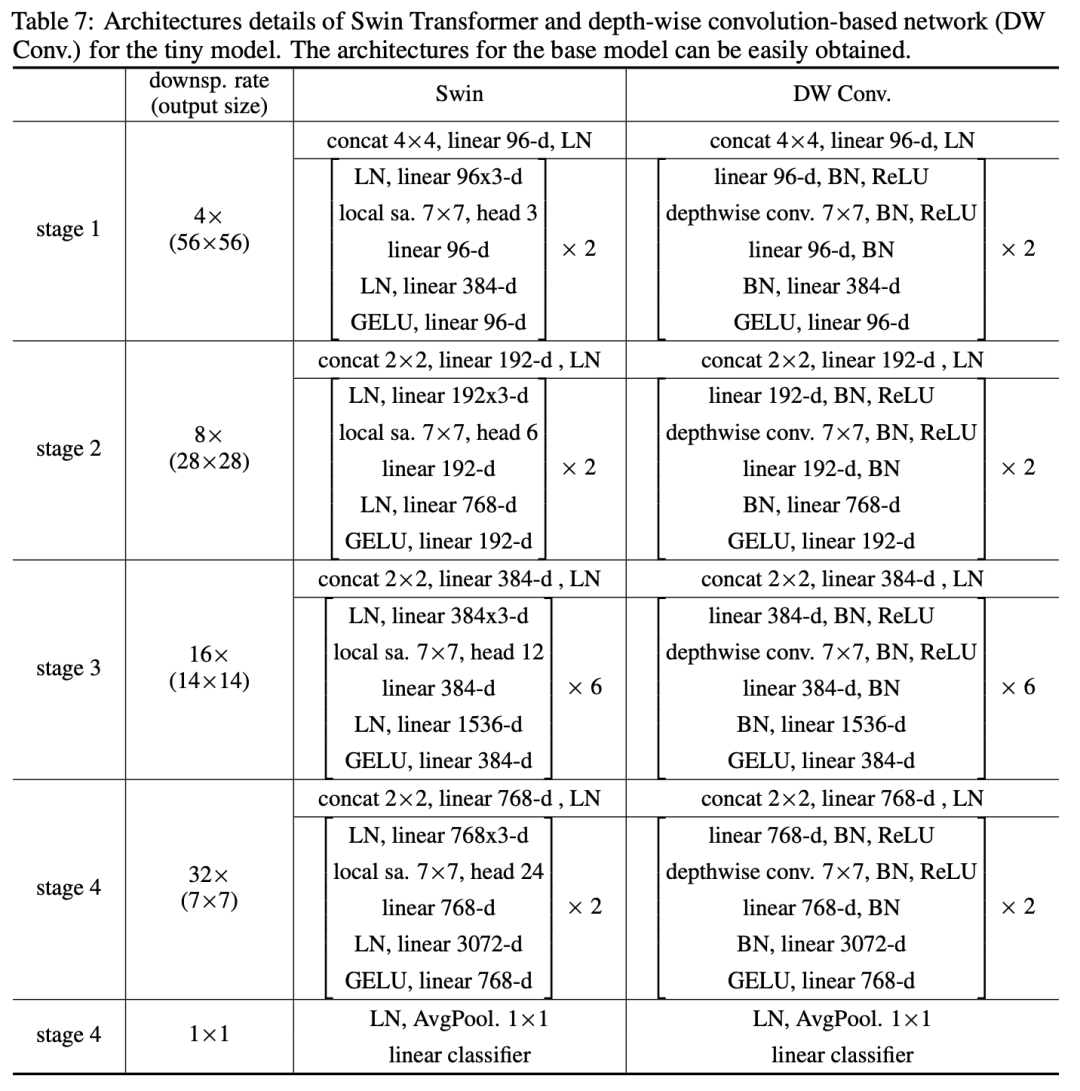 此外另外一篇论文What Makes for Hierarchical Vision Transformer? 也指出如果我们直接把Swin中的W-MSA换成Linear,DW Linear或者MLP,模型性能也不会太差。
此外另外一篇论文What Makes for Hierarchical Vision Transformer? 也指出如果我们直接把Swin中的W-MSA换成Linear,DW Linear或者MLP,模型性能也不会太差。
ConvNeXt
前面我们从ResNet50的Swin-T化,最终得到了ConvNeXt-T模型,对于更大的模型,可以通过调整特征的维度C和各个stage的blocks数量。论文共设计5个ConvNeXt模型,其中前4个模型分别对标Swin,而最后ConvNeXt-XL是一个更大的模型,用来验证模型的scalability。
ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3) ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3) ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3) ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3) ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
ConvNeXt在ImageNet1K数据集上的分类效果如下所示,可以看到,ConvNeXt在不同的FLOPs均可以超过Swin,如果采用ImageNet21K预训练后,模型性能有进一步的提升,其中ConvNeXt-XL可以达到87.8%,仅略低于目前的SOTA一点(MViT-H, 512^2,88.8%,只有ImageNet21K)。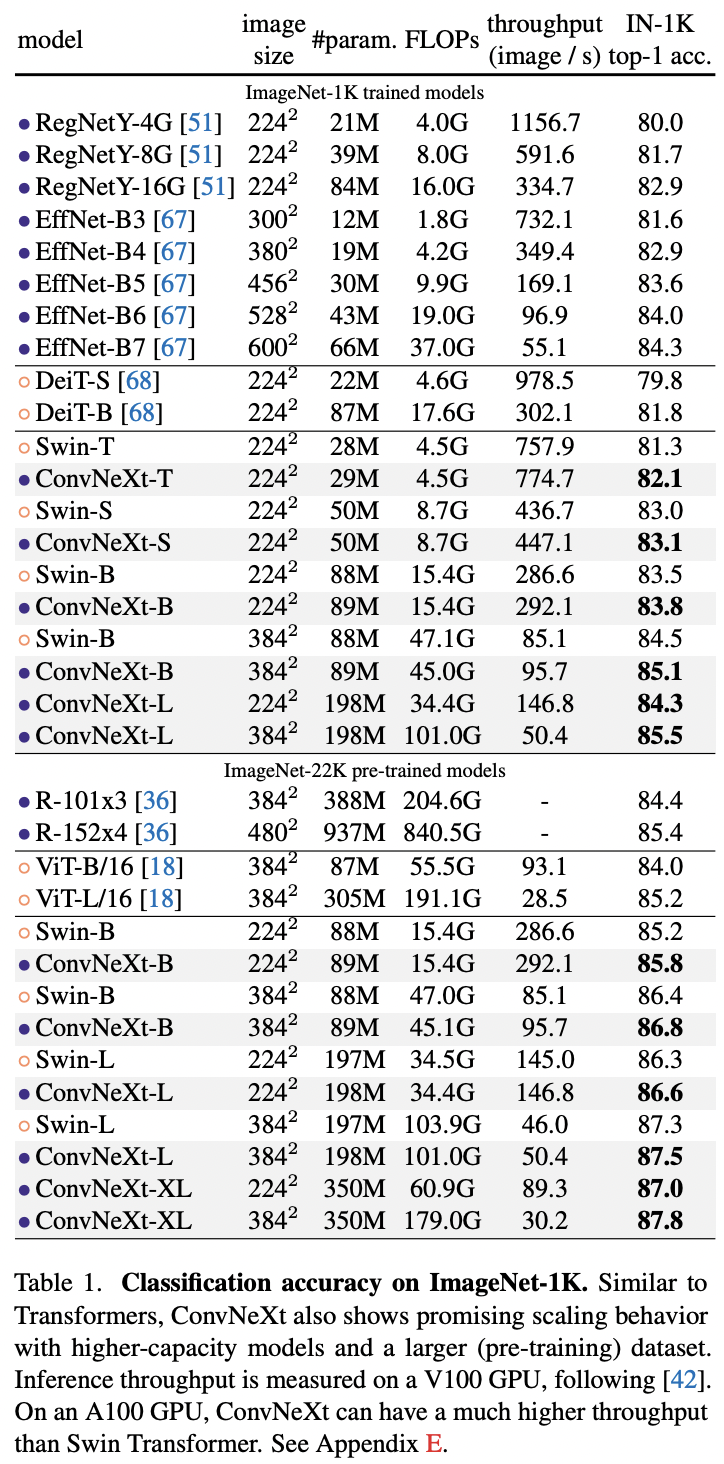
在下游任务检测和分割上,ConvNeXt也可以超过Swin,如下表所示: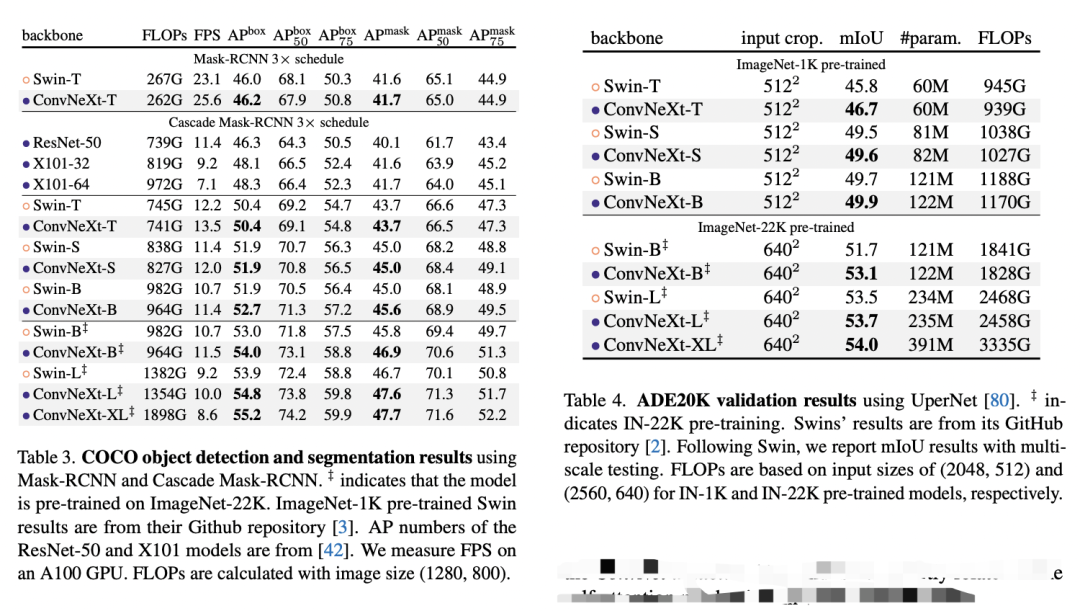 由于FLOPs往往不能准确地反映实际的推理速度,所以上面的对比结果也包括模型速度(分类上用throughout,检测上用FPS),可以看到在实际推理速度上,ConvNeXt也略好于Swin。在显存使用上,两者也相当,比如基于ConvNeXt-B的Cascade Mask-RCNN需要17.4GB peak memory,而Swin-B 需要18.5GB。另外,如果在A100上(支持TF32),采用channel last,ConvNeXt相比Swin有明显的速度优势:
由于FLOPs往往不能准确地反映实际的推理速度,所以上面的对比结果也包括模型速度(分类上用throughout,检测上用FPS),可以看到在实际推理速度上,ConvNeXt也略好于Swin。在显存使用上,两者也相当,比如基于ConvNeXt-B的Cascade Mask-RCNN需要17.4GB peak memory,而Swin-B 需要18.5GB。另外,如果在A100上(支持TF32),采用channel last,ConvNeXt相比Swin有明显的速度优势: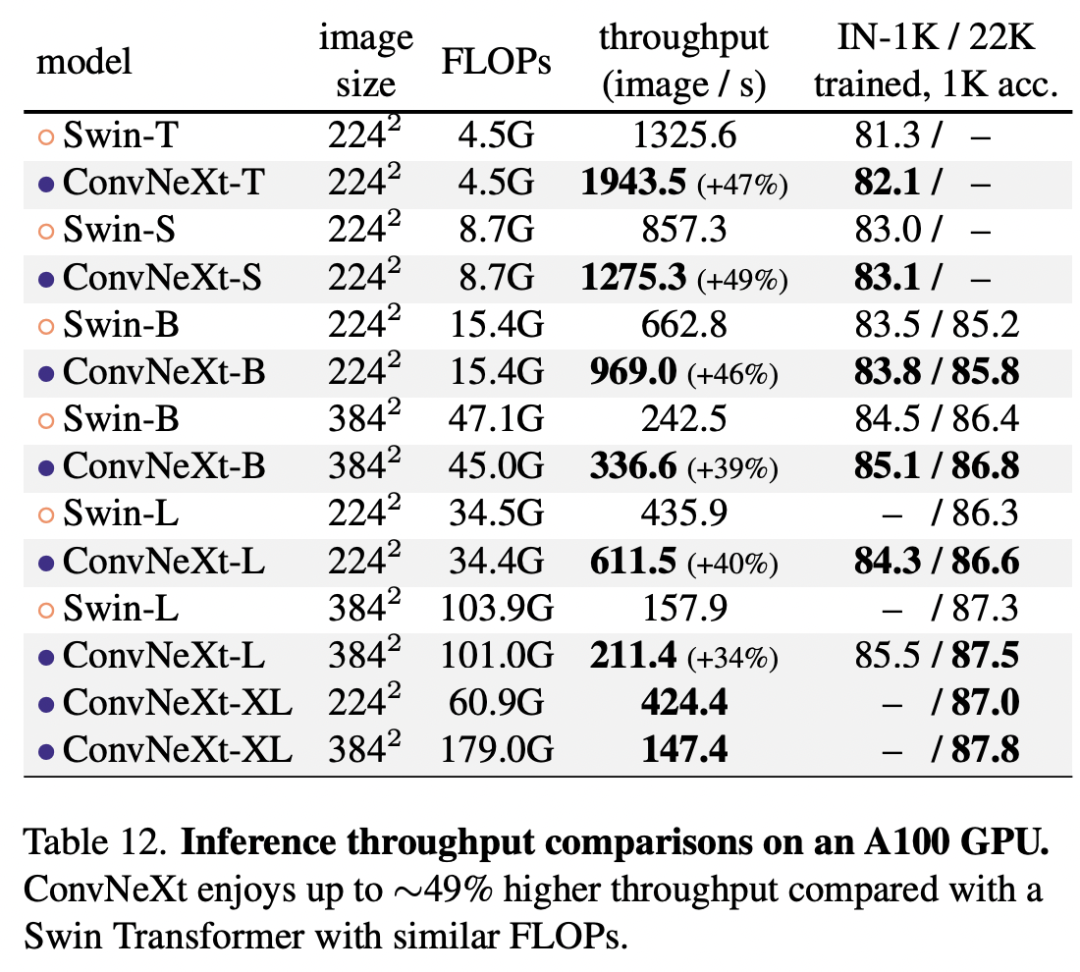 在鲁棒性方面,ConvNeXt也优于Swin,这说明ConvNeXt有很好的泛化。
在鲁棒性方面,ConvNeXt也优于Swin,这说明ConvNeXt有很好的泛化。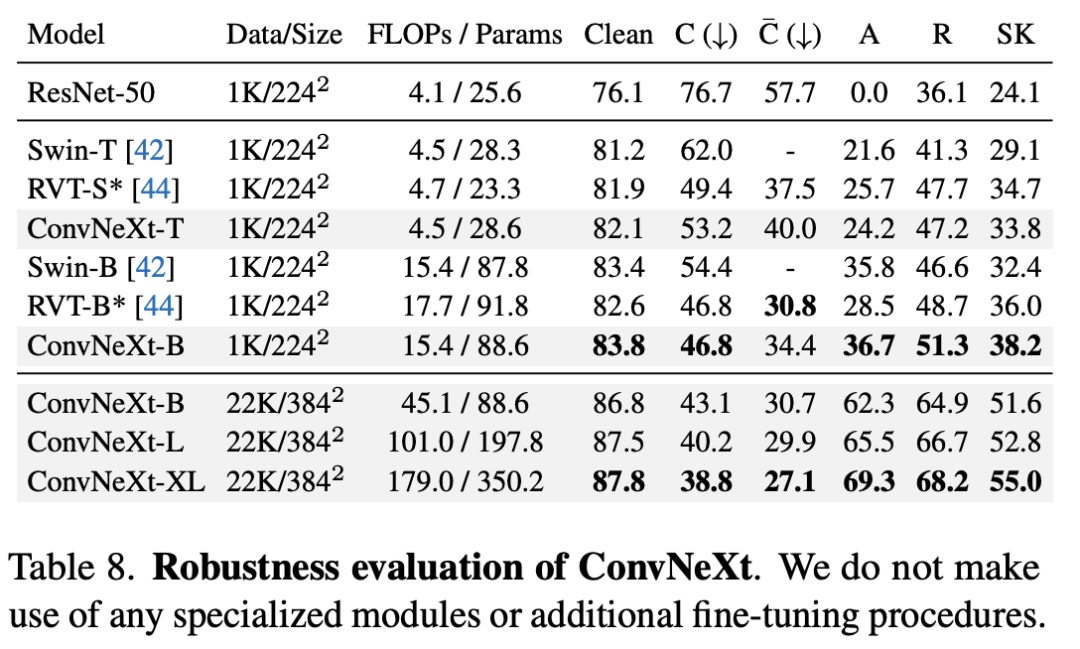 ConvNeXt的实现也比较简单,目前已经开源在https://github.com/facebookresearch/ConvNeXt,这里贴出Block的实现,如下所示(采用了LayerScale):
ConvNeXt的实现也比较简单,目前已经开源在https://github.com/facebookresearch/ConvNeXt,这里贴出Block的实现,如下所示(采用了LayerScale):
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
Isotropic ConvNeXt
除了金字塔结构的ConvNeXt,论文还设计了和ViT类似的Isotropic ConvNeXt,即采用同质结构的ConvNeXt:首先通过一个patch embedding layer得到patch embedding,然后送入参数一样的blocks。从效果上,Isotropic ConvNeXt和ViT效果基本一致,这也许说明dw conv也是能匹敌global attention的。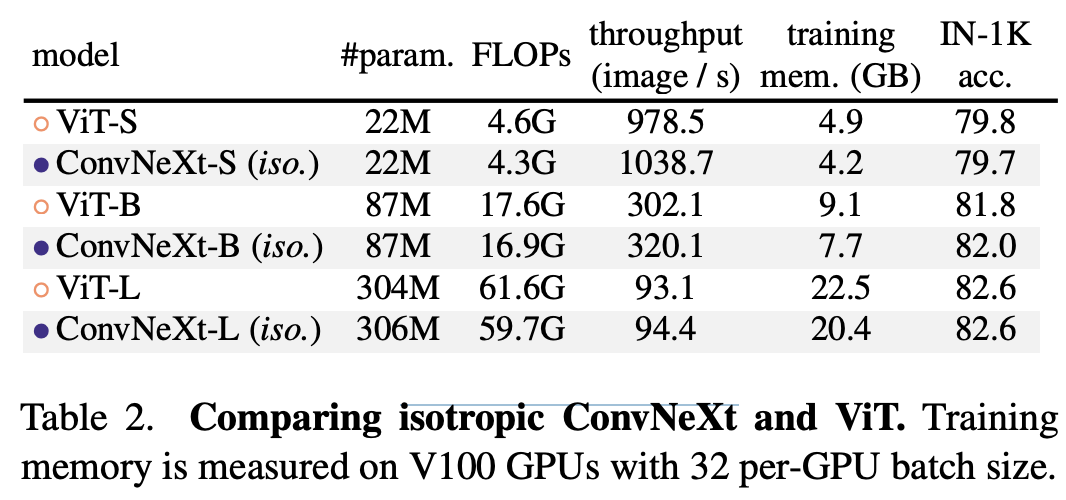 不过这个效果比MetaAI的另外一篇工作PatchConvNet(https://arxiv.org/abs/2112.13692)差一些,存在两个区别:patch embedding (linear projection vs conv stem);同样的FLOPs下,用7x7卷积网络更浅,而用3x3卷积网络更深。相比金字塔结构,同质结构更简单,我个人觉得这也是未来的发展趋势,具体见之前的文章CNN迎来了新的变革:isotropic architecture。
不过这个效果比MetaAI的另外一篇工作PatchConvNet(https://arxiv.org/abs/2112.13692)差一些,存在两个区别:patch embedding (linear projection vs conv stem);同样的FLOPs下,用7x7卷积网络更浅,而用3x3卷积网络更深。相比金字塔结构,同质结构更简单,我个人觉得这也是未来的发展趋势,具体见之前的文章CNN迎来了新的变革:isotropic architecture。
小结
从创新上看,ConvNeXt并没有太多的新意,看起来就是把vision transformer一些优化搬到了CNN上,而且之前也有很多类似的工作,但我认为ConvNeXt是一个很好的工作,因为做了比较全面的实现,而且ConvNeXt在工业部署上更有价值,因为swin transformer的实现太过tricky。从CNN到vision transformer再到CNN,还包括中间对MLP的探索,或许我们越来越能得出结论:架构没有优劣之分,在同样的FLOPs下,不同的模型的性能是接近的。但在实际任务上,受限于各种条件,我们可能看到不同模型上的性能差异,这就需要具体问题具体分析了(算法工程师的价值)。
ConvNeXt的detectron2版本:https://github.com/xiaohu2015/nndet2。
参考
A ConvNet for the 2020s https://github.com/facebookresearch/ConvNeXt When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight What Makes for Hierarchical Vision Transformer?
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
