
华为零售商品识别一等奖方案

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
商品识别在零售行业的应用
一、图像识别的应用场景,以及对零售行业的变革
1.以图搜图,拍照购物
说到图像识别,大家可能马上能想到以图搜图的方式,也就是“拍照购”。这个想法出现的很早,在零几年的时候就有很多公司开始做这方面的尝试。
美国硅谷的snaptell,他们早在零六年的时候就开始做拍照购物的应用场景,他们做的大部分是一些书籍和CD类的简单物品识别,2009年被Amazon收购。2015年Amazon收购了另一家做图像识别相关的华人公司Orbeus。到2016年后,像Google、Pinterest、Instagram,都开发了一些类似的功能。
国内,淘宝是比较早开始涉及这个领域的。2014年,淘宝自己开始研发了拍立淘的功能,而另一家电商巨头——京东,在2017年上线的“拍照购”采用的是海深科技的算法。同时海深科技还服务了小红书、搜狗图像搜索等一些一线的互联网企业。
2.货架排面管理
货架排面管理的需求主要来自品牌方,以前会有巡店的业务需求。比如商品摆到货架上,需要知道占了多大的排面,是不是整齐摆放,以前是派员工巡店,后来是通过拍照的方式。现在出现了很多众包公司,专门帮助品牌方拍摄门店的照片。
照片收到后如何处理是一个问题,如果以人力来处理这些照片效率很低,无法及时反馈,所以在这样的场景下,商品识别技术有很大的应用需求。众包公司负责拍照的人差异很大,拍照的方式、用的相机、照片的像素都不一样,回传图片后审核,可能一周后发现有不符合要求的门店,需要再次跑到店里去解决。如果能在拍照后,实时通过图像识别知道这个结果,对众包的人员来说,是非常高效和节省成本的方式。

这个领域有一家公司叫TRAX,他们用的是一个机器人来巡店,这是一家目前有一定规模的公司,总部在新加坡,核心研发人员是以色列的,与以色列的几个学校在联合做这个项目。国内目前也有一些同行在做类似的自动货架拍摄的相关项目。
3.无人超市
说到无人超市,Amazon Go是近几年都很火的。当然,Amazon Go用到的核心技术不止是图像识别,更不止于商品识别。他们采取了很多手段,包括他们称之为smart shelf,是采用了重力感应技术,也有红外技术,顶部是摄像头用来跟拍店里的用户,也做了很多Re-ID的工作。
Amazon Go的方案成本非常高,核心难点是人与货的关联。图像识别的一个核心技术就是Re-ID——人的跟踪,他们用了一些像红外技术这样的辅助手段来探测手的位置,用重量感应来判断商品是否被拿起来,然后后摄像头来跟踪人的位置。
我们也在研发类似的技术,目前在与百联合作尝试落地,但总体还是一个计算量非常大而且成本很高的项目。但是Amazon Go具体核心算法是怎么做的,我们也只能是一些猜测,他们做了这么长时间,很多技术细节都是很值得研究的。Amazon Go是一个开放性的环境,虽然做了很多定制性的优化,但整个店面环境以及与人的交互,实际问题是非常难解决的。
4.无人零售柜
现在出现了一些无人零售柜,跟无人超市相比,是一个更小的单元,环境是更可控的。从应用场景来看,很多人会跟以前传统的贩卖机Vending Machine去比较,其实在我的理解下它是一个新的形态,更像一个小的便利店,但是是一个更灵活的形态,商品的品类和摆放也会更自由,这是跟传统贩卖机最大的区别。

现在无人零售柜的技术实现有静态图像和动态视觉两种,海深科技采用的是静态的方案,就是在关门之后拍照,跟关门前的图片进行对比,确认用户拿走哪些商品。因为这个方案用的是云端服务,所以成本会比较低。而动态视频无论是线上传输还是本地计算,都会产生更高的成本,而且准确率无法保证。
5.无人结算台
目前我们还在做的另一个设备,是无人结算台。这样的产品也有几家公司在做,我们的不同点是,它是一个半封闭的场景,周围的环境影响会更小,在技术实现上会更有优势。目前的深度学习模型的泛化能力还是比较有限的,我们会通过一些物理手段,或者其他技术手段来对环境做一些控制,会更有利于技术实现,或者是效率、准确率的提升。

无人结算台的商业化落地还在探索阶段,并且还是会有一些限制。比如说很大的商品,都没有办法放到这个结算台上,当然也没有办法做结算。未来的结算会以什么样的方式,是人工的,还是需要把商品放在一个设备里,还是像Amazon Go这样的完全无感知的结算方式,我们都不知道。当然,从长远来看,Amozon Go的方式肯定是一个方向,但是短期内商业化落地是非常困难的,最大的问题就是过高的成本。
6.线下数字化
在线上,所有的用户信息是数字化的,比如购物时,浏览过什么商品,点击、停留时长、购买等等信息都是有记录的。这方面今日头条号称是做的最好的,给用户的内容推荐相对比较精准。对电商来说,这样的数字化数据可以帮助优化运营策略,是很重要的一个方面。
在线下,用户信息的数字化是很困难的。最早的时候,线下数字化是用探针的方式来做。探针最大的问题就是精度,定位不准确,即使是用两三个点来共同定位,也只能简单定位人的位置,误差还是比较大。
2017年开始,很多公司开始通过视频分析用户的行为,来做线下数字化。有一家海外数一数二的连锁店希望跟我们合作,去做用户路径跟踪、人与物的交互分析。这有点像Amazon Go的技术,但是他们需要做到结算,这样的线下数字化只是做数据分析。
除此之外,线下还有两个很大的需求就是防盗和员工管理。防盗的需求比较清晰,员工管理其实也很重要,比如员工与客户沟通的热情,甚至员工的异常行为等等。
做线下数字化的原因是什么呢?其实无人店的核心不是有人和无人,而是强制的会员制。Costaco为什么这么火爆,他做的最好的就是明确的用户定位+会员制,然后只服务于这个群体。无人店通过强制的会员制,去绘制用户画像,对他进行精准定位,然后可以打通线上和线下,以定制化的服务来优化商品、提高客单价。我觉得这是零售行业的趋势,也是线下数字化的意义。
二、商品识别的技术难点
1.人脸识别难还是商品识别难
首先这个问题不是很科学,任何一个问题都可以变得容易,也可以很难。人脸识别一般是比较配合的,像第一个图,相对来说难度会比较低,现在方案也比较成熟。那如果大街上,下着雨,半遮着脸,距离很远,清晰度很低,这样识别难度就很大了。那如果是看着后脑勺希望把人识别出来,就显然不太合理。

商品识别也是类似,一个商品摆在面前来区分是比较容易的,但实际的场景中就会很困难。比如第二张图的排面,这还是我们做过的项目里相对容易的,因为摆的很整齐。第三张图的难度就很大了,这是一个非常极端的例子。农夫山泉和可乐都是红色的盖子,饮料的颜色是不同的,但左下角只露出了一个盖子,就非常难识别了。所以人脸识别和商品识别哪个更难这个问题,需要从不同的角度来看待。
2.准确率 = 70%*数据+30%*算法
提升识别准确率,核心是两个部分,数据和算法。我们都非常关注的算法层面,可能只占30%的比例,数据可能要占70%。
3.目标检测往往是更难的
目标检测其实比识别更难,大部分的时间我们花在做目标检测上。零售行业的排面检测相对要求还不会特别高,多一个小一个框不会构成大的问题。但比如像我们智能柜的场景,商品识别是用来做结算的,要求100%准确,特别是密集摆放的情况下,难度就很高。
实际的场景中除了密集摆放,还会有倾倒重叠的情况出现。像下图中的重叠,我们目前能够识别,但如果出现一个商品比较长,另一个商品完全覆盖把商品截成两段,人可以通过联想知道是同一个商品,但是机器会识别为两个商品。

再比如说商店的排面,上图左上角的牛奶只露出了不到1/20,商品识别很可能会出错,所以这不能只依靠商品识别来做。人会通过推理来判别,那么商品识别中也许可以增加近似的技术手段来优化整个方案。
4.物体的重识别Re-ID
一般物体的识别,我们更多的解决的是一个摄像头下的商品识别,还有一个常见但更复杂的场景,就是在更大的区域下,可能需要两个摄像头协同拍摄,每张图分别拍到一部分,两张图还有重合的部分。如何在这样的情况下精准地识别,我们团队去年花了整整一年的时间,解决了这个问题。

很多人马上想到的是把两张图进行拼接,但实际拼不起来,商品有高有矮,两张图也是不同的角度。实际要如何解决呢?其实跟人的推理方法是一样的。首先我们比较确定的是一些边缘的信息,比如两张图分别有哪些靠近边缘,找到一些关键点,也就是说,哪些商品在两张图里是同一个。简单地说,人是如何理解这两个画面,那么让算法也近似地去理解。
三、智能零售解决方案工程化落地关键
1.数据标注的优化
之前也提到,数据的重要程度非常高,如何提升数据质量,采集、标注数据策略的优化,在什么场景下做采集,都是非常重要的方面。而后期,当数据达到一定量的时候,如何实现数据工程化高效采集,也成为需要考虑的方面。
数据的采集没有捷径,高质量的数据一定需要花费很多时间。同时,优质的数据采集和标注平台,也是非常重要的。一个优质的数据平台的开发,本身就可以成为一个独立的产品。
我们也尝试过3D建模,成本相抵会更低,可以迅速把准确率提升到90%,甚至95%以上,但是要达到99%以上接近100%的水平,3D建模是不够的,还是需要采集更多有效的数据。
2.场景限定与优化
现在深度学习的能力其实还是有限,泛化能力还比较弱,只针对一些限定的场景会有比较好的结果。就像之前我们提到两个例子,一个是Amazon Go,一个是我们的智能柜,整体的环境还是定制化的。比如外界的灯光、阳光造成的光线差异,摄像头的更换导致的色差,都会是影响结果的原因。
因而目前的商业落地,场景的限定与优化是比较重要的,在深度学习还没有达到一定强度的时候,外界的辅助手段可能是提升效果的重要辅助方式,场景、算法、应用、硬件都需要协同配合。
3.数据共享
图像识别能有今天的发展,很大程度上受益于李飞飞教授主持的ImageNet大量标注图片数据集,可以说是现在所有图像识别最根本的基础。
同样的道理,由于商品种类的繁多性,靠一个公司或者团体的能力,很难提升算法的泛化能力,也就是单一算法只能适用于非常有限的场景,很难形成规模化效应。其实我们这个行业也是类似,在数据层面其实可以合作共赢的方式来推进整个行业的良性发展,数据共享和算法开放将会成为人工智能发展的一个重要趋势。
RP2K是品览基于零售商品识别能力发布的零售数据集。不同于一般聚焦新产品的数据集,RP2K收录了超过50万张零售商品货架图片,商品种类超过2000种,该数据集是目前零售类数据集中产品种类数量TOP1,同时所有图片均来自于真实场景下的人工采集,针对每种商品,我们提供了十分详细的注释。
RP2K数据集(https://arxiv.org/pdf/2006.12634.pdf)具有以下特性:
(1) 迄今为止,就产品类别而言,它是规模最大的数据集。
(2) 所有图片均在实体零售店人工拍摄,自然采光,符合实际应用场景。
(3) 为每个对象提供了丰富的注释,包括大小、形状和味道/气味。
全部代码获取方式:
关注微信公众号 datanlp 然后回复 商品识别 即可获取。
数据分析
数据集中的一些样本如下图所示,大部分分布是细长的,长宽分布要比ImageNet等数据集更加分布不均匀:

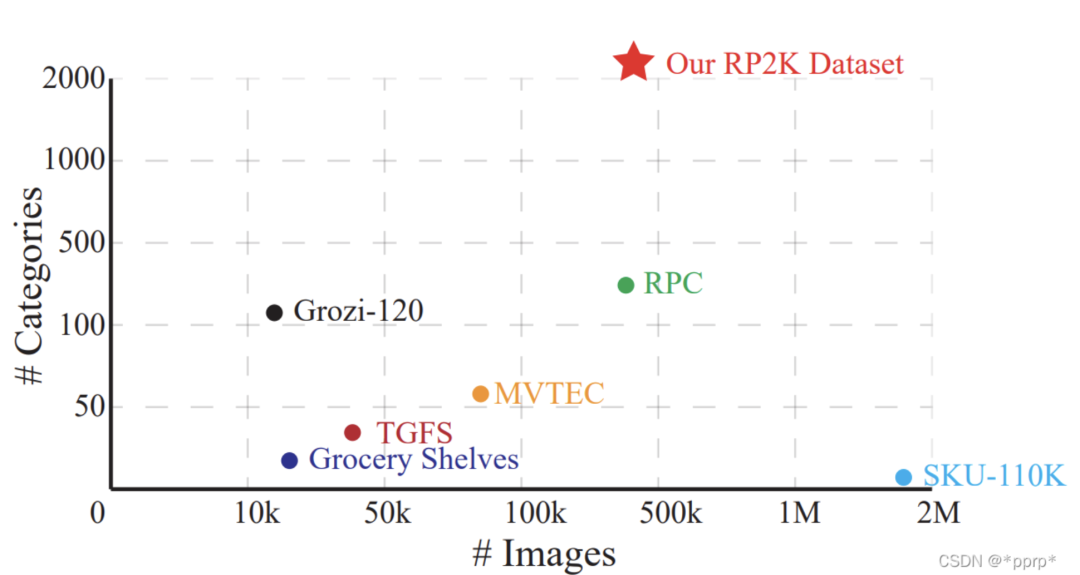
此外,该数据集的数据量和类别数量也非常多,下图展示了RP2K和其他零售数据集的对比,RP2K具有2388个类别的零售商品,属于大规模分类问题。
此外,数据集某一些类间分布差异较小,相同品牌不同子产品之间差异较小,可以归属为细粒度分类问题。数据质量也存在一定的问题,比如光照,包装差异,拍摄角度,标注错误等等问题。

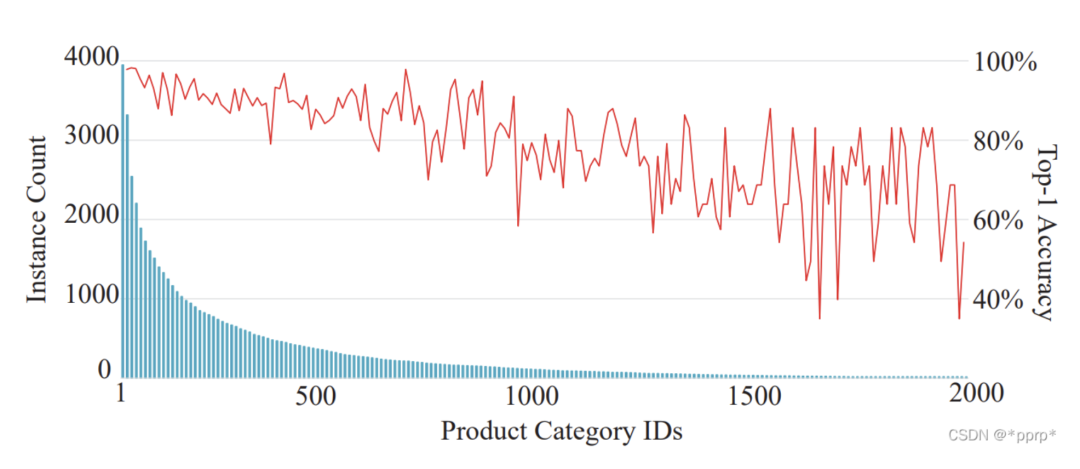
经过统计,该数据集呈现明显的长尾分布:
数据预处理
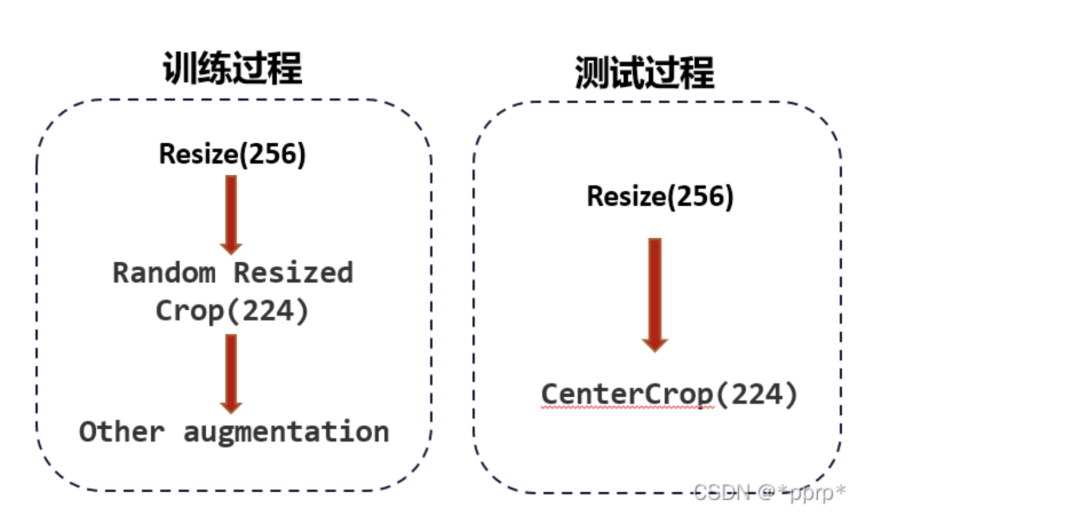
1. Resize策略

2. 数据增强
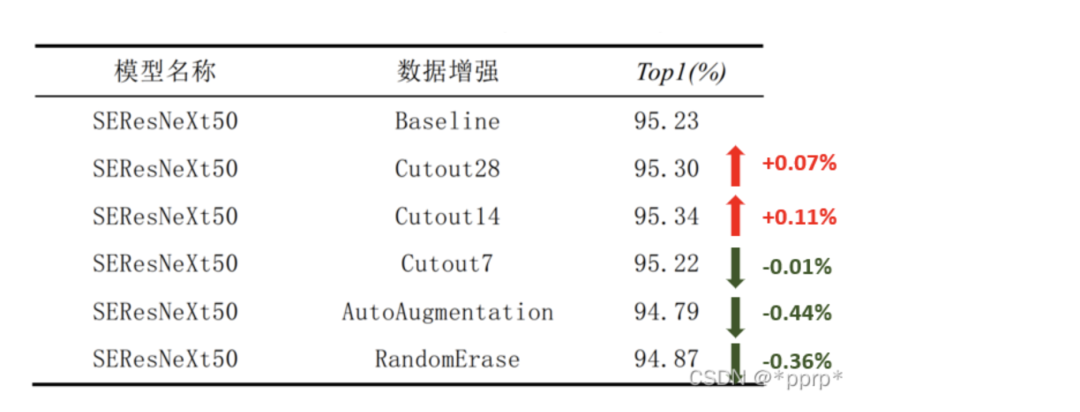
我们测试了三种经典的数据增强方法:
Cutout数据增强策略,在随机位置Crop正方形Patch。
AutoAugmentation策略,使用了针对ImageNet搜索得到的策略。
Random Erasing策略,随机擦除原图中的一个矩形区域,将区域内部像素值替换为随机值。
实验效果如下:
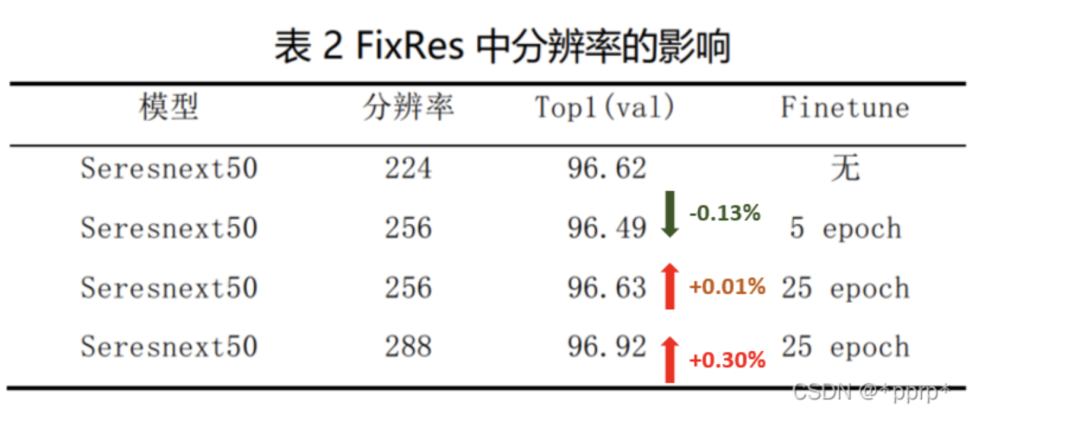
3 后处理方法FixRes
采用了NIPS19年Facebook提出的FixRes的后处理技巧,ImageNet上经典的数据增强方式会导致训练时和测试时的模型看到的目标尺寸出现差异。
之前写过一篇文章解读FixRes详细内容可以看这里:
https://blog.csdn.net/DD_PP_JJ/article/details/121202386?spm=1001.2014.3001.5501
简单来说是由于ImageNet经典的数据处理方法会导致Region of Classification,即模型看到的目标尺寸不同。
可以看到,下图中通过训练和测试过程得到的“7喜”的logo标志大小存在差异,为了弥补两者差异,最简单的方式是提高测试过程中分辨率。

模型改进
1 模型选择

我们最终选择了SEResNeXt50作为主要模型,并配合ResNet50_CBAM还有Inception_resNet_v2进行模型集成。Swin Transformer和EfficientNet两个模型由于其运行速度太慢,在比赛时间限制下没有使用两者。
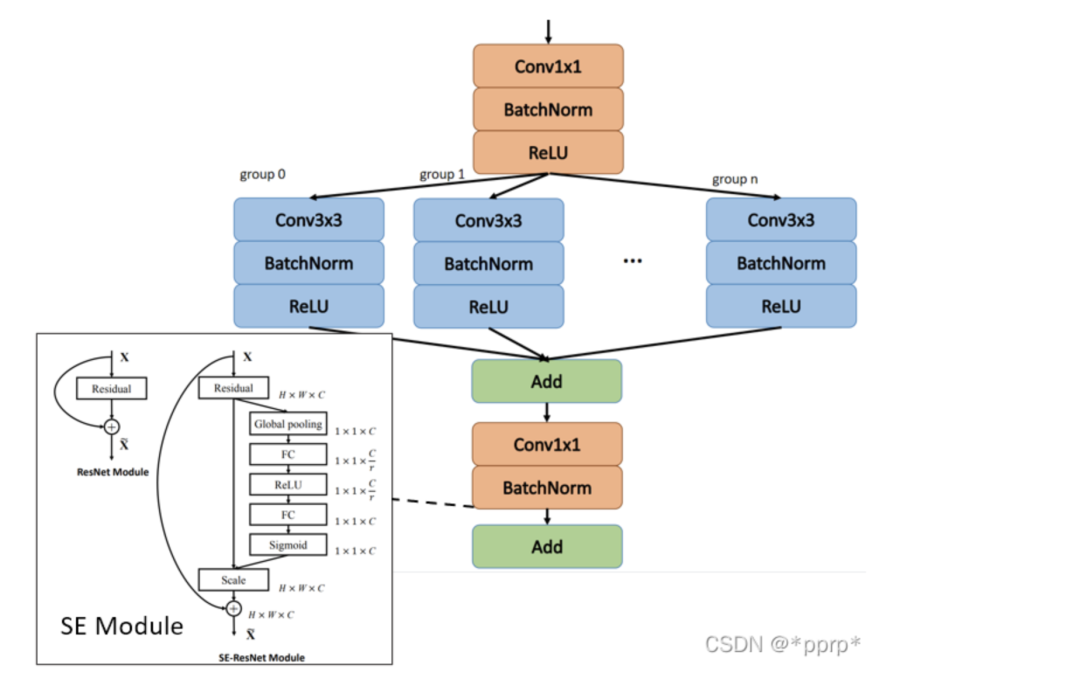
SEResNeXt模型有两部分构成
ResNeXt在ResNet基础上引入了基数, 通过引入组卷积让模型能够学到更diverse的表示。
Squeeze & Excitation Module让模型能够自适应地调整各个通道的重要程度,学习到了通道之间的相关性,提升模型表达能力。
2 模型改进
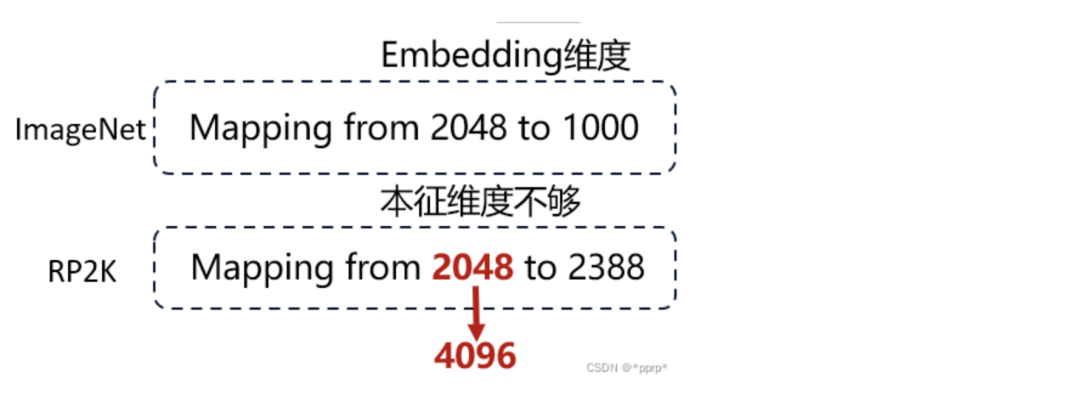
模型改进部分是一个简单而符合直觉的方法,我们观察到,现有的大部分模型都是针对ImageNet进行设计的,而ImageNet类别数为1000个类别,但RP2K数据集规模比较大,拥有2388个类别。

我们关注大多数模型的最后一个linear层的设计,针对ImageNet设计的模型的Linear层通常由2048维度映射到1000维度,由高纬度映射到低纬度比较合理。
但是由于RP2K的规模较大,类别数量为2388,直接由2048映射至2388可能会导致容量不够的问题,由低纬度映射映射至高纬度则不太符合直觉。
针对此,我们进行了简单而符合直觉的改进,如下图所示:
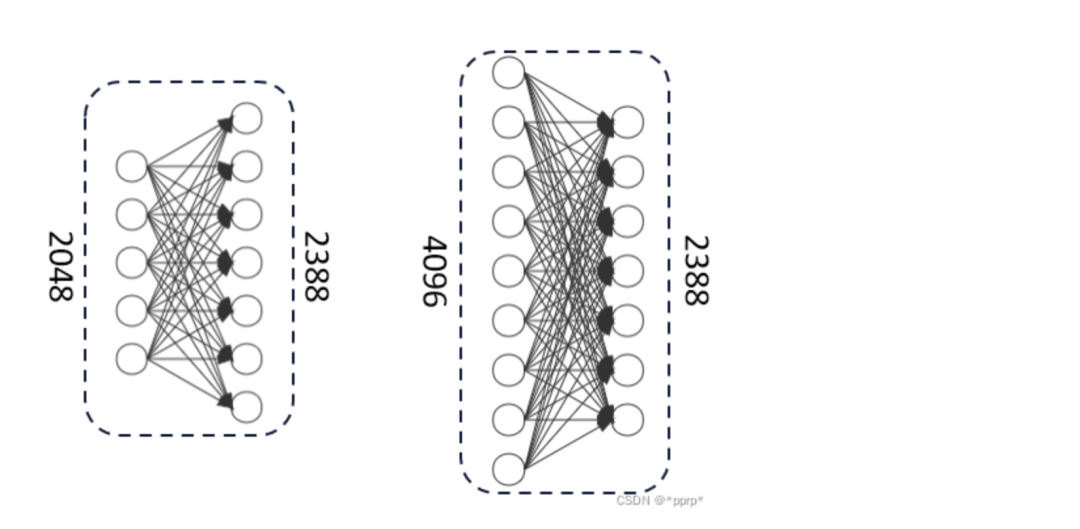
通过以上改进,扩充了模型的容量,取得了0.26%的提升。
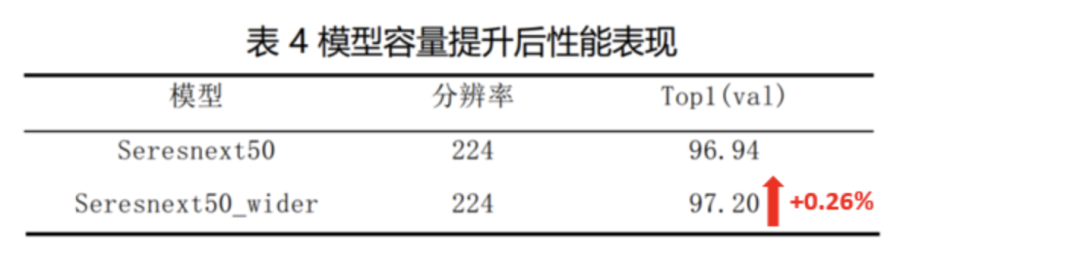
3. 模型训练细节

错例分析
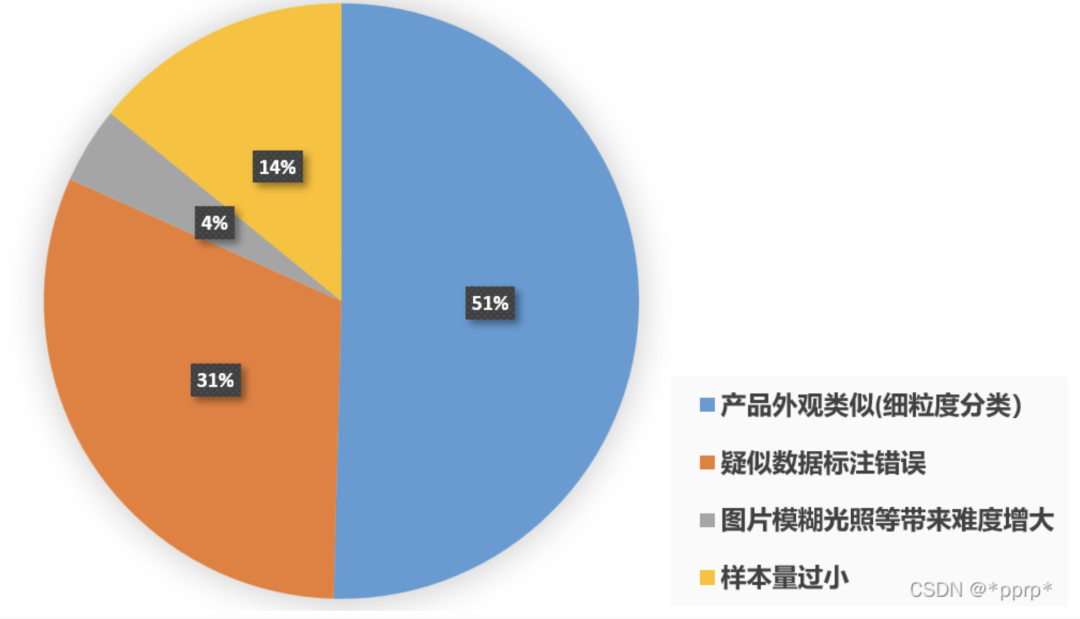
手工分析了一下错误样例(注:以上分析去除了others类别错分样本),可以发现这个数据集比较难处理的是细粒度带来的识别困难、疑似数据标注错误、以及长尾分布的尾部类别,这也符合我们数据分析的结论。
MindSpore框架使用感受
本次比赛面向国产AI框架,基于MindSpore开发商品识别算法,必须在昇腾910平台训练和部署模型,以官方复现结果为准。
使用MindSpore的感受:


最后对MindSpore感兴趣的小伙伴可以使用以下的参考资料快速上手:
MindSpore 安装问题:https://www.mindspore.cn/install
最直接的学习资料,官方教程: https://www.mindspore.cn/tutorials/zh-CN/r1.5/index.html
最简单的分类例程:
https://www.mindspore.cn/docs/programming_guide/zh-CN/master/quick_start/quick_video.html
可白嫖的模型模型库:https://gitee.com/mindspore/models
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx