
Transformer在语义分割上的应用
作者:晟沚
语义分割方法主要采用具有编码器-解码器体系结构的全卷积网络(FCN)。编码器逐渐降低空间分辨率,并通过更大的感受野学习更多的抽象/语义视觉概念。由于上下文建模对于分割至关重要,因此,最新的工作集中在通过以扩张/空洞卷积或插入注意模块来增加感受野。但是,基于编码器/解码器的FCN体系结构保持不变。在本文介绍的文章中,作者旨在通过将语义分割视为序列到序列的预测任务来提供替代。具体而言,作者部署了一个纯transformer(即不使用卷积和不存在分辨率降低的情况)来对图像按patch的顺序进行编码。借助在transformer的每层中建模的全局上下文,可以将此编码器与简单的解码器组合起来,以提供功能强大的分割模型,称为SEgmentation TRANSformer(SETR)。
论文地址:https://arxiv.org/abs/2012.15840
01
网络结构
网络首先将图像分解为一个个固定大小的patches网格,形成一个patches序列。通过将每个patch的像素向量输入到线性embedding层,得到一系列特征嵌入向量作为transformer的输入。给定从编码器transformer学习到的特征,然后使用解码器恢复原始图像的分辨率。关键的是,在空间分辨率上没有下采样,而是在编码器转换器的每一层进行全局上下文建模,也就是完全用注意力机制来实现了Encoder的功能,从而为语义分割问题提供了一个全新的视角。
作者提出的模型实质上是一个ViT+Decoder结构,如下图,其中 VIT论文链接如下,感兴趣的可以去看这篇 https://arxiv.org/abs/2010.11929
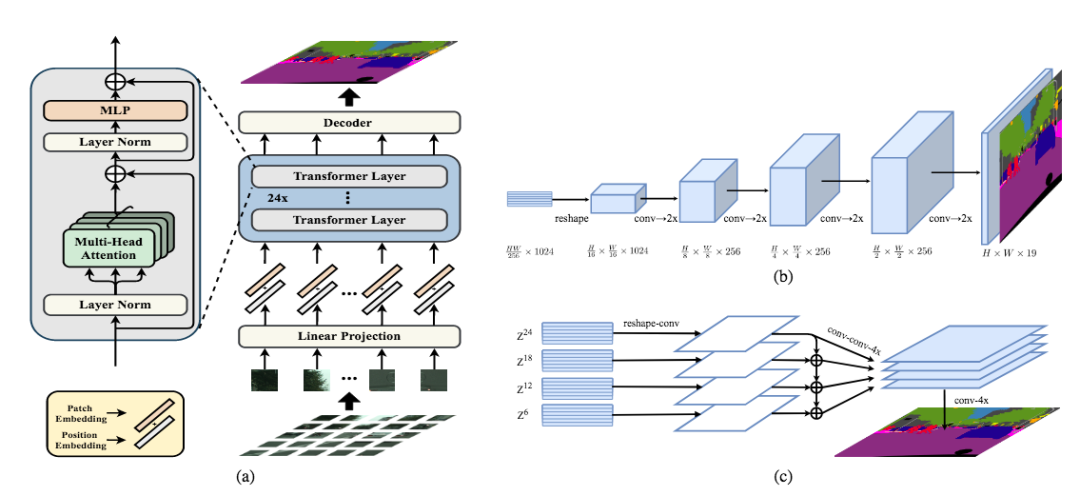
首先是输入图像需要处理为序列,如果按照pixel-wise来处理图像计算量会很大,所以作者采用patch-wise的进行flatten, 将H*W*3的图像序列化为 256个H/16*W/16*3的patch。这样transformer的输入sequence length就是H/16*W/16 ,向量化后的patch p_i经过Linear Projectionfunction得到向量e_i ,然后得到Transformer层的输入如下:
E = { e1 + p1, e2 + p2, ..., e_L + p_L }
其中,e_i是patch embedding, p_i是position embedding。
然后序列化后的图像输入到Transformer中,如下图所示
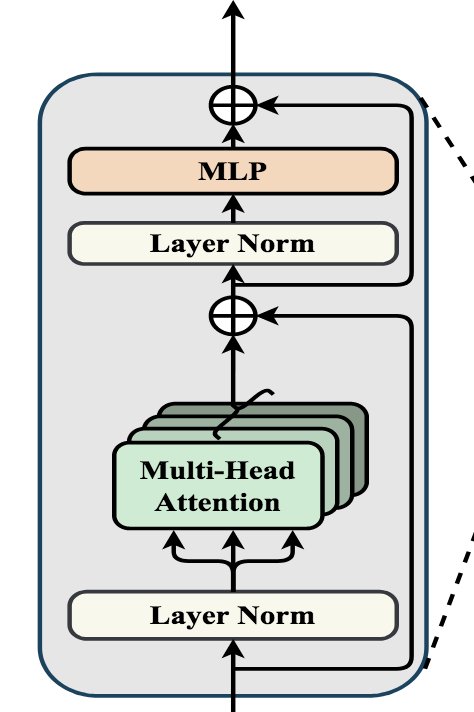
每个Transformer层由多头注意力、LN层、MLP层构成。其输出结果即{Z1,Z2,Z3…ZLe}将上一步得到的E输入到24个串联的transformer中,即每个transformer的感受野是整张image。
最后作者提出了三种decoder:
Naive upsampling (Naive)
将Transformer输出的特征维度降到分类类别数后经过双线性上采样恢复原分辨率, 也就是2-layer: 1 × 1 conv + sync batch norm (w/ ReLU) + 1 × 1 conv
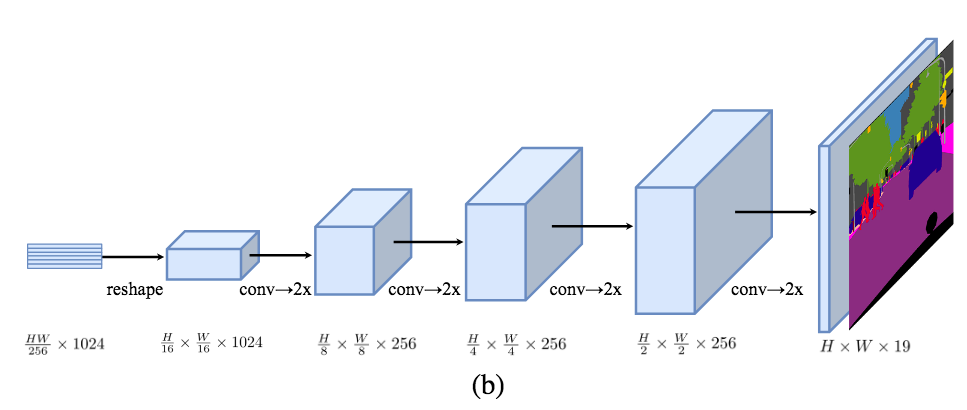
Progressive UPsampling (PUP)
为了从H/16 × W/16 × 1024 恢复到H × W × 19(19是cityscape的类别数) 需要4次操作, 交替使用卷积层和两倍上采样操作来恢复到原分辨率,结构如下图所示
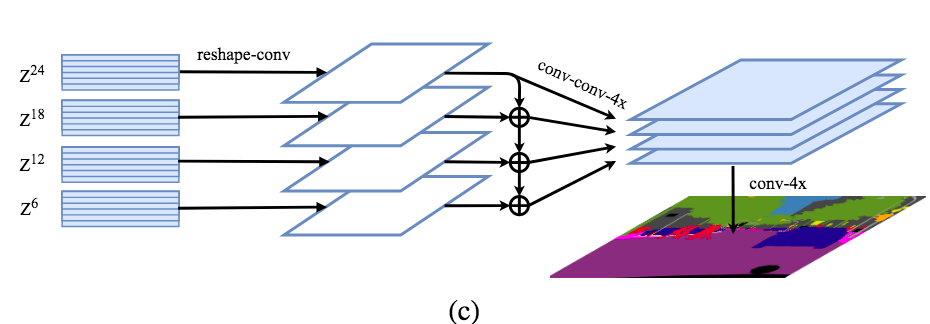
Multi-Level feature Aggregation (MLA)
首先将Transformer的输出{Z1,Z2,Z3…ZLe}均匀分成M等份,每份取一个特征向量。如下图, 24个transformer的输出均分成4份,每份取最后一个,即{Z6,Z12,Z18,Z24},后面的Decoder只处理这些取出的向量。
具体是先将ZL 从2D (H × W)/256 × C恢复到3D H/16 × W/16 × C,然后经过3-layer的卷积1 × 1, 3 × 3, and 3 × 3后再经过双线性上采样4×自上而下的融合。以增强Zl 之间的相互联系,如下图最后一个Zl理论上拥有全部上面三个feature的信息,融合,再经过3 × 3卷积后通过双线性插值4× 恢复至原分辨率。
02
实验结果
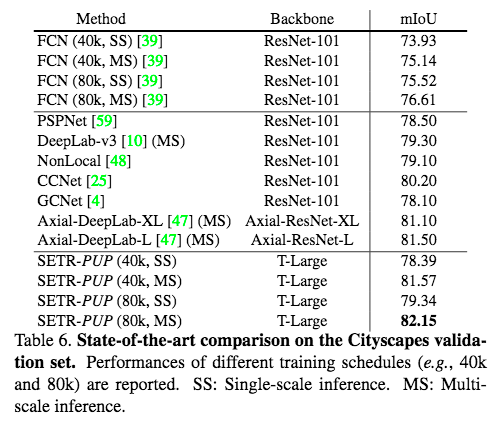
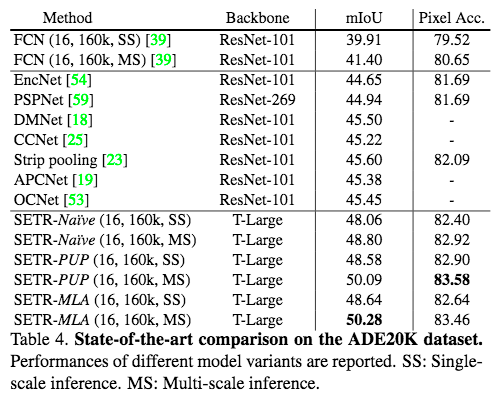
模型在Cityscapes、ADE20K和PASCAL Context三个数据集上进行了实验,实验结果优于用传统FCN(with & without attention module)抽特征的方法, 在ADE20k数据集上和FCN对比可视化如下图:

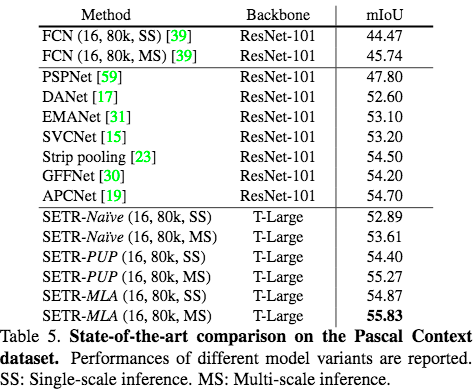
在Pascal Context数据集下和FCN对比可视化结果如下:

在三个数据集上结果如下表:

END
机器学习算法工程师
一个用心的公众号
